文前说明
作为码农中的一员,需要不断的学习,我工作之余将一些分析总结和学习笔记写成博客与大家一起交流,也希望采用这种方式记录自己的学习之旅。
本文仅供学习交流使用,侵权必删。
不用于商业目的,转载请注明出处。
1. 简介
- Fork/Join 框架是 JDK 1.7 提供的并行执行任务框架,这个框架通过(递归)把问题划分为子任务,然后并行的执行这些子任务,等所有的子任务都结束的时候,再合并最终结果的这种方式来支持并行计算编程。
- 总体的设计参考了为 Cilk 设计的 work-stealing 框架。
- Fork/Join 并行方式是获取良好的并行计算性能的一种最简单同时也是最有效的设计技术,是 分治算法(Divide-and-Conquer) 的并行版本。
- Fork 操作启动一个新的并行 Fork/Join 子任务。
- Join 操作一直等待直到所有的子任务都结束。
- Fork/Join 算法,如同其他分治算法一样,总是会递归的、反复的划分子任务,直到这些子任务可以用足够简单的、短小的顺序方法来执行。
2. 工作窃取(work-stealing)
- ForkJoin 框架的核心在于轻量级调度机制,使用了 工作窃取(Work-Stealing)所采用的基本调度策略。

work-stealing
- 每一个工作线程维护自己的调度队列中的可运行任务。
- 队列以双端队列的形式被维护。
- 支持后进先出 LIFO 的 push 和 pop 操作。
- 支持先进先出 FIFO 的 take 操作。
- 对于一个给定的工作线程来说,任务所产生的子任务将会被放入到工作者自己的双端队列中。
- 工作线程使用后进先出 LIFO(最新的元素优先)的顺序,通过弹出任务来处理队列中的任务。
- 当一个工作线程的本地没有任务去运行的时候,它将使用先进先出 FIFO 的规则尝试随机的从别的工作线程中拿(窃取)一个任务去运行。
- 当一个工作线程触及了 Join 操作,如果可能的话它将处理其他任务,直到目标任务被告知已经结束(通过
isDone()方法)。所有的任务都会 无阻塞 的完成。 - 当一个工作线程无法再从其他线程中获取任务和失败处理的时候,它就会退出并经过一段时间之后再度尝试直到所有的工作线程都被告知他们都处于空闲的状态。
- 在这种情况下,他们都会阻塞直到其他的任务再度被上层调用。
- 使用后进先出 LIFO 用来处理每个工作线程的自己任务,但是使用先进先出 FIFO 规则用于获取别的任务,这是一种被广泛使用的进行递归 Fork/Join 设计的一种调优手段。
- 让窃取任务的线程从队列拥有者相反的方向进行操作会减少线程竞争。
- 同样体现了递归分治算法的大任务优先策略。
- 更早期被窃取的任务有可能会提供一个更大的单元任务,从而使得窃取线程能够在将来进行递归分解。
- 对于一些基础的操作而言,使用相对较小粒度的任务比那些仅仅使用粗粒度划分的任务以及那些没有使用递归分解的任务的运行速度要快。尽管相关的少数任务在大多数的 Fork/Join 框架中会被其他工作线程窃取,但是创建许多组织良好的任务意味着只要有一个工作线程处于可运行的状态,那么这个任务就有可能被执行。
工作窃取算法的优点
- 利用了线程进行并行计算,减少了线程间的竞争。
工作窃取算法的缺点
- 如果双端队列中只有一个任务时,线程间会存在竞争。
- 窃取算法消耗了更多的系统资源,如会创建多个线程和多个双端队列。
3. ForkJoinPool
- ForkJoinPool 类是 Fork/Join 框架 的核心,和 ThreadPoolExecutor 一样是 ExecutorService 接口的实现类。
- ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。(见 Java Tip: When to use ForkJoinPool vs ExecutorService )

ForkJoinPool 类图
- ForkJoinPool 的两大核心就是 分而治之(Divide-and-Conquer)和工作窃取(Work-Stealing)算法。
- ForkJoinPool 最适合的是计算密集型的任务,如果存在 I/O,线程间同步,
sleep()等会造成线程长时间阻塞的情况时,最好配合使用 ManagedBlocker。
- ForkJoinPool 最适合的是计算密集型的任务,如果存在 I/O,线程间同步,
3.1 Fork/Join 框架的使用
- ThreadPoolExecutor 中每个任务都是由单个线程独立处理的,如果出现一个非常耗时的大任务(比如大数组排序),就可能出现线程池中只有一个线程在处理这个大任务,而其他线程却空闲着,这会导致 CPU 负载不均衡,空闲的处理器无法帮助工作繁忙的处理器。
- ForkJoinPool 可以用来解决这种问题,将一个大任务拆分成多个小任务后,使用 Fork 可以将小任务分发给其他线程同时处理,使用 Join 可以将多个线程处理的结果进行汇总。
问题
- 计算 1 至 1000 的正整数之和。
解决方法
- 通过 ExecutorService 实现。
public class ExecutorServiceCalculator implements Calculator {
