需要打上这么多断点,do_fork、copy_process、sys_clone、copy_thread、dup_task_struct等。
- 在执行fork之后,可以发现,停在了syd_clone处,显然是因为前面的
#ifdef CONFIG_CLONE_BACKWARDS生效了。
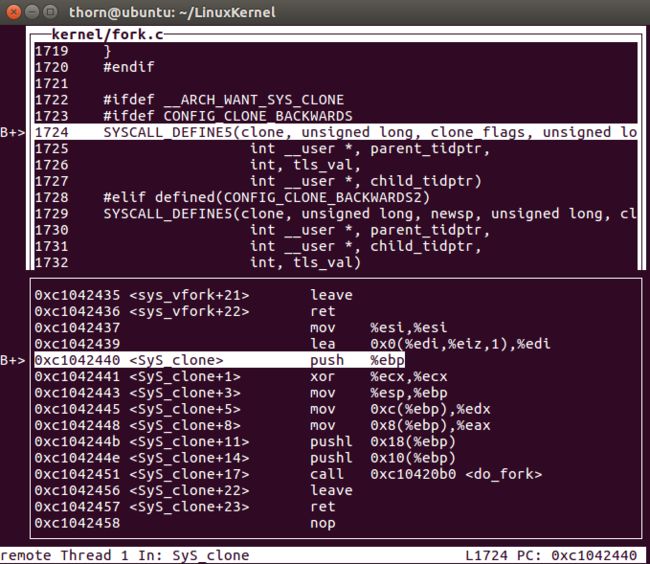
- 当然,实际执行的还是do_fork

- 因为我们关注的是进程的创建,这其中比较关键的一个地方是copy_process,那么就跟踪进去看看究竟如何。
前面进行了一大堆的参数检查,直到dup_task_struct

跟踪dup_task_struct进去看
- alloc_task_struct_node开辟进程内存,如果开辟成功,则继续向下进行,否则直接返回空(这个有些像我们用的malloc函数)。
- alloc_thread_info_node为thread分配内存

- 关键的一步又来了,arch_dup_task_struct,最主要的工作是
*dst = *src;
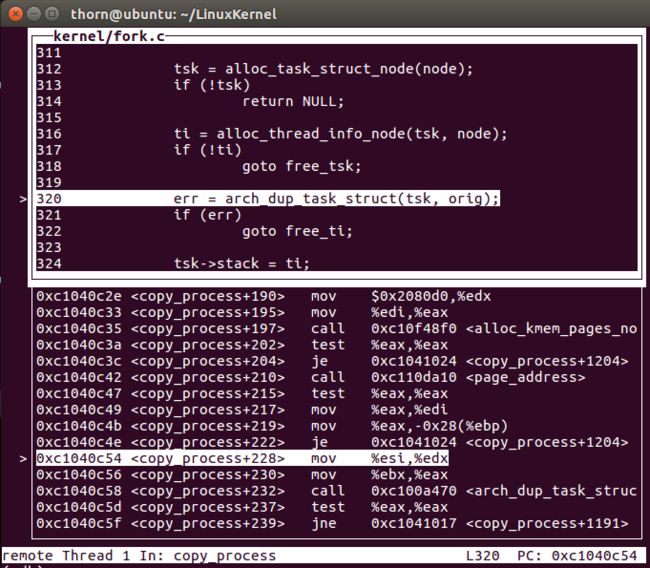
- 接下来setup_thread_stack设置thread_stack
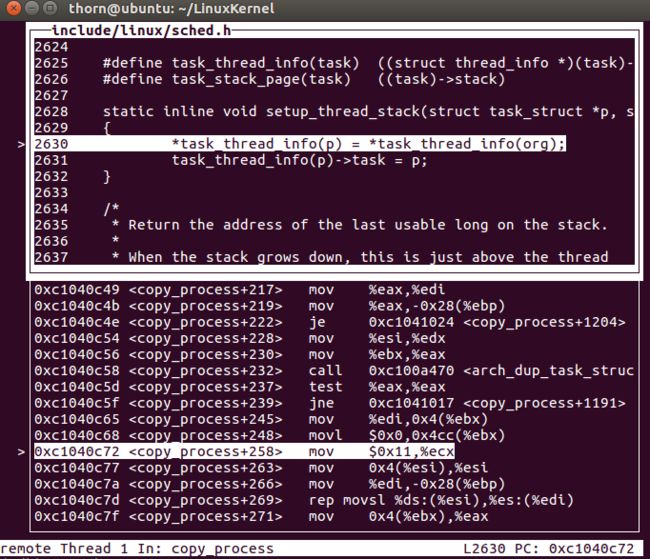
- 略过我们不关心的这些步骤,接着执行返回创建好的task_struct(p)到copy_process,做好参数判断之后,
接下来的很长的一段代码都是根据特定的环境设置刚刚我们复制出来的task_struct(p),有关于跟踪调试的,有关于中断的。。。
copy_files、copy_fs、copy_mm、copy_signial等等,这种种拷贝表明,子进程和父进程的很多东西是一样的。
当运行到copy_thread的时候,系统停了下来。可以看到,该函数对p的sp以及sp0进行设置。对cpu的其他一些寄存器进行设置。
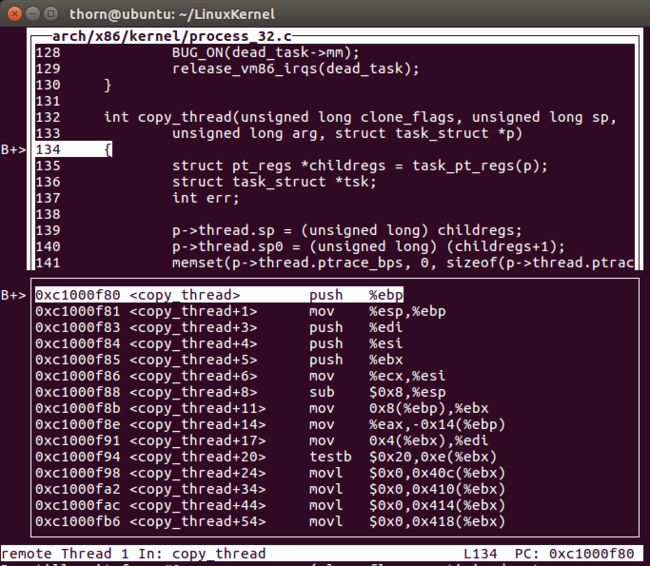
- copy_thread中有下面一片代码,其中,
p->thread.ip = (unsigned long) ret_from_kernel_thread;这也是很关键的一句,可能是从父进程返回?
下面的unlikely只是为了编译器优化(表明if的语句块执行的可能性小),将后面这段二进制代码不放在前面的代码之后。之所以会有这样的优化是因为,系统启动的时候,do_fork就会被调用,自认会有从kernel_thread返回的时候,但是这也仅限于系统刚启动,为了以后在创建新进程时候的执行速度能够加快,在系统刚刚启动的时候有一些性能损失没什么。
143 if (unlikely(p->flags & PF_KTHREAD)) {
144 /* kernel thread */
145 memset(childregs, 0, sizeof(struct pt_regs));
146 p->thread.ip = (unsigned long) ret_from_kernel_thread;
147 task_user_gs(p) = __KERNEL_STACK_CANARY;
148 childregs->ds = __USER_DS;
149 childregs->es = __USER_DS;
