上一篇文章讲到了神经网络分类边界的一些问题。这次再来探讨一下,对于非线性数据,神经网络的分类边界能够达到什么效果。已证明:只需一个包含足够多神经元的隐层,多层前馈网络就能以任意精度逼近任意复杂度的连续函数。
为了便于画出分类边界,这里采用Feature只有2维的二分类数据。简单起见,就采用sinx来随机生成数据好了。[微笑]
用sinx随机生成500个数据,根据数据在曲线的两端将其分成两个类别,数据分布图如下:
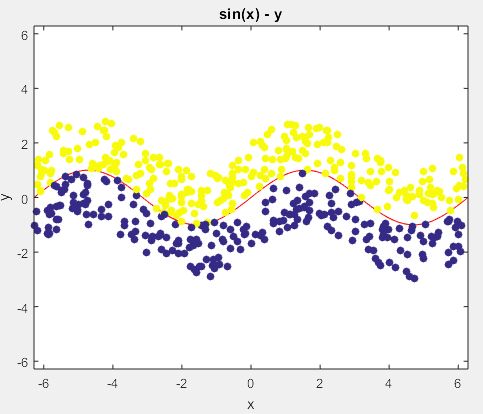
用sinx随机生成500个数据
注意:图中红色的线是真实的曲线
 $$)
【吐槽一下,这个markdown编辑器里面怎么在文本中插入短公式 [忧桑] 】
仍然采用TensorFlow来实现一个简单的3层神经网络,将隐藏结点个数设置为20,随着网络参数的更新分类边界的变化如下:

第10000轮

第30000轮

第50000轮
随着迭代次数的增加,曲线的拟合越来越接近真实边界。
将隐藏层个数设置为500,第50000轮的结果如下:

第50000轮
似乎跟上面的图没有太大的区别。然而,太复杂的结构可能就会引起over-fitting等问题,而且上面隐层结点个数从20变到500后,训练时间明显有所增加。相同的配置下迭代50000次,2个隐层结点耗时26秒,20个隐层结点耗时32秒,而500个隐层结点耗时250秒。
TensorFlow训练code
import numpy as np
import tensorflow as tf
# Parameters
learning_rate = 0.1
batch_size = 100
display_step = 1
#model_path = "/home/lei/TensorFlow-Examples-master/examples/4_Utils/model.ckpt"
# Network Parameters
n_hidden_1 = 500 # 1st layer number of features
n_input = 2 # MNIST data input (img shape: 28*28)
n_classes = 2 # MNIST total classes (0-9 digits)
# tf Graph input
xs = tf.placeholder("float", [None, n_input])
ys = tf.placeholder("float", [None, n_classes])
# Create model
def multilayer_perceptron(x, weights, biases):
# Hidden layer with RELU activation
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.sigmoid(layer_1)
# Output layer with linear activation
out_layer = tf.add(tf.matmul(layer_1, weights['out']), biases['out'])
out_layer = tf.sigmoid(out_layer)
return out_layer
# Store layers weight & bias
weights = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'out': tf.Variable(tf.random_normal([n_hidden_1, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
# Construct model
prediction = multilayer_perceptron(xs, weights, biases)
# x_data = np.array([[0,0],[1,0],[1,1],[0,2],[2,2]])
# y_data = np.array([[1, 0],[0, 1],[0, 1],[0, 1],[0,1]])
x_data=np.loadtxt('data-sinx-x.txt')
y_data=np.loadtxt('data-sinx-y.txt')
# x_data = np.linspace(-1,1,300)[:, np.newaxis]
# noise = np.random.normal(0, 0.05, x_data.shape)
# y_data = np.square(x_data) - 0.5 + noise
# 4.定义 loss 表达式
# the error between prediciton and real data
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
# 5.选择 optimizer 使 loss 达到最小
# 这一行定义了用什么方式去减少 loss,学习率是 0.1
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(loss)
# important step 对所有变量进行初始化
# init = tf.initialize_all_variables()
init = tf.global_variables_initializer()
sess = tf.Session()
# 上面定义的都没有运算,直到 sess.run 才会开始运算
sess.run(init)
# 迭代 1000 次学习,sess.run optimizer
N = 50000
for i in range(N):
# training train_step 和 loss 都是由 placeholder 定义的运算,所以这里要用 feed 传入参数
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 10000 == 0:
print(i)
#print(sess.run(loss, feed_dict={xs: x_data, ys: y_data}))
#print(sess.run(weights), sess.run(biases))
w = sess.run(weights)
b = sess.run(biases)
w1 = np.transpose(w['h1'])
b1 = b['b1']
w2 = np.transpose(w['out'])
b2 = b['out']
np.savetxt("w1_"+ str(i) + ".txt", w1)
np.savetxt("b1_"+ str(i) + ".txt", b1)
np.savetxt("w2_"+ str(i) + ".txt", w2)
np.savetxt("b2_"+ str(i) + ".txt", b2)
w = sess.run(weights)
b = sess.run(biases)
w1 = np.transpose(w['h1'])
b1 = b['b1']
w2 = np.transpose(w['out'])
b2 = b['out']
np.savetxt("w1_"+ str(N) + ".txt", w1)
np.savetxt("b1_"+ str(N) + ".txt", b1)
np.savetxt("w2_"+ str(N) + ".txt", w2)
np.savetxt("b2_"+ str(N) + ".txt", b2)
MATLAB画图code
function sinxborder()
load data-sinx.txt
a = data_sinx(:,1);
b = data_sinx(:,2);
c = data_sinx(:,3);
% syms x y
% h = ezplot('sin(x)-y');
% set(h,'Color','red')
ezplot(nn(50000));
hold on
scatter(a,b,'filled', 'cdata', c);
end
function eq = nn(i)
syms x y
X = [x; y];
W1 = load(['data/w1_', num2str(i), '.txt']);
b1 = load(['data/b1_', num2str(i), '.txt']);
W2 = load(['data/w2_', num2str(i), '.txt']);
b2 = load(['data/b2_', num2str(i), '.txt']);
Ksi = sigmoid(W1*X + b1);
% O = sigmoid(W2*Ksi + b2);
O = W2*Ksi + b2;
eq = O(1,1) - O(2,1);
end
function A = sigmoid(x)
A = 1./(1+exp(-x));
end