private int parallism;
private ExecutorService pool;
public ExecutorServiceCalculator() {
parallism = Runtime.getRuntime().availableProcessors(); // CPU的核心数
pool = Executors.newFixedThreadPool(parallism);
}
private static class SumTask implements Callable {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
@Override
public Long call() throws Exception {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
}
}
@Override
public long sumUp(long[] numbers) {
List> results = new ArrayList<>();
// 把任务分解为 n 份,交给 n 个线程处理
int part = numbers.length / parallism;
for (int i = 0; i < parallism; i++) {
int from = i * part;
int to = (i == parallism - 1) ? numbers.length - 1 : (i + 1) * part - 1;
results.add(pool.submit(new SumTask(numbers, from, to)));
}
// 把每个线程的结果相加,得到最终结果
long total = 0L;
for (Future f : results) {
try {
total += f.get();
} catch (Exception ignore) {}
}
return total;
}
}
- 通过 ForkJoinPool 实现。
public class ForkJoinCalculator implements Calculator {
private ForkJoinPool pool;
private static class SumTask extends RecursiveTask {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
@Override
protected Long compute() {
// 当需要计算的数字小于6时,直接计算结果
if (to - from < 6) {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
// 否则,把任务一分为二,递归计算
} else {
int middle = (from + to) / 2;
SumTask taskLeft = new SumTask(numbers, from, middle);
SumTask taskRight = new SumTask(numbers, middle+1, to);
taskLeft.fork();
taskRight.fork();
return taskLeft.join() + taskRight.join();
}
}
}
public ForkJoinCalculator() {
// 也可以使用公用的 ForkJoinPool:
// pool = ForkJoinPool.commonPool()
pool = new ForkJoinPool();
}
@Override
public long sumUp(long[] numbers) {
return pool.invoke(new SumTask(numbers, 0, numbers.length-1));
}
}
- 使用了 ForkJoinPool 的实现逻辑全部集中在
compute()函数中,代码中没有显式地把任务分配给线程,只是分解了任务,而把具体的任务到线程的映射都交给了 ForkJoinPool 来完成。
3.2 Fork/Join 框架的原理
ForkJoinPool
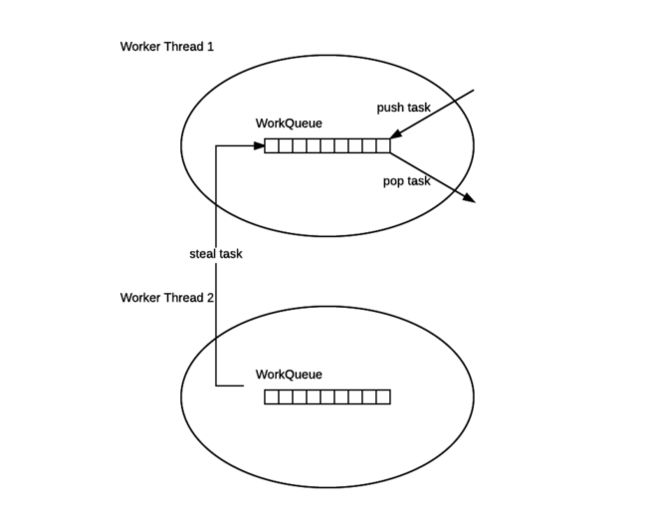
- ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
- 每个工作线程在运行中产生新的任务(通常是因为调用了
fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。 - 每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
- 在遇到
join()时,如果需要 Join 的任务尚未完成,则会先处理其他任务,并等待其完成。 - 在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
- 每个工作线程在运行中产生新的任务(通常是因为调用了
ForkJoinPool
