先简述一下,作为一个android开发狗,刚刚入坑hadoop对后台的IDEA开发不是很熟悉,按各网站上的描述搭建环境各种被坑,于是决定写一篇傻瓜式的安装windows+IDEA+Hadoop环境搭载及运行的文章。(忽略hadoop本身的环境配置和运行)
1.下载hadoop,IDEA,配置环境变量,hadoop的配置参数,添加winUtils.exe
1.1下载hadoop https://archive.apache.org/dist/hadoop/common/这个是hadoop的下载地址。选择自己的所在版本的下载地址笔者用的是2.5.0版本的文件。
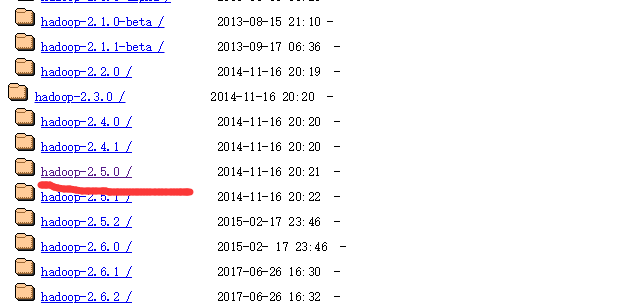
注意是下载其中的.tar.gz文件不带src,src只是其中一小部分资源文件

1.2下载IDEA,https://www.jetbrains.com/idea/download/#section=windows,笔者是下载IDEA专业版后用破解补丁破解的,毕竟社区版功能太少不够用的。顺便贴上破解教程地址https://mp.weixin.qq.com/s?__biz=MzI0OTc0MzAwNA==&mid=2247483806&idx=1&sn=5c60673c73fdd32b90776831123e9fd0&chksm=e98d926ddefa1b7b5dfd5bac3cb0d341a30afd3dac960059a97dca1a07f5701e0f78653281d4&scene=21#wechat_redirect
1.3.配置Hadoop环境变量,java的环境变量就不说了,毕竟学hadoop java基础肯定都是有的。将下载的压缩包用压缩工具解压到指定目录然后和java一样将hadoop的安装目录以HADOOP_HOME的形式配置到环境变量中,


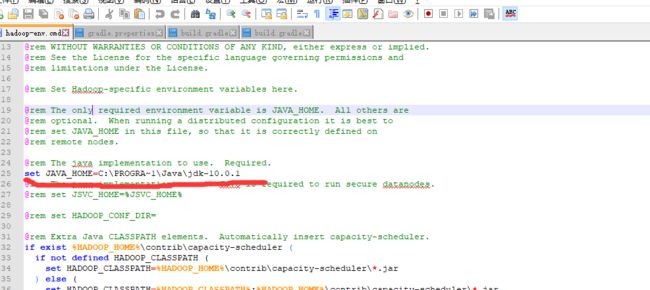
1.4.1配置环境参数,现在cmd命令行中输入hadoop,如果出现Error: JAVA_HOME is incorrectly set. Please update F:\hadoop\conf\hadoop-env.cmd类似的字样,请修改安装目录下的hadoop-env.cmd(关于路径如果这个文件在etc下,那便改etc目录的这个文件)为
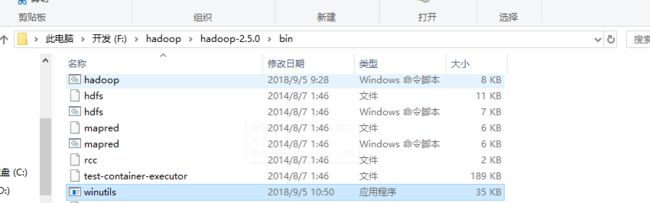
1.1.5因为我们将hadoop运行在windows上需要提供兼容,所以要添加winutils.exe文件到hadoop的bin目录下,这个是winutils.exe的下载地址 https://pan.baidu.com/s/1MLs2ic4KKeuQbjTgHG6P_w 密码:ihgu
2.创建MAVE项目,导入相应的依赖,配置Aritifact
2.1打开IDEA创建MAVEN项目



