这个话题的来源于,2年前折腾Redis Cluster过程中,遇到的各种坑后积累出的一些想法,加上过去一年在梳理摇旺的缓存系统中遇到的问题后,有必要集中写写这一块,算做一个阶段性总结。
在开始往下讲之前,或许部分同学会问,缓存如果挂了,把缓存重启或者启动起来不就可以了吗?没错,缓存挂了,确实需要尽快将缓存恢复回来,但是如果认为缓存挂了,就直接重启缓存就完事了,那就将问题看得过于简单化了。对于一个大型互联网系统而言,这时服务调用方是无法对缓存进行存取操作,只能将流量完全打到服务方系统,服务方系统面对服务过载在劫难逃。接下来就不是缓存宕机那么简单了,而是系统不可用,乃至对外服务彻底瘫痪掉。反过来说,缓存启动后,缓存里的数据已经还在初始化中,缓存查询还是无法进行,所有的流量还是会继续打到服务方系统上。
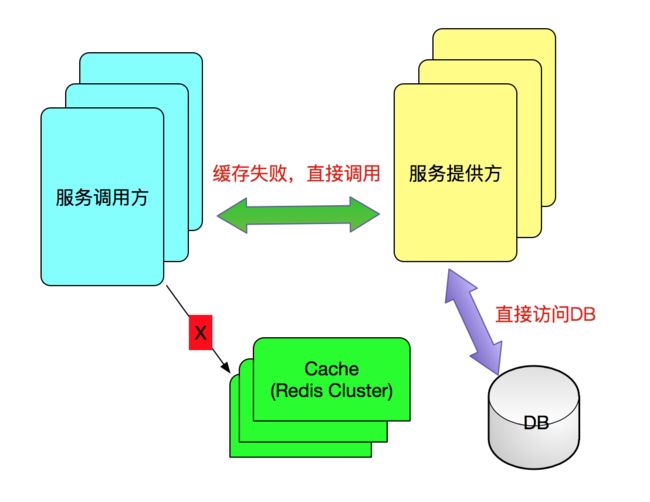
所以如果出现缓存宕机,我们需要考虑两方面的问题:
缓存恢复前,如何保证系统能继续正常有序的工作
缓存恢复后,如何保证缓存在K/V恢复前,对应的服务不会过载。
以上这两个问题,才是本文真正想讨论的问题。以下部分,会针对以上两个问题分别进行讨论。
缓存宕机后,并且未恢复前,调用方系统请求通过调用Cache,发现Cache系统状态不可用,则转向请求服务方系统(通过接口从数据库访问数据),我们可选的方案如下:
A.发现缓存不可用,不进一步调用服务提供方系统,直接返回预先设定的系统默认值。
B.发现缓存不可用,调用方系统按照一定的比率或者概率,决定让部分请求调用服务提供方。
C.调用服务方之前,根据服务方反馈的状态,动态决定请求是否调用服务方,或者直接返回默认值。
方案A 实施起来最容易,如果调用方知道直接调用服务提供方系统可能扛不住自己的全部流量,索性不请求服务方,等待缓存恢复后在继续访问。但这个方案的局限性在于,如果有写需求,这个方案就行不通了,因为很难简单的设定默认值, 并且,如果缓存缺乏持久化的话,数据缓存的更新是需要一次次调用来初始化的。
方案B的方案的优点在于,让一部分线程请求服务方系统,保证数据能及时更新的同时,缓存也能持续初始化,至于让多少比例的流量直接调用服务,保守的做法就是保证调用方的并发不大于服务方的最大吞吐量。所以,在采用B方案之前,一定要做好性能或者压力测试。
方案C的做法,实际上类似于上篇我写的Hystrix的Circuit-breaker机制,如果服务方系统运行正常,执行请求;如果服务方系统过载,则拒绝服务,保护服务提供方的同时,最大限度挖掘服务方性能。可以参考的性能参数有CPU负载、内存使用率、GC频率、接口响应时间等。
总结一下,方案C应该是系统应对缓存宕机的改进方向,但是如果时间有限的前提下,可以先利用短平快的方案B实施起来。
接下来,我们来讨论一下第二个问题,Cache已经从宕机过程恢复过来了,如果缓存KEY的数量较少,那么自然不用担心,很快缓存将预热成功,也不会有引起服务过载的情况出现。但是如果缓存的量或者当前前端过来的流量不好估计的时候,是不建议贸然将流量直接切过来的。
为了保证系统能顺利恢复正常,我们应该采用流控的方法,循序渐进的放开流量,让缓存逐步预热。流量控制刚开始可以为20%,然后50%,然后80%,最后全量,在放开一部分,需要实时观察系统的状态,根据前端流量的变化和后端的承受能力,制定放开的节奏。除此之外,强烈推荐后端系统制作专门的工具对Cache进行主动性预热,加快系统恢复的速度,特别是缓存没有做必要的持续化的时候。
扫描二维码或手动搜索微信公众号【架构栈】: ForestNotes
欢迎转载,带上以下二维码即可

阅读原文