150 childregs->fs = __KERNEL_PERCPU;
151 childregs->bx = sp; /* function */
152 childregs->bp = arg;
153 childregs->orig_ax = -1;
154 childregs->cs = __KERNEL_CS | get_kernel_rpl();
155 childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
156 p->thread.io_bitmap_ptr = NULL;
157 return 0;
158 }
当然,如果上述语句块未执行到,那么会执行下面的:
159 *childregs = *current_pt_regs();
160 childregs->ax = 0;
161 if (sp)
162 childregs->sp = sp;
163
164 p->thread.ip = (unsigned long) ret_from_fork;
165 task_user_gs(p) = get_user_gs(current_pt_regs());
最后是设置子进程的返回值为0,thread的ip为ret_from_fork,这也就是我们子进程返回的执行点。
process_32.c中有如下定义,显然是嵌入式汇编,入口在entry_32.S中。
58 asmlinkage void ret_from_fork(void) __asm__("ret_from_fork");
59 asmlinkage void ret_from_kernel_thread(void) __asm__("ret_from_kernel_thread");
- entry_32.S中有这样的东东:
290 ENTRY(ret_from_fork)
291 CFI_STARTPROC
292 pushl_cfi %eax
293 call schedule_tail
294 GET_THREAD_INFO(%ebp)
295 popl_cfi %eax
296 pushl_cfi $0x0202 # Reset kernel eflags
297 popfl_cfi
298 jmp syscall_exit
299 CFI_ENDPROC
300 END(ret_from_fork)
301
302 ENTRY(ret_from_kernel_thread)
303 CFI_STARTPROC
304 pushl_cfi %eax
305 call schedule_tail
306 GET_THREAD_INFO(%ebp)
307 popl_cfi %eax
308 pushl_cfi $0x0202 # Reset kernel eflags
309 popfl_cfi
310 movl PT_EBP(%esp),%eax
311 call *PT_EBX(%esp)
312 movl $0,PT_EAX(%esp)
313 jmp syscall_exit
314 CFI_ENDPROC
315 ENDPROC(ret_from_kernel_thread)
- schedule_tail的实现,具体原理暂不深究
2305 /**
2306 * schedule_tail - first thing a freshly forked thread must call.
