本篇主要面向于对Python爬虫感兴趣的零基础的同学,实例为下载煎蛋网中指定页面的妹子图。好了,话不多说,让我们开始吧!
为什么选取这个网站? 1.妹子 2.这个网站比较好爬取,适合入门
所需工具
1.Python3.x
2.Pycharm
3.Chrome浏览器
以上的安装方法在此就不提了,但是需要注意的是要把Python添加到路径中(此处为了方便引用了廖雪峰老师的图例)

创建文件以及库的导入和安装
各个软件安装调试完成后我们就开始着手我们的小项目。
1.打开Pycharm并且创建项目
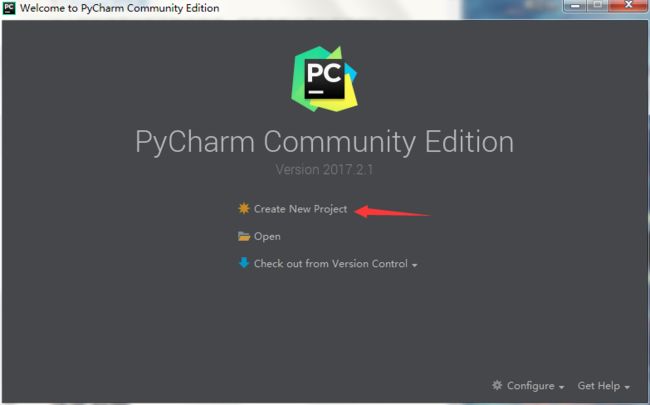


(上面创建的项目是文件夹,这里右键你创建的文件夹,按照图中实例即可创建相应文件)
假设现在你的Python file(名为'ooxx')已经建好了,代码第一行开始,我们导入所需要的库。
库是干什么的?Python之所以很好用就是因为他有许多自带的库以及第三方库,这些库可以直接提供方法给用户使用,例如导入math库,就可以用来计算平方根;导入time库,就可以计算程序运行时间等等功能。无需我们自己再次重写这些功能(也叫造轮子)

这样就完成了所需库的导入
1.这里是灰色的是因为它们还没有被使用
2.这里有两种导入库的方法,例如第5行是指从bs4库中导入BeautifulSoup方法,这样可以节约空间,因为其他的方法我们都暂时用不着
此外,由于第三方库你并没有安装后续会报错,这里提供一种简单的方法,Pycharm > Setting > 左上角搜索Project Interpreter

检索上述你没有安装的库,点击绿色的+号后,搜索点击安装等待片刻即可.(当然也还有其他的很多安装库的方法,比如pip,Anaconda等)
正式开始
啰嗦了一大堆准备工作,现在正式开始(心虚.....因为后续还会穿插很多小知识点照顾完全零基础的朋友)

