偶看<<孔乙己>>,用爬虫爬出了孔乙己文中三个字的词组.
孔乙己爬虫
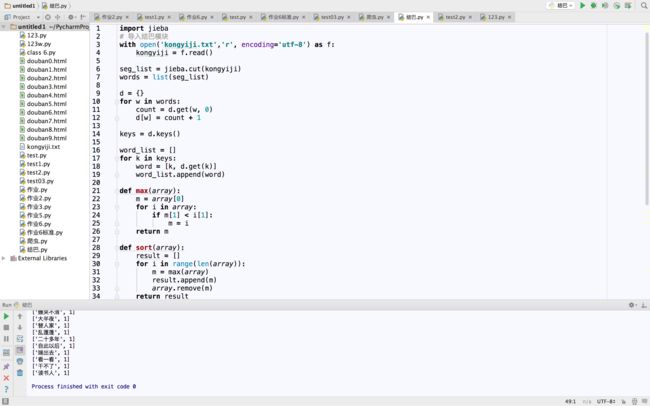
代码如下
import jieba
# 导入结巴模块
with open('kongyiji.txt','r', encoding='utf-8') as f:
kongyiji = f.read()
seg_list = jieba.cut(kongyiji)
words = list(seg_list)
d = {}
for w in words:
count = d.get(w, 0)
d[w] = count + 1
keys = d.keys()
word_list = []
for k in keys:
word = [k, d.get(k)]
word_list.append(word)
def max(array):
m = array[0]
for i in array:
if m[1] < i[1]:
m = i
return m
def sort(array):
result = []
for i in range(len(array)):
m = max(array)
result.append(m)
array.remove(m)
return result
def fliter(array):
result = []
for w in array:
if len(w[0]) >= 3:
result.append(w)
return result
sorted_words = sort(word_list)
result = fliter(sorted_words)
for w in result[:]:
print(w)
结果是(后面的数字是文章中词组出现的次数)
['孔乙己', 33]
['茴香豆', 5]
['十九个', 4]
['不耐烦', 2]
['掌柜的', 2]
['之乎者也', 2]
['怎么样', 2]
['半懂不懂', 2]
['端出去', 1]
['睁大眼睛', 1]
['自此以后', 1]
['免不了', 1]
['叹一口气', 1]
['十多年', 1]
['伸出头', 1]
['这时候', 1]
['不一会', 1]
['坏脾气', 1]
['第二年', 1]
['背地里', 1]
['做点事', 1]
['涨红了脸', 1]
['大半夜', 1]
['一九一九年', 1]
['努着嘴', 1]
['两三天', 1]
['多不多', 1]
['二十多年', 1]
['乱蓬蓬', 1]
['君子固穷', 1]
['十二岁', 1]
['唠唠叨叨', 1]
['赶热闹', 1]
['曲尺形', 1]
['说笑声', 1]
['对柜里', 1]
['看一看', 1]
['读书人', 1]
['替人家', 1]
['干不了', 1]
['缠夹不清', 1]
当然想查找其他的索引要求可以随意添加,技术比较好实现