2307 * @prev: the thread we just switched away from.
2308 */
2309 asmlinkage __visible void schedule_tail(struct task_struct *prev)
2310 __releases(rq->lock)
2311 {
2312 struct rq *rq = this_rq();
2313
2314 finish_task_switch(rq, prev);
2315
2316 /*
2317 * FIXME: do we need to worry about rq being invalidated by the
2318 * task_switch?
2319 */
2320 post_schedule(rq);
2321
2322 if (current->set_child_tid)
2323 put_user(task_pid_vnr(current), current->set_child_tid);
2324 }
- copy_process之后,如果没有错误,那么wake_up_new_task将会第一次唤醒新创建的任务(也就是做一些调度统计管理,然后将这个任务放到运行队列中),如下面代码。显然,当子进程获得cpu的使用权之后,系统就会从ret_from_fork处返回执行。
这里面有很多奇怪的编译器指令或者是宏,待有时间再深究。
1657 if (!IS_ERR(p)) {
1658 struct completion vfork;
1659 struct pid *pid;
1660
1661 trace_sched_process_fork(current, p);
1662
1663 pid = get_task_pid(p, PIDTYPE_PID);
1664 nr = pid_vnr(pid);
1665
1666 if (clone_flags & CLONE_PARENT_SETTID)
1667 put_user(nr, parent_tidptr);
1668
1669 if (clone_flags & CLONE_VFORK) {
1670 p->vfork_done = &vfork;
1671 init_completion(&vfork);
1672 get_task_struct(p);
1673 }
1674
1675 wake_up_new_task(p);
1676
1677 /* forking complete and child started to run, tell ptracer */
1678 if (unlikely(trace))
1679 ptrace_event_pid(trace, pid);
1680
1681 if (clone_flags & CLONE_VFORK) {
1682 if (!wait_for_vfork_done(p, &vfork))
1683 ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
1684 }
1685
1686 put_pid(pid);
1687 } else {
1688 nr = PTR_ERR(p);
1689 }
1690 return nr;
很明显
nr = pid_vnr(pid);这一语句获取了进程的pid,在do_fork的最后返回。很显然,当do_fork返回之后,一切戛然而止,返回的nr就是子进程的pid,内核通过这种方式来区分父子进程,真是奇妙。
其实在fork系统调用的执行过程中,你会发现,究竟是子进程先返回还是父进程先返回,这是不一定的。作为程序员也不能假定返回的时刻。如果设置好子进程的一切(我理解是
wake_up_new_task(p);执行完成),调度点发生在do_fork返回之前,那么子进程先返回;如果是do_fork返回之后,调度点才到,父进程先返回,奇妙的很。至于子进程的返回过程,分析如下:
在copy_process中,乃至其中的copy_thread都对子进程的各种状态信息做了充分的设置。我们关注ip以及eax的保存。
调度点到了之后,系统会恢复eax为0,将ip恢复为ret_from_fork,首先保存eax,然后做一些必要的准备工作,重置内核eflags,最后跳转到syscall_exit,
你看,这样,这样,然后再这样,Linux就把进程创建出来了。
那么问题来了,为什么子进程的syscall_exit之后,就能返回到fork的下面一句代码执行呢?
思考中。。。