按照图中的代码键入,右键 run'ooxx',下方就会显示
来看第8行,等号右边的表示调用requests库的get方法,中间的参数填入我们所要访问的网址(也就是上一步我们所赋值的url),然后将其整体赋予左边的wb_data,打印wb_data,返回状态码200, 可以说只要状态码不是200的都不算正常访问。
例如当网站识别出你为爬虫访问,就会返回404或者其他状态码,那么你就得不到想要的数据。所以这里我们会先介绍一种最初级的隐匿措施,将我们利用Python的访问变得更像浏览器访问。
User - Agent
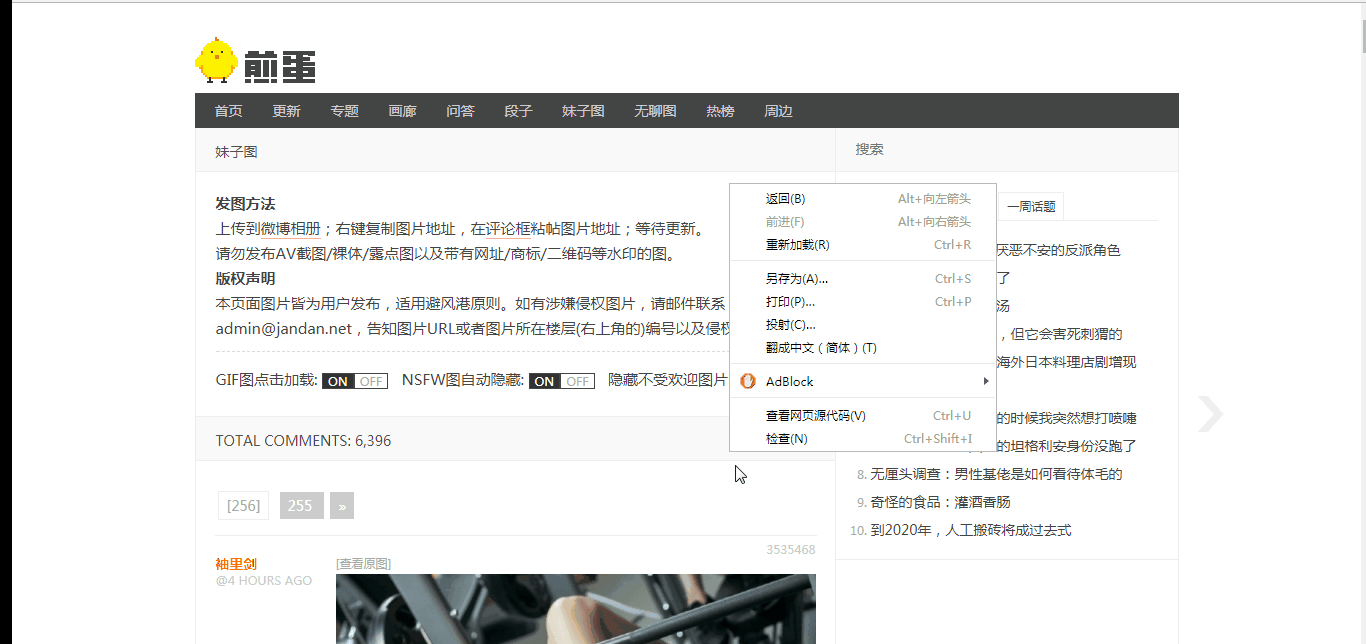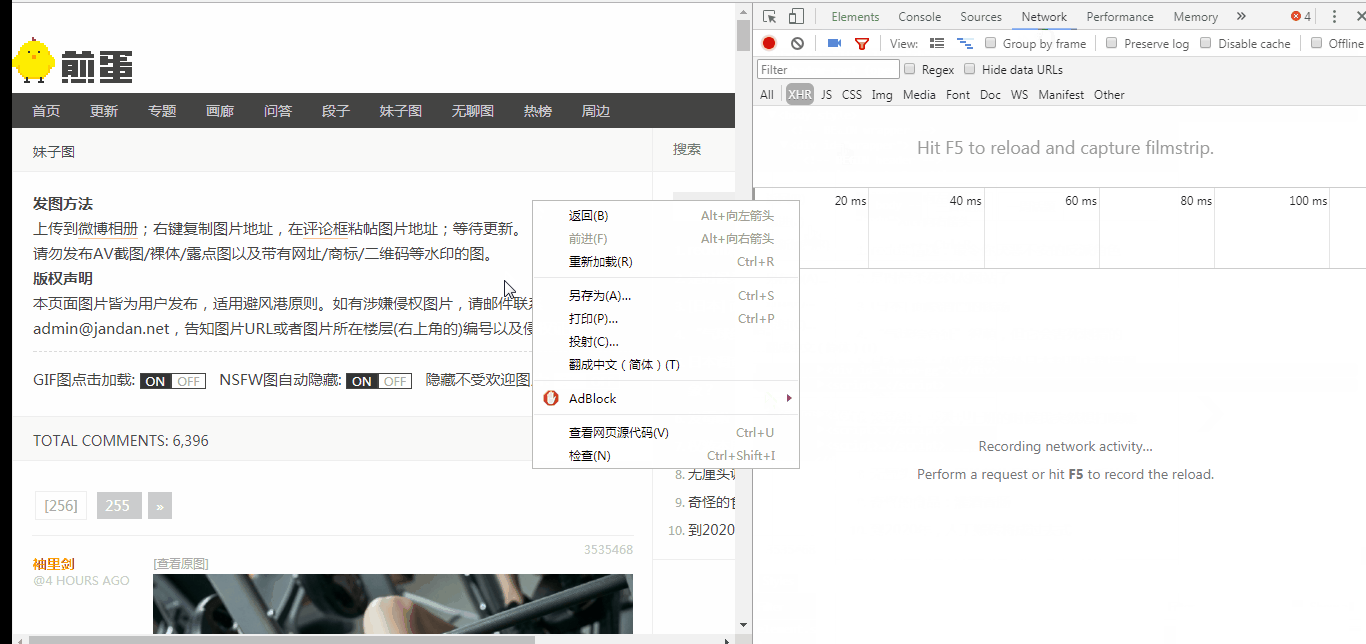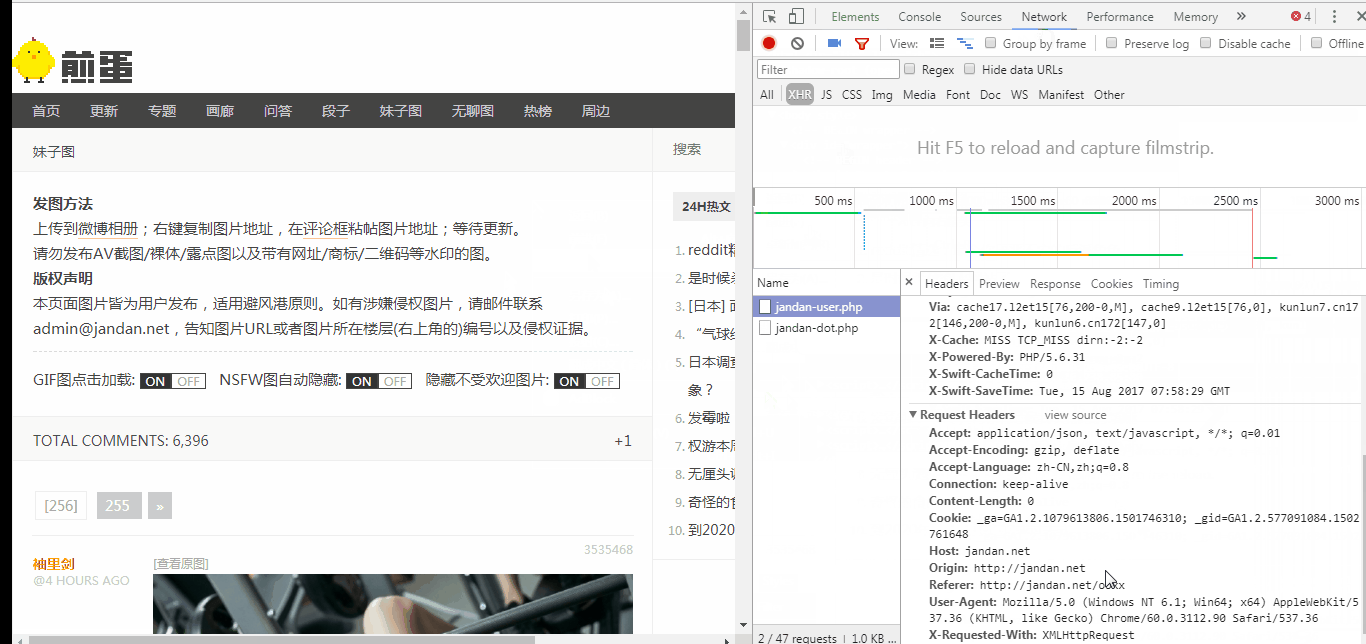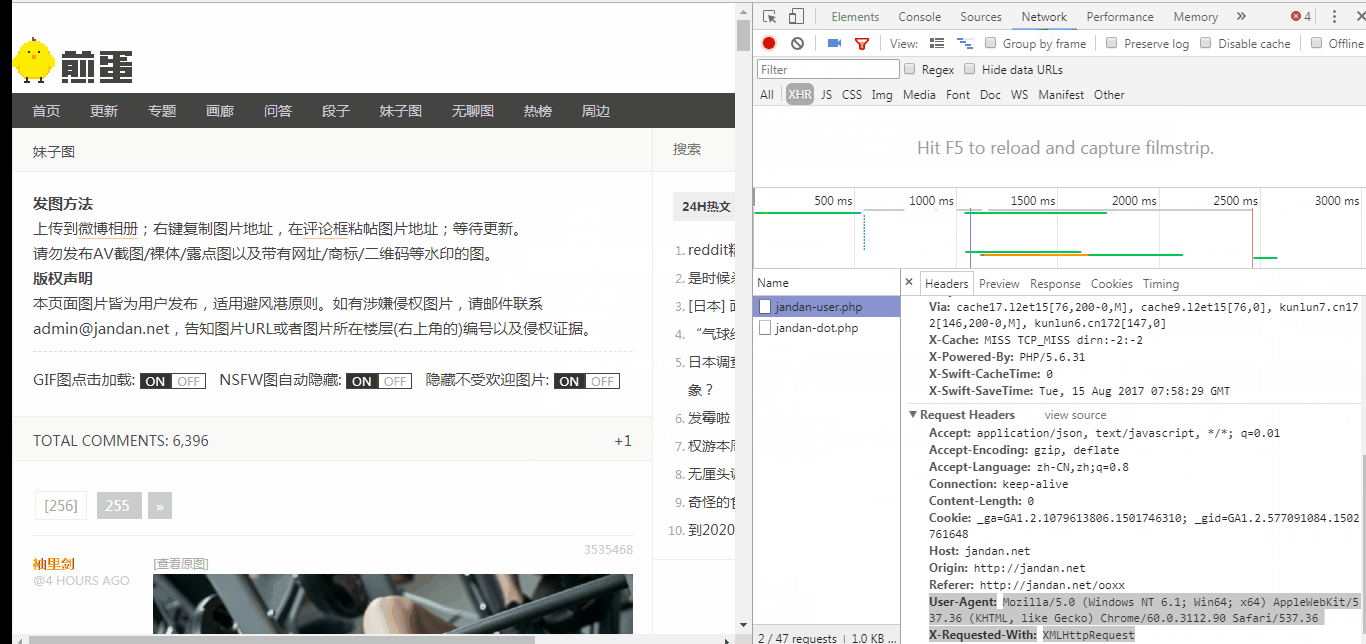
按照GIF中的操作我们可以获取到Chrome浏览器访问时的UA,我们将UA复制下来,加入到代码中,
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
}
wb_data = requests.get('http://jandan.net/ooxx',headers = headers)
这样我们访问网页时的UA就是浏览器啦,然后,我们就得解析网页,因为页面中的元素全部都是存放在网页的源代码之间的(可以右键>查看网页源代码试试看)
解析网页
解析网页这里我们用的是BeautifulSoup,这是比较常用也很方便的库,在原来的代码下加上
soup = BeautifulSoup(wb_data.text, 'lxml')
这时打印soup,我们就可以看见比较美观的网页源码了。
重点到啦~
这时候我们需要找到我们需要下载的图片在网页中的位置!
首先添加两行代码
img = soup.select(' ') # select中填入的selector就是我们需要找的
print(img)
了解一点html的同学(不了解也没事)都知道,网页是有结构的,

但是我们需要的是Python自己去匹配而不是我们去找,所以我们这样做。
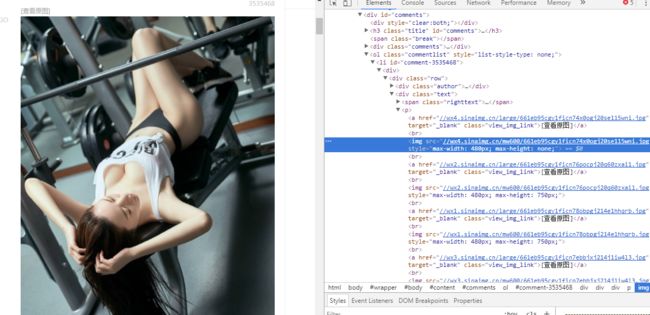
如gif中所示,我们所复制的selector
#comment-3535468 > div > div > div.text > p > img:nth-child(3)
就是这个元素所独有的地址,根据这个我们肯定是不能找到所有的图片链接的,所以我们需要做适当的调整,以匹配所有的图片链接,前面的comment-数字代表不同的用户,所以肯定不能要,后方的nth-child(3)表示img中第3个所以也不能要,就是说我们需要去除所有表示唯一的标识才能匹配所有的元素,
最终我所找到的能匹配到所有图片的selector为div > div > div.text > p > img,将其加入刚才select.右键运行。
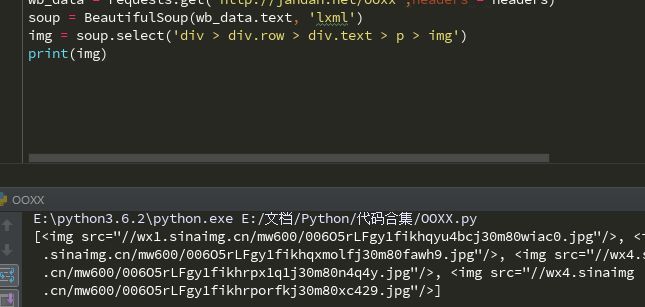
可以看到我们已经匹配了当前页面的所有img元素,然后我们需要获取其中的图片链接,但并不规范,而且也无法使用,所以用一个for循环获取所有的链接的"src"部分
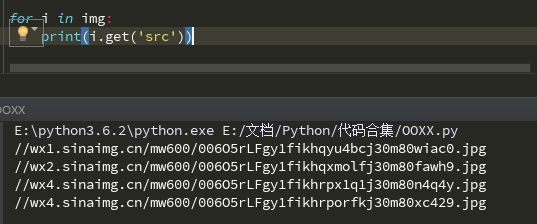
其中i.get('src')就是获取内部src处的文本
这里我们获取的链接没有头部,所以我们需要自行在循环中添加
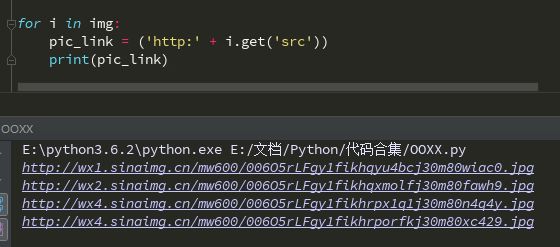
接下来就是最激动人心的下载环节了,我们有两种方式,一种是获取所有的链接存放在列表中完成后依次下载,另一种就是获取一个链接就开始下载,这里我们选择第二种,

