
作者 | 邓青琳(轻零) 阿里巴巴技术专家
导读:本文转载自阿里巴巴技术专家邓青琳(轻零)在内部的分享,他从阿里云控制台团队转岗到 ECI 研发团队(Serverless Kubernetes 背后的实现基石),从零开始了解 K8s,并从业务发展的视角整理了 K8s 是如何出现的,又是如何工作的。
前言
2019 年下半年,我做了一次转岗,开始接触到 Kubernetes,虽然对 K8s 的认识还非常的不全面,但是非常想分享一下自己的一些收获,希望通过本文能够帮助大家对 K8s 有一个入门的了解。文中有不对的地方,还请各位老司机们帮助指点纠正。
其实介绍 K8s 的文章,网上一搜一大把,而且 Kubernetes 官方文档也写的非常友好,所以直接上来讲 K8s,我觉得我是远远不如网上的一些文章讲的好的。因此我想换一个角度,通过一个业务发展的故事角度,来讲 K8s 是怎么出现的,它又是如何运作的。
故事开始
随着中国老百姓生活水平的不断提高,家家户户都有了小汽车,小王预计 5 年后,汽车报废业务将会迅速发展,而且国家在 2019 年也出台了新政策《报废机动车回收管理办法》,取消了汽车报废回收的“特种行业”属性,将开放市场化的竞争。
小王觉得这是一个创业的好机会,于是找了几个志同道合的小伙伴开始了创业,决定做一个叫“淘车网”的平台。
故事发展
淘车网一开始是一个 all in one 的 java 应用,部署在一台物理机上(小王同学,现在都啥时候了,你需要了解一下阿里云),随着业务的发展,机器越来越扛不住了,就赶紧对服务器的规格做了升级,从 64c256g 一路升到了 160c1920g,虽然成本高了点,但是系统至少没出问题。
业务发展了一年后,160c1920g 也扛不住了,不得不进行服务化拆分、分布式改造了。为了解决分布式改造过程中的各种问题,引入了一系列的中间件,类似 hsf、tddl、tair、diamond、metaq 等,在艰难的业务架构改造后,我们成功的把 all in one 的 java 应用拆分成了多个小应用,重走了一遍当年阿里中间件发展和去 IOE 的道路。
分布式改完后,我们管理的服务器又多起来了,不同批次的服务器,硬件规格、操作系统版本等等都不尽相同,于是应用运行和运维的各种问题就出来了。
还好有虚拟机技术,把底层各种硬件和软件的差异,通过虚拟化技术都给屏蔽掉了。虽然硬件不同,但是对于应用来说,看到的都是一样的啦,此时虚拟化又产生了很大的性能开销。
恩,不如我们使用 docker 吧,因为 docker 基于 cgroup 等 Linux 的原生技术,在屏蔽底层差异的同时,也没有明显的性能影响,真是一个好东西。而且基于 docker 镜像的业务交付,使得我们 CI/CD 的运作也非常的容易。
不过随着 docker 容器数量的增长,我们又不得不面对新的难题,就是大量的 docker 如何调度、通信呢?毕竟随着业务发展,淘车网已经不是一个小公司了,我们运行着几千个 docker 容器,并且按照现在的业务发展趋势,马上就要破万了。
不行,我们一定要做一个系统,这个系统能够自动的管理服务器(比如是不是健康、剩下多少内存和 cpu 可以使用啊等等)、然后根据容器声明所需的 cpu 和 memory 选择最优的服务器进行容器的创建,并且还要能够控制容器和容器之间的通信(比如说某个部门的内部服务,当然不希望其他部门的容器也能够访问)。
我们给这个系统取一个名字,就叫做容器编排系统吧。
容器编排系统

那么问题来了,面对一堆的服务器,我们要怎么实现一个容器编排系统呢?
先假设我们已经实现了这个编排系统,那么我们的服务器就会有一部分会用来运行这个编排系统,剩下的服务器用来运行我们的业务容器,我们把运行编排系统的服务器叫做 master 节点,把运行业务容器的服务器叫做 worker 节点。
既然 master 节点负责管理服务器集群,那它就必须要提供出相关的管理接口,一个是方便运维管理员对集群进行相关的操作,另一个就是负责和 worker 节点进行交互,比如进行资源的分配、网络的管理等。
我们把 master 上提供管理接口的组件称为 kube apiserver,对应的还需要两个用于和 api server 交互的客户端:
- 一个是提供给集群的运维管理员使用的,我们称为 kubectl;
- 一个是提供给 worker 节点使用的,我们称为 kubelet。
现在集群的运维管理员、master 节点、worker 节点已经可以彼此间进行交互了,比如说运维管理员通过 kubectl 向 master 下发一个命令:“用淘车网用户中心 2.0 版本的镜像创建 1000 个容器”,master 收到这个请求之后,就要根据集群里面 worker 节点的资源信息进行一个计算调度,算出来这 1000 个容器应该在哪些 worker 上进行创建,然后把创建指令下发到相应的 worker 上。我们把这个负责调度的组件称为 kube scheduler。
那 master 又是怎么知道各个 worker 上的资源消耗和容器的运行情况的呢?这个简单,我们可以通过 worker 上的 kubelet 周期性的主动上报节点资源和容器运行的情况,然后 master 把这个数据存储下来,后面就可以用来做调度和容器的管理使用了。至于数据怎么存储,我们可以写文件、写 db 等等,不过有一个开源的存储系统叫 etcd,满足我们对于数据一致性和高可用的要求,同时安装简单、性能又好,我们就选 etcd 吧。
