转载请注明出处:http://blog.csdn.net/zhoubin1992/article/details/46481759
在Android编程或者面试中经常会遇到Java 面向对象和集合的知识点。自己结合实际的编程以及阅读网上资料总结一下。
java面向对象-万物皆为对象
一、==和equal()的区别
1、基本数据类型: byte,short,char,int,long,float,double,boolean 他们之间的比较,应用双等号(==),比较的是他们的值。
2、复合数据类型(类) :当他们用(==)进行比较的时候,比较的是他们在JVM中的存放地址,所以,除非是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false。 JAVA当中所有的类都是继承于Object这个基类的,在Object中的基类中定义了一个equals的方法,这个方法的初始行为也是比较对象的内存地址,但在一些类库当中这个方法被覆盖掉了,如String,Integer,Date在这些类当中equals有其自身的实现,而不再是比较类在堆内存中的存放地址了。
3、String的equal()
(1)String类中的equals首先比较地址,如果是同一个对象的引用,可知对象相等,返回true。
(2)若果不是同一个对象,equals方法挨个比较两个字符串对象内的字符,只有完全相等才返回true,否则返回false。
二、String、StringBuffer、StringBuilder的区别
String 字符串常量(对象不可变,线程安全) private final char value[];
StringBuffer 字符串变量(线程安全)
StringBuilder 字符串变量(非线程安全) char[] value;
如果程序不是多线程的,那么使用StringBuilder效率高于StringBuffer。
在大部分情况下运行效率:StringBuilder > StringBuffer> String
三、final, finally, finalize的区别
final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
finally是异常处理语句结构的一部分,表示总是执行。
finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。
四、Overload和Override的区别
方法的重写Overriding和重载Overloading是Java多态性的不同表现。重写Overriding是父类与子类之间多态性的一种表现,重载Overloading是一个类中多态性的一种表现。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Overriding)。子类的对象使用这个方法时,将调用子类中的定义,对它而言,父类中的定义如同被”屏蔽”了。如果在一个类中定义了多个同名的方法,它们或有不同的参数个数或有不同的参数类型,则称为方法的重载(Overloading)。
五、java 继承
extends关键字,子类扩展了父类,也具有父类的全部成员变量和方法,但是Java的子类不能获得父类的构造器。 Java没有C++中的多继承特征,每个类最多只有一个直接父类(单继承) 当调用子类构造器来初始化子类对象时,父类构造器总会在子类构造器之前执行。 创建任何Java对象,最先执行的总是java.lang.object类的构造器,从该类所在继承树最顶层类的构造器开始执行,然后依次向下执行。
六、Java多态
如果Java引用变量的编译时类型和运行时类型不一致是,就可能出现多态。 运行时该引用变量的方法总是表现出子类方法的行为特征。(出现重写) Java中多态的实现方式:接口实现,继承父类进行方法重写(父类引用指向子类对象),同一个类中进行方法重载。
七、抽象类和接口的区别
接口和抽象类的概念不一样。接口是对动作的抽象(吃),抽象类是对根源的抽象(人)。 一个类只能继承一个类(抽象类),但是可以实现多个接口(吃,行)。 1. 接口可以多继承,抽象类不行 2. 抽象类中可以定义一些子类的公共方法,子类只需要增加新的功能,不需要重复写已经存在的方法;而接口中只是对方法的申明和常量的定义。 3. 接口中基本数据类型为public static 而抽类象不是,是普通变量类型。 4. 抽象类和接口都不能直接实例化,如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,接口变量必须指向实现所有接口方法的类对象。 5. 抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,一个实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
八、内部类作用
放在一个类的内部的类我们就叫内部类。
作用:
- 内部类可以很好的实现隐藏,方便将存在一定逻辑关系的类组织在一起。 一般的非内部类,是不允许有private与protected权限的,但内部类可以。
- 内部类拥有外围类的所有元素的访问权限。
- 可是实现多重继承,每个内部类都能独立的继承一个接口的实现,所以无论外部类是否已经继承了某个(接口的)实现,对于内部类都没有影响。内部类使得多继承的解决方案变得完整。
- 可以避免修改接口而实现同一个类中两种同名方法的调用。
- 方便编写线程代码。
九、java对象序列化
序列化:把Java对象转换为字节序列的过程。
反序列化:把字节序列恢复为Java对象的过程。
只有实现了Serializable和Externalizable接口的类的对象才能被序列化。 读取对象的顺序与写入时的顺序要一致。 对象的默认序列化机制写入的内容是:对象的类,类签名,以及非瞬态和非静态字段的值。
用途 :
1) 把对象转换成平台无关的二进制流永久地保存到硬盘上,通常存放在一个文件中;
2) 在网络上传送对象的字节序列。
十、java集合
HashSet类
hashSet用Hash算法来存储集合中的元素,具有很好的存取和查找性能。
特点:
- 无序
- 不是同步的
- 集合元素值可为null
- 不允许包含相同的元素
存入一个元素: HashSet调用该对象的hashCode()方法得到hashCode值,根据该hashCode值确定该对象的存储位置。
访问一个元素: HashSet先计算该元素的hashCode值,然后直接到该hashCode值对应的位置去取出该元素。 如果元素相同则添加失败add()返回false。
HashSet集合判断两个元素相同的标准是两个对象equals()方法比较相等,并且hashCode值也相等。
如果两个对象的hashCode值相同,equals()返回false时,会在同一个位置用链式结构来保存。导致性能下降。
十一、ArrayList和Vector有何异同点
相同点:
- 两者都是基于索引的,内部由一个数组支持。
- 两者维护插入的顺序,我们可以根据插入顺序来获取元素。
- ArrayList和Vector的迭代器实现都是fail-fast的。
- ArrayList和Vector两者允许null值,也可以使用索引值对元素进行随机访问。
不同点:
- Vector是同步的,而ArrayList不是。然而,如果你寻求在迭代的时候对列表进行改变,你应该使用CopyOnWriteArrayList。
- ArrayList比Vector快,它因为有同步,不会过载。
- ArrayList更加通用,因为我们可以使用Collections工具类轻易地获取同步列表和只读列表。
十二、HashMap类和Hashtable类
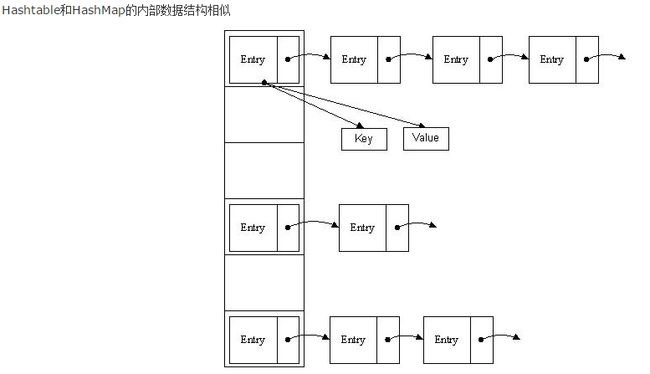
HashMap和Hashtable判断两个key相等的标准是两个key的equals()方法比较返回true,并且hashCode值也相等。 对同一个Key,只会有一个对应的value值存在。 如何算是同一个Key? 首先,两个key对象的hash值相同,其次,key对象的equals方法返回真 所以用做key的对象必须重写equals()和hashCode()方法,保证两个方法的判断标准一致——两个key的equals方法返回真,hashCode值也相同。
HashMap和Hashtable的区别
HashMap允许key和value为null,而HashTable不允许。HashTable是同步的(线程安全),而HashMap不是(线程不安全)。所以HashMap适合单线程环境,HashTable适合多线程环境。HashMap比HashTable的性能高点。
HashMap和Hashtable中key-value对无序。但在Java1.4中引入了LinkedHashMap,HashMap的一个子类,假如你想要遍历顺序,你很容易从HashMap转向LinkedHashMap,但是HashTable不是这样的,它的顺序是不可预知的。
HashMap提供对key的Set进行iterator遍历,因此它是fail-fast的,但Hashtable提供对key的Enumeration进行遍历,它不支持fail-fast。(fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。例如:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生fail-fast事件)Hashtable被认为是个遗留的类,如果你寻求在迭代的时候修改Map,你应该使用CocurrentHashMap。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
hashCode()和equals()方法有何重要性
hashCode是根类Obeject中的方法。 默认情况下,Object中的hashCode() 返回对象的32位jvm内存地址。也就是说如果对象不重写该方法,则返回相应对象的32为JVM内存地址。
HashMap使用Key对象的hashCode()和equals()方法去决定key-value对的索引。当我们试着从HashMap中获取值的时候,这些方法也会被用到。如果这些方法没有被正确地实现,在这种情况下,两个不同Key也许会产生相同的hashCode()和equals()输出,HashMap将会认为它们是相同的,然后覆盖它们,而非把它们存储到不同的地方。同样的,所有不允许存储重复数据的集合类都使用hashCode()和equals()去查找重复,所以正确实现它们非常重要。equals()和hashCode()的实现应该遵循以下规则: 2.1 如果o1.equals(o2),那么o1.hashCode() == o2.hashCode()总是为true的。 2.2 如果o1.hashCode() == o2.hashCode(),并不意味着o1.equals(o2)会为true。
*在Java中,HashMap是如何工作的?
HashMap在Map.Entry静态内部类实现中存储key-value对。HashMap使用哈希算法,在put和get方法中,它使用hashCode()和equals()方法。当我们通过传递key-value对调用put方法的时候,HashMap使用Key hashCode()和哈希算法来找出存储key-value对的索引。Entry存储在LinkedList中,所以如果存在entry,它使用equals()方法来检查传递的key是否已经存在,如果存在,它会覆盖value,如果不存在,它会创建一个新的entry然后保存。当我们通过传递key调用get方法时,它再次使用hashCode()来找到数组中的索引,然后使用equals()方法找出正确的Entry,然后返回它的值。 其它关于HashMap比较重要的问题是容量、负荷系数和阀值调整。HashMap默认的初始容量是32,负荷系数是0.75。阀值是为负荷系数乘以容量,无论何时我们尝试添加一个entry,如果map的大小比阀值大的时候,HashMap会对map的内容进行重新哈希,且使用更大的容量。容量总是2的幂,所以如果你知道你需要存储大量的key-value对,比如缓存从数据库里面拉取的数据,使用正确的容量和负荷系数对HashMap进行初始化是个不错的做法。