urllib.request.urlretrieve方法如图,第一个参数是图片链接,第二个是存放位置以及名字,其他的我们不管。这里选择E盘picture为例。并且加入计数器方便给图片命名。

urllib.request.urlretrieve(pic_link, folder_path + '\\' + str(n) + pic_link[-4:])
这里的文件名是以文件夹加上\\然后文件名并且以链接的最后4个字符(用作后缀)给图片命名,就保证不会重名等问题。
最后的调整
现在!我们已经能够下载一页图片了,当然这还不够,我们的目标是星辰大海~~
首先点击其他页,会发现地址栏有变化(加上了页码)
地址栏带上了后缀,所以这里我们的思路是将上面的全部代码打包成一个函数,将地址栏用format和range函数写成
urls = ['http://jandan.net/ooxx/page-{}'.format(str(i)) for i in range(起始页码,终止页码)]的形式,再利用for循环遍历其中就可以下载我们所需页码的图片啦~
说干就干,这里我直接上最终的代码
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# url = 'http://jandan.net/ooxx'
urls = ['http://jandan.net/ooxx/page-{}'.format(str(i)) for i in range(256,258)] # 链接列表
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
}
n = 0 # 计数器
def pic_download(url):
time.sleep(2) # 每次运行暂停2秒
global n # 将n变为全局变量方便命名
wb_data = requests.get(url,headers = headers)
soup = BeautifulSoup(wb_data.text, 'lxml') # 解析网页
img = soup.select('div > div.row > div.text > p > img') # 寻找img元素
folder_path = r'E:\Picture' # 存放文件夹所在位置(此处需先创建文件夹)
for i in img:
pic_link = ('http:' + i.get('src')) # 将所获得的链接加上头部
urllib.request.urlretrieve(pic_link, folder_path + '\\' + str(n) + pic_link[-4:]) # 开始下载
n = n + 1 # 每运行一次n+1
print('download:'+pic_link)
print('===========下一页================')
for i in urls: # 将链接列表循环
pic_download(i)
最终效果图

结束语
1.这个教程适合的对象为零基础或者有一点点基础的想学爬虫无从下手的同学,所以用到的方法尽量少且简单,希望大佬们轻喷,有错误可以指正
2.有点矛盾的是说是零基础,但也得掌握点比如print,=赋值,for循环,字符串的方法这些最最基础的东西,这里如果再一一讲解那本文就太臃肿了,廖雪峰老师的教程,小甲鱼的视频都是很不错的自学教材。
3.爬虫涉及到的知识点非常非常多,一篇文章远远说不够,例如说你会爬虫,那么网站就有反爬虫,当然高手还有反反爬虫,这之间的斗争就像武林竞争一般,你有一剑我有一式来来往往真的非常酷炫,所以这篇文章更多的我想是激发各位学爬虫的热情。
4.我知道肯定文中有很多地方对于新手来说还是不太好理解,比如pic_link[-4:]是什么意思,selector到底怎么选等等问题,但我要说的是希望大家碰到问题应该学会使用搜索引擎(即使是百度也可以),学会检索信息就能解决很多问题,并且收获地更多,还有比如说debug,帮助文档,Python Console的使用等等。
5.我也是个新手,爬虫之路也许才刚走到门槛上面,希望和大家共同进步!