现在我们已经有了所有 worker 节点和容器运行的数据,我们可以做的事情就非常多了。比如前面所说的,我们使用淘车网用户中心 2.0 版本的镜像创建了 1000 个容器,其中有 5 个容器都是运行在 A 这个 worker 节点上,那如果 A 这个节点突然出现了硬件故障,导致节点不可用了,这个时候 master 就要把 A 从可用 worker 节点中摘除掉,并且还需要把原先运行在这个节点上的 5 个用户中心 2.0 的容器重新调度到其他可用的 worker 节点上,使得我们用户中心 2.0 的容器数量能够重新恢复到 1000 个,并且还需要对相关的容器进行网络通信配置的调整,使得容器间的通信还是正常的。我们把这一系列的组件称为控制器,比如节点控制器、副本控制器、端点控制器等等,并且为这些控制器提供一个统一的运行组件,称为控制器管理器(kube-controller-manager)。
那 master 又该如何实现和管理容器间的网络通信呢?首先每个容器肯定需要有一个唯一的 ip 地址,通过这个 ip 地址就可以互相通信了,但是彼此通信的容器有可能运行在不同的 worker 节点上,这就涉及到 worker 节点间的网络通信,因此每个 worker 节点还需要有一个唯一的 ip 地址,但是容器间通信都是通过容器 ip 进行的,容器并不感知 worker 节点的 ip 地址,因此在 worker 节点上需要有容器 ip 的路由转发信息,我们可以通过 iptables、ipvs 等技术来实现。那如果容器 ip 变化了,或者容器数量变化了,这个时候相关的 iptables、ipvs 的配置就需要跟着进行调整,所以在 worker 节点上我们需要一个专门负责监听并调整路由转发配置的组件,我们把这个组件称为 kube proxy。
我们已经解决了容器间的网络通信,但是在我们编码的时候,我们希望的是通过域名或者 vip 等方式来调用一个服务,而不是通过一个可能随时会变化的容器 ip。因此我们需要在容器 ip 之上再封装出一个 service 的概念,这个 service 可以是一个集群的 vip,也可以是一个集群的域名,为此我们还需要一个集群内部的 DNS 域名解析服务。
另外虽然我们已经有了 kubectl,可以很愉快的和 master 进行交互了,但是如果有一个 web 的管理界面,这肯定是一个更好的事情。此处之外,我们可能还希望看到容器的资源信息、整个集群相关组件的运行日志等等。
像 DNS、web 管理界面、容器资源信息、集群日志,这些可以改善我们使用体验的组件,我们统称为插件。
至此,我们已经成功构建了一个容器编排系统,下面我们来简单总结一下上文提到的各个组成部分:
- Master 组件:kube-apiserver、kube-scheduler、etcd、kube-controller-manager;
- Node 组件:kubelet、kube-proxy;
- 插件:DNS、用户界面 Web UI、容器资源监控、集群日志。
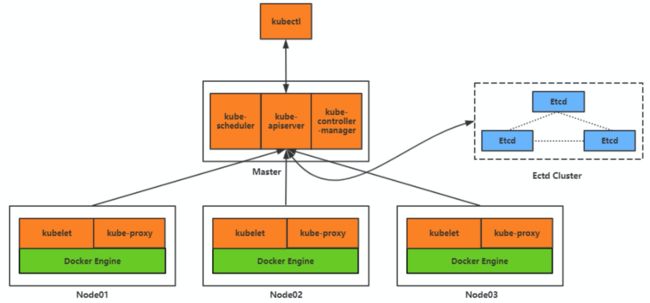
这些也正是 K8s 中的重要组成部分。当然 K8s 作为一个生产级别的容器编排系统,这里提到的每一个组件都可以拿出来单独讲上很多内容,本文只是一个简单入门,不再展开讲解。
Serverless 的容器编排系统
虽然我们已经成功实现了一个容器编排系统,并且也用的很舒服,但是淘车网的王总裁(已经不是当年的小王了)觉得公司花在这个编排系统上的研发和运维成本实在是太高了,想要缩减这方面的成本。王总想着有没有一个编排系统,能够让员工专注到业务开发上,而不需要关注到集群的运维管理上,于是他和技术圈的同学了解了一下,发现 Serverless 的理念和他的想法不谋而合,于是就在想:啥时候出一个 Serverless 的容器编排系统就好啦。
幸运的是,王总在阿里云网站上,看到了一款叫做 Serverless Kubernetes 的产品。。。后面的故事就不展开讲了,因为到了这个地方,更重要的事情就出现了。
招人啦!
云原生和 ECI 研发团队招人啦,让我们一起打造业界领先的云原生和弹性计算服务,为社会提供稳定高效的数字经济基础设施!
- 3 年以上分布式系统相关经验,熟悉高并发,分布式通信,存储等相关技术;
- 熟练掌握 Golang/Java/Rust 语言开发,具备 Python, Shell 等其它一种或多种语言开发经验;
- 对容器和基础设施相关领域的技术充满热情,有 PaaS 平台相关经验,在相关的领域如 Kubernetes、Serverless 平台、容器技术、应用管理平台等有丰富的积累和实践经验(如产品落地,创新的技术实现,开源的突出贡献,领先的学术研究成果等)。
简历投递通道:
- [email protected](云原生)
- [email protected](ECI)

“阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的公众号。”