作者 | Jasmeet Bhatia
编译 | KK4SBB
本文将对目前流行的几种Keras支持的深度学习框架性能做一次综述性对比,包括Tensorflow、CNTK、MXNet和Theano。作者Jasmeet Bhatia是微软的数据与人工智能架构师,本文内容仅代表个人观点。
如果现在有人质疑Keras在数据科学家和工程师社区的地位,那么就先请他去看看专业AI和云计算玩家对Keras的支持率吧。官方发布的最新版Keras,除了支持Theano等通用库之外,已经可以支持谷歌的Tensorflow和微软的CNTK深度学习库。去年,亚马逊云宣布他们的系统支持另一款强大的工具MXNet。

就在前几周,新一版的MXNet也兼容Keras。不过,截止目前MXNet貌似只支持v1.2.2版本的Keras,对最新版2.0.5的Keras还不支持。
尽管只要产品选用被支持的后端服务,就可以在其中部署Keras模型,但是开发人员和架构师们必须牢记Keras是属于适配不同深度学习框架的高层接口,还不支持任意调整外部库的模型参数。
因此,如果大家想要精细调节后端框架提供的所有参数,作者建议大家直接选用具体的框架,不必再用Keras做一层包装。不过随着时间的推移,Keras的功能必定会逐步完善。但是我们不得不说,目前Keras仍然是深度学习项目早期开发阶段的一个神器,它让数据科学家和工程师们可以快速生成和测试复杂的深度学习模型。
Keras还可以让开发人员快速对比测试几种深度学习框架的相对性能。Keras的配置文件中有一个参数指定了用什么后端框架。所以,大家只要写一份代码,就可以在Tensorflow、CNTK和Theano上都运行一次而无需改动代码。
至于说MXNet,因为它现在只支持v1.2.2版本的Keras,所以要稍微修改代码才能运行。显然,这些独立的框架可以利用开发库中各式各样的特性进一步调试优化,不过Keras为我们提供了一个比较这些框架基础性能的机会。
有不少人写过文章对比Keras支持后端的相对性能,Keras或者后端框架每出一个新版本,我们都能看到性能的巨大改善。
那么让我们看看最新版本的Keras和各个后端框架能达到什么性能。
首先,介绍一下本次实验的硬件配置。
所有的测试都是在装有NVidia Tesla K80 GPU 的Azure NC6 虚拟机上完成的。虚拟机的镜像文件是Azure DSVM (Data Science Virtual Machine)。镜像文件预装了Keras、Tensorflow、Theano、MXNet及其它数据科学工具。为了进行测试实验,所有应用都升级到最新版本,针对MXNet选用v1.2.2版本的Keras。有关Azure DSVM的细节资料可以点击链接
配置
由于每个框架的依赖不同,作者用三种不同的配置进行测试实验,具体如下:


尽管所有框架的开发团队都声称正在研发的新版本性能有所提升,可以用于科研项目,不过实际产品还是倾向于使用稳定版本。因此,本次测试的所有后端框架都使用了最新的稳定版本。
性能测试
为了比较各个框架的性能,作者使用了下面五种深度学习模型。为了保证实验的公平性,所有的模型都来自于Github上Keras项目的示例代码。
作者在自己的Github页面公布了所有的测试代码。
值得注意的是,其中两组测试没有包括MXNet模型。还是由于MXNet不支持最新版Keras的功能,需要改动较多的代码才能运行,所以排除在本次实验之外。其它三组实验只需少许改动代码即可支持MXNet,主要改动在于函数的命名不同。
实验1:CIFAR10 CNN
模型类型:卷计算机网络
数据集/任务名称: CIFAR10 图像数据集
目标:将图片分到10个类别
就完成每个epoch速度而言,Tensorflow略胜MXNet一筹。就准确率/收敛速度而言,CNTK在第25轮迭代之时略微领先,不过第50轮迭代之后所有框架的准确率几乎趋同。
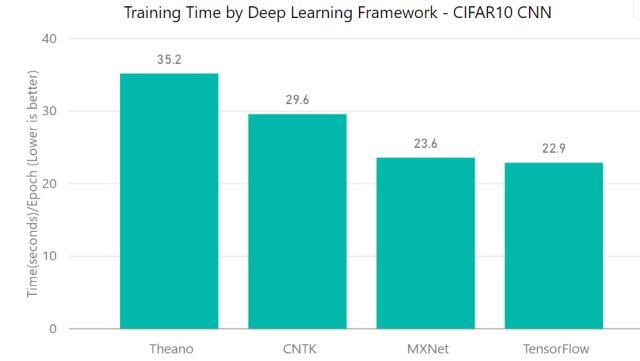

不同框架的性能比较图
实验2:MNIST CNN
模型类型:卷计算机网络
数据集/任务名称:MNIST手写数字数据集
目标:识别照片中的手写数字
在本组实验中,Tensorflow的训练速度略快于Theano,远好于CNTK,不过各个框架的准确率和收敛速度不分伯仲。


实验3:MNIST MLP
模型类型:多层感知机/神经网络
数据集/任务名称:MNIST手写数字数据集
目标:识别照片中的手写数字
本实验还是在MNIST数据集上测试标准的深度神经网络模型,CNTK、Tensorflow和Theano的速度大致相同(2.5-2.7s/epoch),而MXNet独树一帜,达到了1.4s/epoch的速度。MXNet在准确率和收敛速度方面也表现略好。


实验4:MNIST RNN
模型类型:层次循环神经网络
数据集/任务名称:MNIST手写数字数据集
目标:识别照片中的手写数字
在这组实验中,CNTK和MXNet的训练速度比较接近(162-164s/epoch),Tensorflow比它们稍慢,只有179s/epoch。Theano在RNN模型上的表现相当糟糕。


实验5:BABI RNN
模型类型:循环神经网络
数据集/任务名称:bAbi项目
目标:基于描述和问题训练两个循环神经网络模型。生成的向量用来回答一系列bAbi任务。
MXNet没有参与本组实验。Tensorflow和Theano的性能差不多,CNTK比它们快了50%,只需9.5s/epoch。

结论

各组实验中,不同框架的性能对比
Tensorflow在各组CNN模型的实验中都表现出色,但是在RNN模型上表现一般。
CNTK在 BAbi RNN 和 MNIST RNN 实验中的表现远远好于Tensorflow和Theano,但是在CNN实验中不及Tensorflow。
MXNet在RNN测试中的表现略好于CNTK和Tensorflow,在MLP实验中性能碾压其它所有框架。但是受限于v2版Keras的功能,无法参与另外两组对比实验,不过这种情况马上会得到解决。
Theano在MLP实验中的性能略好于Tensorflow和CNTK。
总结
从实验结果来看,所有框架都有各自擅长的领域,目前并没有哪一种框架能够全面碾压其它产品。不过,开源社区的参与者们仍旧在持续开发和维护这几款产品,不断提升它们的性能和扩大它们的功能,使得用户的使用和部署过程更方便。不过,性能只是深度学习模型的一个方面,用户在实际使用时还要兼顾效果、便捷性等多个因素。
原文 :Search fastest Keras Deep Learning backend