2.2导入hadoop相关的依赖
可以直接从hadoop的安装目录中的share包依赖所有jar
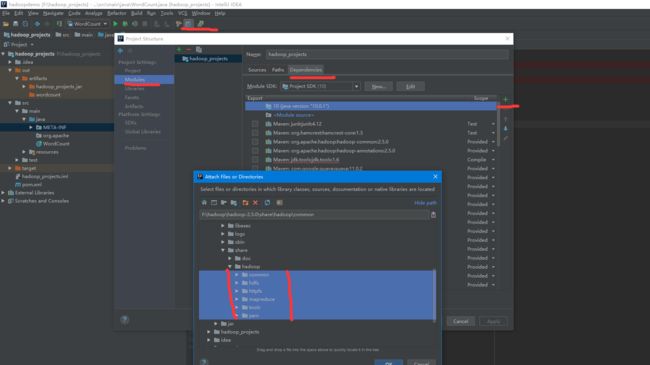
也可以通过maven直接添加
maven 依赖- 代码链接
不过即使依赖了share包,也需要在maven中依赖 log4j和slf4j库(在上面的代码链接中已给出,两个库是用来做hadoop的日志打 印的,如果没有依赖则运行时会报ClassNotFound异常)
然后在项目的resource目录下新建log4j.properties文件 进行如下配置
log4j.rootLogger = debug,stdout
### 输出信息到控制台 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
2.3配置artifact
如果没有配置artifact你运行mapreduce时,会在terminated中发现报MapClass,ReducerClass的not found异常,主要原因是要Hadoop运行mapreduce的时候是在指定jar包寻找mapClass和ReducerClass,所以我们需要在运行前先把代码打成jar,然后再运行
PS:配置artifact和打成jar,用hadoop命令运行不一样。继续往下看
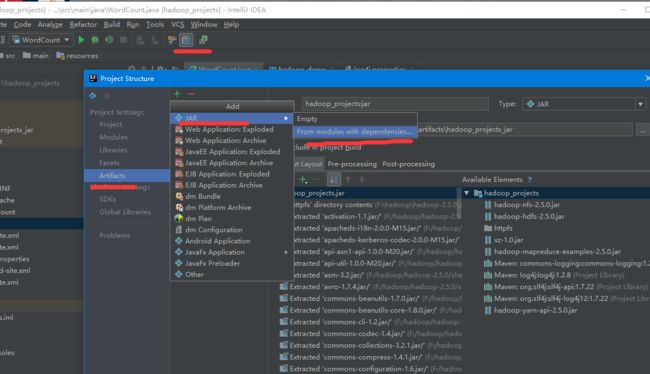
如上图所示,打开project structure,选择artifacts选项,点击加号,选择从现有的hadoop_module中导入生成的jar包配置
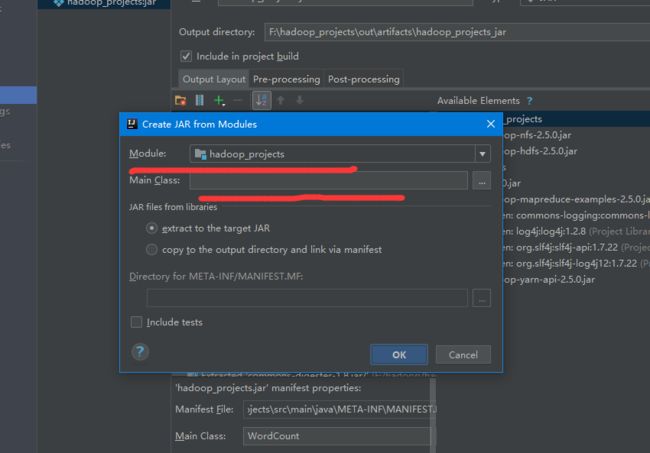
配置你运行mapreduce的main class和module
点击OK
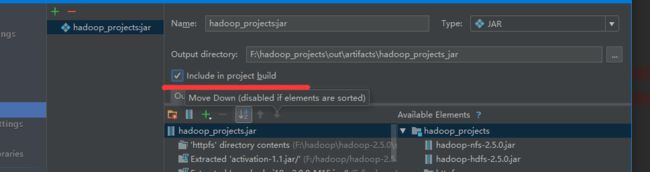
选中 include in project builde,这样就可以让你在run main class的时候,自动生成jar测试运行。
点击OK
然后在mapreduce类中加入如下代码
((JobConf)job.getConfiguration()).setJar("artifacts配置的jar包路径");
3.编写MapReducer类,笔者遇坑列举
3.1编写mapreducer类,关于mapreducer类,笔者在此不多缀述。
3.2笔者遇坑介绍
/bin/bash: line 0: fg: no job control当运行hadoop的时候出现这个错误,并且在historyserver上出现 mapreduce.Job: Job job_1386170530016_0001 failed with state FAILED due to: Application application_1386170530016_0001 failed 2 times due to AM Container for appattempt_1386170530016_0001_000002 exited with exitCode: 1 due to: Exception from container-launch: 这样的错误,
或者是遇到 hadoop_home_dir的not found 异常 (笔者原本以为这三个异常相互独立,后来才发现造成的原因一样) 主要原因是因为mapreduce运行时无法解析%JAVA_HOME%,%HADOOP_HOME%这样的环境参数所导致的,原本在2.2.0和2.3.0的版本解决方法为修改源码,但是2.5.0及以上版本,直接在创建job对象之后添加如下代码
conf.set("mapreduce.app-submission.cross-platform","true");
底层就会自动将%JAVA_HOME%,%HADOOP_HOME%转换成$JAVA_HOME,$HADOOP_HOME这样liunx环境下可读的环境变量