- ForkJoinPool 是用于执行 ForkJoinTask 任务的执行池,不再是传统执行池 Worker+Queue 的组合模式,而是维护了一个队列数组 WorkQueue(WorkQueue[]),这样在提交任务和线程任务的时候大幅度的减少碰撞。
WorkQueue
- WorkQueue 是双向列表,用于任务的有序执行,如果 WorkQueue 用于自己的执行线程 Thread,线程默认将会从尾端选取任务用来执行 LIFO。
- 每个 ForkJoinWorkThread 都有属于自己的 WorkQueue,但不是每个 WorkQueue 都有对应的 ForkJoinWorkThread。
- 没有 ForkJoinWorkThread 的 WorkQueue 保存的是 submission,来自外部提交,在 WorkQueue[] 的下标是 偶数 位。
ForkJoinWorkThread
- ForkJoinWorkThread 是用于执行任务的线程,用于区别使用非 ForkJoinWorkThread 线程提交的 task。启动一个该 Thread,会自动注册一个 WorkQueue 到 Pool,拥有 Thread 的 WorkQueue 只能出现在 WorkQueue[] 的 奇数 位。

work-stealing
ForkJoinTask
- ForkJoinTask 是任务,它比传统的任务更加轻量,不再是 Runnable 的子类,提供 Fork/Join 方法用于分割任务以及聚合结果。
fork 方法
-
fork()做的工作只有一件事,既是把任务推入当前工作线程的工作队列里。
public final ForkJoinTask fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
join 方法
-
join()的工作则复杂得多,也是它可以使得线程免于被阻塞的原因。- 检查调用
join()的线程是否是 ForkJoinThread 线程。如果不是(例如 main 线程),则阻塞当前线程,等待任务完成。如果是,则不阻塞。 - 查看任务的完成状态,如果已经完成,直接返回结果。
- 如果任务尚未完成,但处于自己的工作队列内,则完成它。
- 如果任务已经被其他的工作线程偷走,则窃取这个小偷的工作队列内的任务(以 FIFO 方式)执行,以期帮助它早日完成预 join 的任务。
- 如果偷走任务的小偷也已经把自己的任务全部做完,正在等待需要 Join 的任务时,则找到小偷的小偷,帮助它完成它的任务。
- 递归地执行第 5 步。
- 检查调用

join 方法的流程
- 除了每个工作线程自己拥有的工作队列以外,ForkJoinPool 自身也拥有工作队列,这些工作队列的作用是用来接收由外部线程(非 ForkJoinThread 线程)提交(submit)过来的任务,而这些工作队列被称为 submitting queue。
-
submit()和fork()其实没有本质区别,只是提交对象变成了 submitting queue 而已(还有一些同步,初始化的操作)。submitting queue 和其他 work queue 一样,是工作线程 " 窃取 " 的对象,因此当其中的任务被一个工作线程成功窃取时,就意味着提交的任务真正开始进入执行阶段。
-
- ForkJoinPool 有一个 Async Mode ,效果是工作线程在处理本地任务时也使用 FIFO 顺序。这种模式下的 ForkJoinPool 更接近于是一个消息队列,而不是用来处理递归式的任务。
- 在需要阻塞工作线程时,可以使用 ManagedBlocker。
- JDK 1.8 新增加的 CompletableFuture 类可以实现类似于 Javascript 的 promise-chain,内部就是使用 ForkJoinPool 来实现的。
3.2.1 ForkJoinPool
- 作为框架的提交入口,ForkJoinPool 管理着线程池中线程和任务队列,标识线程池是否还接收任务,显示现在的线程运行状态。
// 低位和高位掩码
private static final long SP_MASK = 0xffffffffL;
private static final long UC_MASK = ~SP_MASK;
// 活跃线程数
private static final int AC_SHIFT = 48;
private static final long AC_UNIT = 0x0001L << AC_SHIFT; //活跃线程数增量
private static final long AC_MASK = 0xffffL << AC_SHIFT; //活跃线程数掩码
// 工作线程数
private static final int TC_SHIFT = 32;
private static final long TC_UNIT = 0x0001L << TC_SHIFT; //工作线程数增量
private static final long TC_MASK = 0xffffL << TC_SHIFT; //掩码
private static final long ADD_WORKER = 0x0001L << (TC_SHIFT + 15); // 创建工作线程标志
// 池状态
private static final int RSLOCK = 1;
private static final int RSIGNAL = 1 << 1;
private static final int STARTED = 1 << 2;
private static final int STOP = 1 << 29;
private static final int TERMINATED = 1 << 30;
private static final int SHUTDOWN = 1 << 31;
// 实例字段
volatile long ctl; // 主控制参数
volatile int runState; // 运行状态锁
final int config; // 并行度|模式
int indexSeed; // 用于生成工作线程索引
volatile WorkQueue[] workQueues; // 主对象注册信息,workQueue
final ForkJoinWorkerThreadFactory factory;// 线程工厂
final UncaughtExceptionHandler ueh; // 每个工作线程的异常信息
final String workerNamePrefix; // 用于创建工作线程的名称
volatile AtomicLong stealCounter; // 偷取任务总数,也可作为同步监视器
/** 静态初始化字段 */
//线程工厂
public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory;
//启动或杀死线程的方法调用者的权限
private static final RuntimePermission modifyThreadPermission;
// 公共静态pool
static final ForkJoinPool common;
//并行度,对应内部common池
static final int commonParallelism;
//备用线程数,在tryCompensate中使用
private static int commonMaxSpares;
//创建workerNamePrefix(工作线程名称前缀)时的序号
private static int poolNumberSequence;
//线程阻塞等待新的任务的超时值(以纳秒为单位),默认2秒
private static final long IDLE_TIMEOUT = 2000L * 1000L * 1000L; // 2sec
//空闲超时时间,防止timer未命中
private static final long TIMEOUT_SLOP = 20L * 1000L * 1000L; // 20ms
//默认备用线程数
private static final int DEFAULT_COMMON_MAX_SPARES = 256;
//阻塞前自旋的次数,用在在awaitRunStateLock和awaitWork中
private static final int SPINS = 0;
//indexSeed的增量
private static final int SEED_INCREMENT = 0x9e3779b9;
ForkJoinPool 对象
- 使用 Executors 工具类创建。
// parallelism 定义并行级别
public static ExecutorService newWorkStealingPool(int parallelism);
// 默认并行级别为 JVM 可用的处理器个数
// Runtime.getRuntime().availableProcessors()
public static ExecutorService newWorkStealingPool();
- 使用 ForkJoinPool 内部已经初始化好的 commonPool 方法创建。
// 类静态代码块中会调用makeCommonPool方法初始化一个commonPool
public static ForkJoinPool commonPool() {
// assert common != null : "static init error";
return common;
}
- common 在 static{} 里创建,调用的是
makeCommonPool(),最终调用 ForkJoinPool 的构造函数。
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
int mode,
String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
参数说明
| 类型及其修饰符 | 变量名 | 作用 |
|---|---|---|
| volatile long | ctl | 主控制参数,分为 4 个区域保存(每 16 位为 1 个区域)。 |
| volatile int | runState | 保存线程池的 运行状态。 |
| final int | config | 保存线程池的 最大线程数量 及其 是否采用了公平模式。 |
| int | indexSeed | 用于在构造 WorkQueue 时计算插入到 workQueues 的下标。 |
| volatile WorkQueue[] | workQueues | 线程池持有的工作线程(即执行任务的线程)。 |
| final ForkJoinWorkerThreadFactory | factory | 该线程池指定的线程工厂,用于生产 ForkJoinWorkerThread 对象。 |
| final String | workerNamePrefix | 该线程池中工作线程的名称前缀。 |
| volatile AtomicLong | stealCounter | 该线程池中所有的 WorkQueue 总共被窃取的任务数量。 |
ctl 变量说明
- ctl 是 ForkJoinPool 中最主控制参数字段,按 16 位 为一组封装在一个 long 中,共 64 位。
- ctl 变量区域如下表(表 1)所示。
| 区域 | 属性 | 说明 |
|---|---|---|
| 1 | AC | 正在运行工作线程数减去目标并行度,高 16 位。(49-64 位) |
| 2 | TC | 总工作线程数减去目标并行度,中高 16 位。(33-48 位) |
| 3 | SS | 栈顶等待线程的版本计数和状态,中低 16 位。(17-32 位) |
| 4 | ID | 栈顶 WorkQueue 在池中的索引(poolIndex),低 16 位。(1-16 位) |
- ctl 的低 32 位其实只能表示一个等待(空闲)线程,低 32 位标识的是栈顶的那个,能从栈顶中的变量 stackPred 追踪到下一个等待(空闲)线程。
- AC 和 TC 初始化时取的是 parallelism 负数,后续代码可以直接判断正负,为负代表还没有达到目标数量(阈值)。
- 可以通过 ctl 的低 32 位
sp=(int)ctl来检查工作线程状态。当 sp 为 0 时说明此刻 没有已经启动但是空闲的线程。 - 当 ctl<0 意味着 active 的线程还没有到达阈值。
线程池状态(runState )说明
// runState bits: SHUTDOWN must be negative, others arbitrary powers of two
private static final int RSLOCK = 1;
private static final int RSIGNAL = 1 << 1;
private static final int STARTED = 1 << 2;
private static final int STOP = 1 << 29;
private static final int TERMINATED = 1 << 30;
private static final int SHUTDOWN = 1 << 31;
- 线程池状态的变化,记录字段位 runState。使用 bit 位来标识不同状态。
- runState 记录了 ForkJoinPool 的运行状态,除了 SHUTDOWN 是负数,其他都是正数。
- 多线程环境修改 runState,需要先获取锁,RSLOCK 和 RSIGNAL 在这里被使用。
private int lockRunState() {
int rs;
return ((((rs = runState) & RSLOCK) != 0 ||
!U.compareAndSwapInt(this, RUNSTATE, rs, rs |= RSLOCK)) ?
awaitRunStateLock() : rs);
}
- 如果执行 runState & RSLOCK ==0 就直接说明目前的运行状态没有被 锁住,其他情况类似。
config 变量
- config 负责保存最大的线程数量以及公平模式,config 为 int 类型(32 位),前 16 位(低 16 位)保存最大线程数量,第 17 位(高 16 位)为 1 时,代表公平模式(FIFO_QUEUE),为 0 时代表非公平模式(LIFO_QUEUE)。
static final int SMASK = 0xffff; // short bits == max index
static final int LIFO_QUEUE = 0;
static final int FIFO_QUEUE = 1 << 16;
this.config = (parallelism & SMASK) | mode;
WorkQueue 对象
- WorkQueue 是一个双端队列,定义在 ForkJoinPool 类里。

WorkQueue
| 类型及其修饰符 | 变量名 | 作用 |
|---|---|---|
| volatile int | scanState | 保存这个 WorkQueue 的类型,线程是否繁忙(仅限 ACTIVE 类型)。 |
| int | stackPred | 记录前驱 worker 的下标。 |
| int | nsteals | 该 WorkQueue 被窃取的任务的总数。 |
