哈希表(Hash Table)
- 计数排序中的桶(复杂度 O(n+max),比快排还快
- 桶排序 与计数排序的区别
- 基数排序 与计数排序的区别
什么是hash?
所有满足于key:value / 键:值这种条件的都叫hash。例如我们平时看的http请求响应,就是一个hash,数组是hash,对象也是hash。
计数排序
冒泡排序、选择排序和插入排序都叫做比较排序,只要是要做比较,至少都要遍历一次或比较一次。所以比较排序的极限,也就是最快的时间复杂度为:NlogN
随机快排的时间复杂度:NlogN
但是计数排序可以做到更快:O(n+max),比快排还快,因为它不是比较排序
计数排序的两个缺点:
- 必须要有hash
- 无法对小数和负数进行排序
计数排序伪代码:
a <- {
'0':0,
'1':2,
'2':1,
'3':56,
'4':4,
'5':67,
'6':3,
'length:7'
}
hash <- {}
index <- 0
while index < a['length']
number <- a[index]
if hash[number] == undefined // 如果hash[number] 不存在
hash[number] = 1 //那么桶里面就放一个1
else
hash[number] <- hash[number] + 1 //如果已经存在了重复的数字,那就加1
end
index <- index + 1
end
index2 <- 0
max <- findMax(a) // 最大值67
newArr <- {}
while index2 < max + 1
count <- hash[index2]
if count != undefined // count 存在
countIndex <- 0
while countIndex < count
newArr.push(index2)
countIndex <- countIndex + 1
end
end
index2 <- index2 + 1
end
print newArr
计数排序伪代码思路:
0 2 1 56 3 67 3
hash = {}
index == 0 //第一轮
number = 0
hash = {'0':1}
------------------------
index == 1 //第二轮
number = 2
hash = {'0':1,'2':1}
------------------------
index == 2 //第三轮
number = 1
hash = {'0':1,'1':1,'2':1}
------------------
index == 3 //第四轮
number = 56
hash = {'0':1,'1':1,'2':1,'56':1}
-------------------
index == 4 //第五轮
number = 3
hash = {'0':1,'1':1,'2':1,'3':1,'56':1}
---------------
index == 5 //第六轮
number = 67
hash = {'0':1,'1':1,'2':1,'3':1,'56':1,'67':1}
----------------
index == 6 //第七轮
number = 3
hash = {'0':1,
'1':1,
'2':1,
'3':2,
'56':1,
'67':1
}
入桶
----------------
出桶
index2 = 0
newArr = [0]
index2 = 1
newArr = [0,1]
index2 = 2
newArr = [0,1,2]
index2 = 3
newArr = [0,1,2,3,3]
index2 = 4
什么也不做
index2 = 5
什么也不做
...
...
index = 56
newArr = [0,1,2,3,3,56,67]
桶排序
0 2 1 56 3 67 3
hash:{
1:[0,2,1,3] //0-10的数字
2:[], //11-20的数字
3:[],
4:[],
5:[],
6:[56], //51-60的数字
7:[67] //61-70的数字
}
桶排序和计数排序的区别:
桶排序每个桶可以放一定范围内的数字,然后每个桶里再进行其他排序,比如冒泡排序或快排等,然后每个桶就不需要再和其它桶进行排序了,只排自己的桶就好
计数排序浪费了桶,比如上面的例子就用了67个桶
桶排序节约桶,只用了7个桶,但是需要做二次排序,比较难
计数排序可以用在比如排一个班级的年龄,桶排序可以用在排高考分数等
基数排序
基数排序用到了队列,先进先出
从数字的个位开始入桶,按先进先出出桶,然后十位,百位,千位...
一般数字大的就用基数排序,比如一到十万的数字
基数排序可视化
队列和栈
队列(Queue)
- 先进先出
- 可以用数组实现
- 举例:排队
用数组表示:

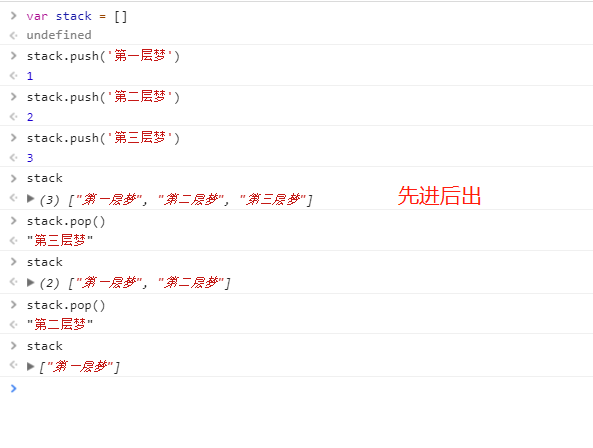
栈(Stack)
- 先进后出
- 可以用数组实现
- 举例:盗梦空间
用数组表示:
链表和树
链表(Linked List)
- 数组无法直接删除中间的一项,链表可以
- 用哈希(JS里面用对象表示哈希)实现链表
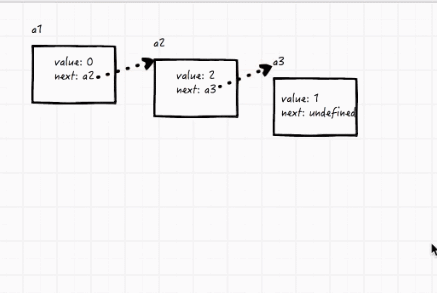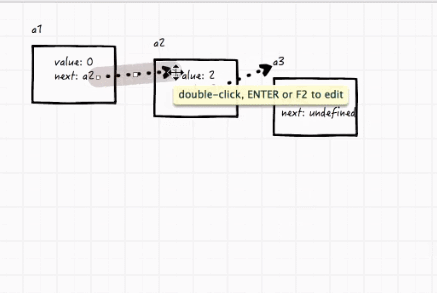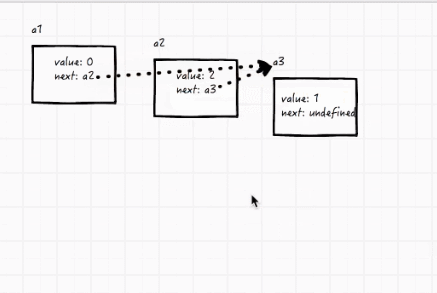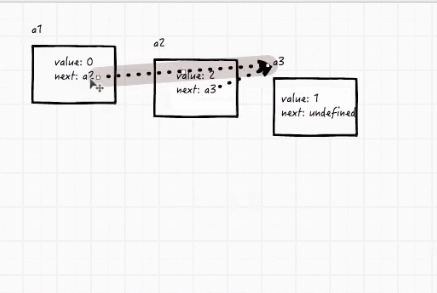
- head、node 概念(第一个为表头head(比如下面的a1),其他的都为节点node(比如下面的a2和a3))
平时我们给数组去除第一个或最后一个数字很简单,但是要删除数组里面的一个数字就复杂很多,这时就可以用到链表。
比如有三个变量,a1指向a2,a2指向a3,现在要把a2删掉,很简单,直接把a1指向a3就行了。
代码实现:

一般平时想要删除头或尾的数字就用数组来实现,要是想删除中间的数字,就用链表来实现。链表一般都用的比较少,比较常用队列和栈。
树(tree)
- 举例:层级结构、DOM
- 概念:层数、深度、节点个数
- 二叉树
- 满二叉树
- 完全二叉树
- 完全二叉树和满二叉树可以用数组实现
- 其他树可以用哈希(对象)实现
- 操作:增删改查
- 堆排序用到了 tree
- 其他:B树、红黑树、AVL树
什么时候用到树?只要有层级结构,就要用到树。
链表就是全程只有一个箭头,没有分叉。而树是有多个分叉的。
概念:层数、深度、节点个数
例如我们平时的页面
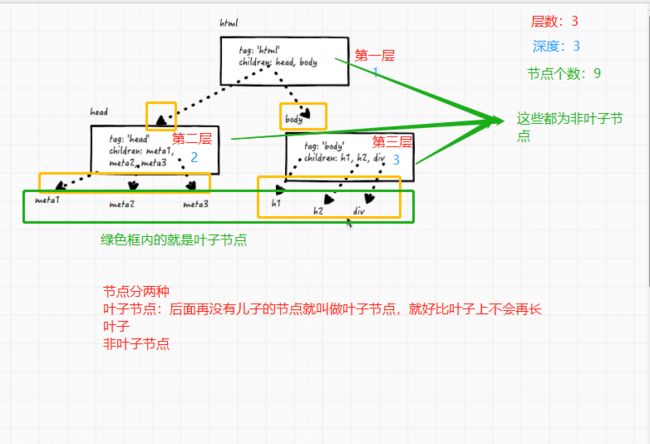
如果一个hash满足上图的结构就叫做树
二叉树
二叉树,是每个节点最多只有两个分支(不存在分支度大于2的节点)的树结构。通常分支被称作“左子树”和“右子树”。二叉树的分支具有左右次序,不能颠倒。
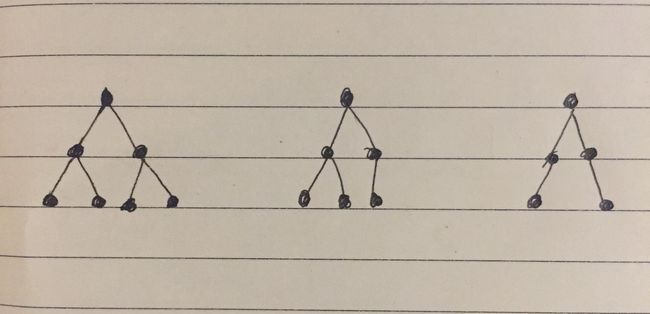
满足上面的都叫做二叉树,只要是两个叉的都叫二叉树。
满二叉树
只有叶子两边都长满了才叫做满二叉树,若是有一边只有一个叶子,都不能叫满二叉树。

完全二叉树
在一棵二叉树中,除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则此二叉树为完全二叉树。

简单概括就是只要其中有一边连续没长叶子都叫完全二叉树
堆排序
堆排序的可视化网站
什么是堆?只有每一个子节点的数字都小于其父节点的数字,满足这种条件的就叫做堆。
堆分为最大堆和最小堆,可以视为一棵完全的二叉树。以最大堆为例。最大堆要求父节点的元素都大于其孩子(子节点)。如果这个父节点的值要小于其左右子节点的值,那就要从其左右子节点中找出一个最大的值让它上浮顶替当前的父节点。而当前的父节点就下沉到之前子节点的位置。每一次排序都从最底层开始,自下而上的把每一个找到的最大堆值层层上浮,直到堆顶,然后取堆顶的值放到序列最后。依次类推,最终得到排序的序列。
关于堆排序的更详细说明
各种排序的复杂度:
