论文提出MetaQNN,基于Q-Learning的神经网络架构搜索,将优化视觉缩小到单层上,相对于Google Brain的NAS方法着眼与整个网络进行优化,虽然准确率差了2~3%,但搜索过程要简单地多,所以才能仅用100GPU days就可以完成搜索,加速240倍。论文本身是个很初期的想法,可以看到搜索出来的网络结构还是比较简单的,也需要挺多的人工约束。整体而言,论文的输出的搜索思想还是很重要的,有很多参考的地方
来源:晓飞的算法工程笔记 公众号
论文: Designing Neural Network Architectures using Reinforcement Learning

- 论文地址:https://arxiv.org/abs/1611.02167
Introduction

论文提出MetaQNN算法,使用基于强化学习的meta-modeling procedure来自动化CNN结构搭建过程。该方法首先搭建一个全新的Q-learning代理,学习如何发现性能好的CNN结构,发现过程先按顺序选择网络每层的参数,然后对搜索到的网络进行训练和测试,并将测试准确率作为reward,在学习过程中使用了经验回放(experience replay)进行加速
Background
将代理学习最优路径的任务为有限环境(finite-horizon)内的马尔可夫决策过程(Markov Decision Process, MDP),将环境限制为有限的能够保证代理在一定time step后停止。限制离散的有限状态空间$\mathcal{S}$以及动作空间$\mathcal{U}$,对于状态$s_i \in S$,存在可供代理选择的选择的动作集$\mathcal{U}(s_i)\in \mathcal{U}$。由于环境的随机转移性,状态$s_i$选择动作$u\in \mathcal{U}(s_i)$转移到$s_j$的概率为$p_{s^{'}|s,u()}(s_j|s_i,u)$,这可能是代理未知的。在每个time step $t$时,代理的reward $r_t$可能也是随机的,由状态$s$转移到$s\prime$以及动作$u$的概率$p_{s\prime|s,u}(s_j|s_i,u)$决定
![]()
代理的目标是最大化所有可能路径的期望reward,即${\max}_{\mathcal{T}i \in \mathcal{T}}R{\mathcal{T}}$,单个路径的reward计算如公式1
![]()
尽管限制了状态空间和动作空间,代理仍然能组合出大量的路径,所以用强化学习来进行优化。将最大化问题迭代成多个子问题,优化每个子问题到最优解。对于状态$s_i\in S$以及后续动作$u\in \mathcal{U}(s_i)$,定义最大化期望reward为$Q*(s_i,u)$,$Q(\cdot)$为action-value函数,单个$Q^(s_i,u)$称为Q-values,Q-values的最优解为公式2,即Bellman’s Equation,为当前动作的回报的期望与下个状态的Q值最大的动作的加权求和
![]()
一般不能直接学习到概率来求解Bellman’s Equation,可以转化为迭代式优化,如公式3,为Q-learning的一种简单形式。只要每种转移采样足够多次${\lim}_{t\to \infty}Q_t(s,u)=Q^*(s_i,u)$,就可以很好地逼近公式2,更新公式包含两个参数:
- $\alpha$为Q-learning rate,决定新信息对旧信息的权重
- $\gamma$为折扣率(discount factor), 决定短期reward对于长期reward的权重
Q-learning是model-free的,代理的学习过程不用构造环境变量的估计,也是off policy的,意味着可以在非最优的整体行为分布下依然可以学习到最优的策略。论文使用$\epsilon$-greedy策略,以概率$\epsilon$选取随机动作,以概率$1-\epsilon$选取贪婪动作${\max}_{u\in \mathcal{U}(s_i)}Q_t(s_i, u)$,将$\epsilon$逐渐从1降为0,这样代理能从探索(exploration)阶段慢慢变为榨取(exploitation)阶段。由于探索阶段花费较大,所以使用经验回放来加速收敛,使用记录探索的路径和reward给予代理进行公式3学习
Designing Neural Network Architectures with Q-learning
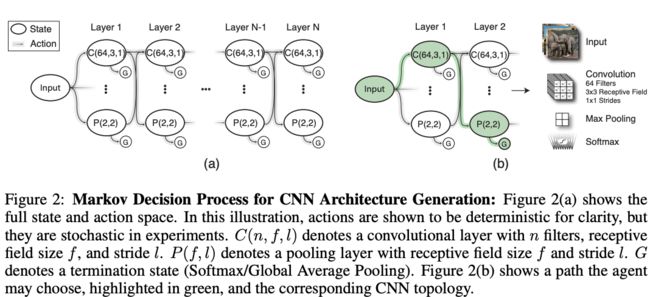
代理的学习任务即按顺序地选取神经网络层,图2(a)展示了灵活的状态空间和动作空间,图2(b)则为代理可能选择的潜在路径并用该路径构造网络
将层选择过程建模为马尔可夫决策过程,假设一个网络中表现好的层也能在别的网络中有很好的表现。代理按顺序通过$\epsilon$-greedy策略进行选择直到达到停止状态,从代理的路径中构建CNN网络,然后进行训练并将准确率反馈给代理,将准确率和网络存到回放存储(replay memory)中,定期从回放存储中采样进行公式3的Q-values更新
MetaQNN主要包含三个设计理念:
- 减少CNN层定义来简化状态参数
- 定义代理可选择的动作集,用以状态转移
- 平衡state-action空间大小和模型容量的关系,代理需要大量探索进行收敛
The State Space

每个状态为一组层相关参数,如表1所示,共有6种层类型,网络每层都预有一个layer depth来表示当前层的位置,从而进行action的约束,保证网络为有向无环图(DAG)
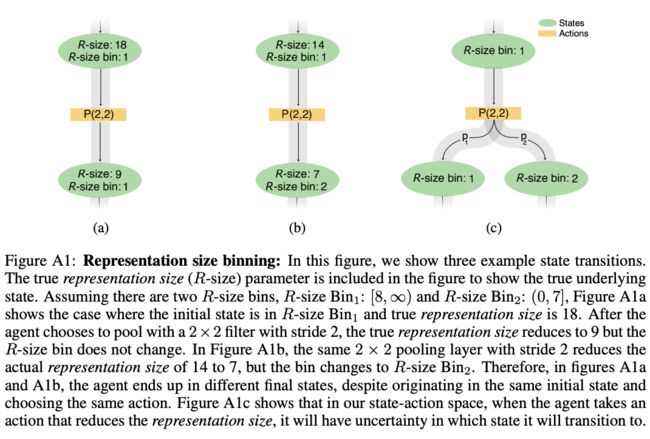
为了避免感受域大于特征图大小,每层有一个representation size(R-size),为特征图大小,根据R-size进行两个action的约束,限制R-size为n的状态的action的感受域必须小于或等于n来保证输出不会太小,而为了更好的约束,将R-size值分为3个离散区间,但这有可能导致生成的状态在另一个不同的区间,如图A1所示
The Action Space
对代理的动作进行了限制,从而约束state-action空间大小和简化学习过程:
- 允许代理在任何节点终止,可以从非终止状态直接转移到终止状态。另外,只允许层$i$转移到层$i+1$,保证无环,最大层仅能转移为终止层
- 限制全连接层的数量最多为两层,防止参数过多,另外全连接层转移到全连接层必须满足consecutive FC的限制,而且全连接层只能转移为neurons不大于转移前的全连接层或终止状态
- 卷积状态能转移到其它任何状态,而池化状态只能转移到非池化状态,只有Representation size为$[8,4)$和(4,1]的层能转移到全连接层
Q-Learning Training Procedure

设置公式3的Q-Learning rate($\alpha$)为0.001,discount factor($\gamma$)为1,$\epsilon$的下降如表2,在$\epsilon=1$的探索阶段训练大量的网络,其它值则保证代理在压榨前有充足的时间来继续探索,在$\epsilon=0.1$时停止

在整个训练过程使用回放字典(replay dictionary)存放网络结构及其测试的准确率,如果采样的网络有已经测试过的,则直接拿之前的准确率,不再重新训练,在当前批次网络采样和训练完后,从回放字典中随机选取100个网络对所有转移的进行公式3的Q-value更新,更新顺序以时间倒序先对后面的Q-value进行更新
Result
共使用10GPU训练8-10天,从所有模型中选取10个进行更长时间的训练
Model Selection Analysis

Prediction Performance
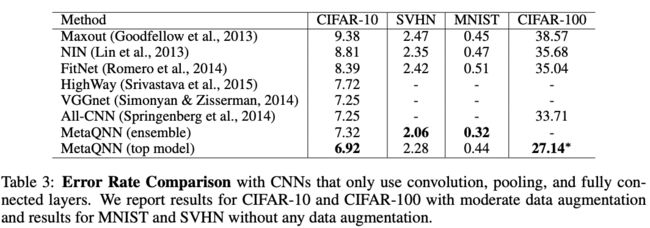
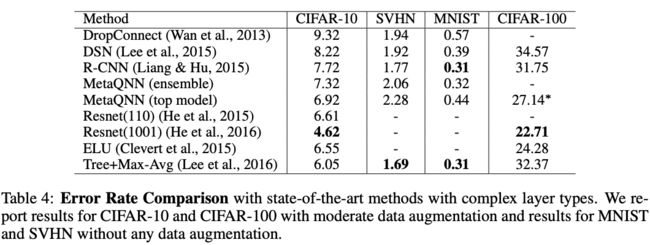

CONCLUSION
论文提出MetaQNN,基于Q-Learning的神经网络架构搜索,将优化视觉缩小到单层上,相对于Google Brain的NAS方法着眼与整个网络进行优化,虽然准确率差了2~3%,但搜索过程要简单地多,所以才能仅用100GPU days就可以完成搜索,加速240倍。但论文本身是个很初期的想法,可以看到搜索出来的网络结构还是比较简单的,没有残差连接和并行层,也需要挺多的人工约束。整体而言论文的输出的搜索思想还是很重要的,有很多参考的地方
APPENDIX E -- Top Topologies Selected by Algorithm


如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