| int | hint | 用于窃取线程计算下次窃取的 workQueues 数组的下标。 |
| int | config | 前 16 位(低 16 位)保存该 WorkQueue 在 workQueues 数组的下标,第 17 位(高 16 位)保存属于 LIFO 还是 FIFO 模式。 |
| volatile int | qlock | 一个简单的锁,0 表示为加锁,1 表示已加锁,小于 0 表示当前 WorkQueue 已停止。 |
| ForkJoinTask[] | array | 任务队列,保存 ForkJoinTask 任务对象。 |
| volatile int | base | bash 与 workQueues 数组长度取模的值窃取线程下次从 workQueues 数组取出任务的下标。 |
| int | top | top 与 workQueues 数组长度取模的值即为下次将任务对象插入到 workQueues 数组的下标。 |
| final ForkJoinPool | pool | 该 WorkQueue 对应的线程池。 |
| final ForkJoinWorkerThread | owner | 该 WorkQueue 对应的工作线程对象(ACTIVE 类型的 WorkQueue 不会为 null)。 |
| volatile Thread | parker | 当 currentThread 被 park(等待)时,用来保存这个线程对象来后续 unpark。 |
| ForkJoinTask | currentJoin | 调用 join 方法时等待结果的任务对象。 |
| ForkJoinTask | currentSteal | 保存正在执行的从别的 WorkQueue 窃取过来的任务。 |
WorkQueue 当前状态(scanState)
static final int SCANNING = 1; // false when running tasks
static final int INACTIVE = 1 << 31; // must be negative
static final int SS_SEQ = 1 << 16;
- scanState 描述 WorkQueue 当前状态。
- 高 16 位中,最高位表示 WorkQueue 属于 ACTIVE 还是 INACTIVE 类型,当最高位为 0 时表示 ACTIVE 类型,为 1 时表示 INACTIVE 类型。
- 还保存了这个 WorkQueue 对应的线程是否正在执行任务(仅 ACTIVE 类型)。
- 低 16 位中,保存了这个 WorkQueue 在数组 workQueues 中的下标。
WorkQueue 锁标识(qlock)
- 操作 WorkQueue 前需要锁定,记录在字段 qlock。
- 1 锁定。
- 0 未锁定。
- 负数,对应的 worker 已经撤销注册,WorkQueue 终止使用。
config
- WorkQueue 的 config 记录了在 WorkQueue[] 的下标和当前 mode。
- 如果有自己的 owner 默认是 LIFO。
- 下面代码中的 config 是 ForkJoinPool 的 config,与 WorkQueue 的 w.config 不是相同变量。
static final int MODE_MASK = 0xffff << 16; // top half of int
int mode = config & MODE_MASK;
w.config = i | mode;
top 和 base
- base 是 work-steal 的偏移量,因为其他的线程都可以 窃取 该队列的任务,所以 base 使用 volatile 标识。
- 因为只有 owner 的 Thread 才能从 top 端取任务,所以在设置变量时,
int top不需要使用 volatile。 - WorkQueue 的任务队列是一个数组实现的双端队列,其 top%workQueues.length 的值代表新任务插入到 workQueues 数组的位置,bash%workQueues.length 的值代表窃取线程从 workQueues 数组取出任务的下标。
- 在构造 WorkQueue 时,base 和 top 的值相等并且值为 4096(默认 array 数组的长度为 8192),当 array 数组容量不够时,会调用 growArray 进行扩容,扩容后的数组长度为原先的 2 倍大小。
static final int INITIAL_QUEUE_CAPACITY = 1 << 13;
base = top = INITIAL_QUEUE_CAPACITY >>> 1;
stackPred
- stackPred 用于维护一个存储空闲线程的栈(也可看成是一个单向链表),该变量的值代表前面一个空闲线程在 workQueues 数组的下标。其栈顶的空闲线程下标存储在 ForkJoinPool 的变量 ctl 中低16 位,第 17 位保存该空闲线程是 ACTIVE 类型还是 INACTIVE 类型。
接下一篇 【Java 并发笔记】Fork/Join 框架相关整理(下)