此指南适用于那些曾经或现在进行Android应用的基础开发,并希望了解和学习编写Android程序的最佳实践和架构。通过学习来构建强大的生产级别的应用。
注意:此指南默认你对Android开发有比较深的理解,熟知Android Framework。如果你还只是个Android开发新手,那么建议先学习下Android的基础知识。
Android程序员面临的问题
传统的桌面应用程序开发在大多数情况下,启动器快捷方式都有一个入口点,并作为一个单一的过程运行,但Android应用程序的结构更为复杂。典型的Android应用程序由多个应用程序组件构成,包括Activity,Fragment,Service,ContentProvider和Broadcast Receiver。
大多数这些应用程序组件在Android操作系统使用的AndroidManifest中声明,以决定如何将应用程序集成到设备上来为用户提供完整的体验。尽管如前所述,桌面应用程序传统上是作为一个单一的进程运行的,但正确编写的Android应用程序则需要更灵活,因为用户通过设备上的不同应用程序编织方式,不断切换流程和任务。
举个例子,当用户在社交App上打算分享一张照片,那么Android系统就会为此启动相机来完成此次请求。此时用户离开了社交App,但是这个用户体验是无缝连接的。相机可能又会触发并启动文件管理器来选择照片。最终回到社交App并分享照片。此外,在此过程中的任何时候,用户可能会被打电话中断,并在完成电话后再回来分享照片。
在Android中,这种应用间跳转行为很常见,因此你的应用必须正确处理这些流程。请记住,移动设备是资源有限的,所以在任何时候,操作系统可能需要杀死一些应用来为新的应用腾出空间。
你的应用程序的所有组件都可以被单独启动或无序启动,并且在任何时候由用户或系统销毁。因为应用程序组件是短暂的,它们的生命周期(创建和销毁时)不受你的控制,因此你不应该将任何应用程序数据或状态存储在应用程序组件中,并且应用程序组件不应相互依赖。
常见的架构原理
如果你无法使用应用程序组件来存储应用程序数据和状态,应如何构建应用程序?
在你的App开发中你应该将重心放在分层上,如果将所有的代码都写在Activity或者Fragment中,那问题就大了。任何不是处理UI或跟操作系统交互的操作不应该放在这两个类中。尽量保持它们代码的精简,这样你可以避免很多与生命周期相关的问题。记住你并不能掌控Activity和Fragment,他们只是在你的App和Android系统间起了桥梁的作用。任何时候,Android系统可能会根据用户操作或其他因素(如低内存)来回收它们。最好尽量减少对他们的依赖,以提供坚实的用户体验。
还有一点比较重要的就是持久模型驱动UI。使用持久模型主要是因为当你的UI被回收或者在没有网络的情况下还能正常给用户展示数据。模型是用来处理应用数据的组件,它们独立于应用中的视图和四大组件。因此模型的生命周期必然和UI是分离的。保持UI代码的整洁,会让你能更容易的管理和调整UI。让你的应用基于模型开发可以很好的管理你应用的数据并是你的应用更具测试性和持续性。
应用架构推荐
回到这篇文章的主题,来说说Android官方架构组件(一下简称架构)。一下会介绍如何在你的应用中实践这一架构模式。
注意:不可能存在某一种架构方式可以完美适合任何场景。话虽如此,这种架构应该是大多数用例的良好起点。如果你已经有了很好的Android应用程序架构方式,请继续保持。
假设我们需要一个现实用户资料的UI,该用户的资料文件将使用REST API从服务端获取。
构建用户界面
我们的这个用户界面由一个UserProfileFragment.java文件和它的布局文件user_profile_layout.xml。
为了驱动UI,数据模型需要持有下面两个数据:
- User ID:用户的标识符。最好使用Fragment的参数将此信息传递到Fragment中。如果Android操作系统回收了Fragment,则会保留此信息,以便下次重新启动应用时,该ID可用。
- User Object:传统的Java对象,代表用户的数据。
为此,我们新建一个继承自ViewModel的名为UserProfileViewModel的模型来持有这个数据。
ViewModel提供特定UI组件的数据,例如Activity和Fragment,并处理与数据处理业务部分的通信,例如调用其他组件来加载数据或转发用户修改。ViewModel不了解View,并且不受UI的重建(如重由于旋转而导致的Activity的重建)的影响。
现在我们有一下三个文件:
- user_profile.xml: 视图的布局文件。
- UserProfileViewModel.java: 持有UI数据的模型。
- UserProfileFragment.java: 用于显示数据模型中的数据并和用户进行交互。
一下是具体代码(为了简化,布局文件省略)。
public class UserProfileViewModel extends ViewModel {
private String userId;
private User user;
public void init(String userId) {
this.userId = userId;
}
public User getUser() {
return user;
}
}
public class UserProfileFragment extends LifecycleFragment {
private static final String UID_KEY = "uid";
private UserProfileViewModel viewModel;
@Override
public void onActivityCreated(@Nullable Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
String userId = getArguments().getString(UID_KEY);
viewModel = ViewModelProviders.of(this).get(UserProfileViewModel.class);
viewModel.init(userId);
}
@Override
public View onCreateView(LayoutInflater inflater,
@Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {
return inflater.inflate(R.layout.user_profile, container, false);
}
}
注意:上面的UserProfileFragment继承自LifeCycleFragment而不是Fragment。当Lifecycle的Api稳定后,Fragment会默认实现LifeCycleOwner。
现在,我们有三个文件,我们如何连接它们?毕竟,当ViewModel的用户字段被设置时,我们需要一种通知UI的方法。这里就要提到LiveData了。
LiveData是一个可观察的数据持有者。它允许应用程序中的组件观察LiveData对象持有的数据,而不会在它们之间创建显式和刚性的依赖路径。LiveData还尊重你的应用程序组件(Activity,Fragment,Service)的生命周期状态,并做正确的事情以防止内存泄漏,从而你的应用程序不会消耗更多的内存。
如果你已经使用了想Rxjava活着Agrea这类第三方库,那么你可以使用它们代替LiveData,不过你需要处理好它们与组件生命周期之间的关系。
现在我们使用LiveData来代替UserProfileViewModel中的User字段。所以Fragment可以通过观察它来更新数据。LiveData值得称道的地方就在于它是生命周期感知的,当生命周期结束是,其上的观察者会被即使清理。
public class UserProfileViewModel extends ViewModel {
...
private LiveData user;
public LiveData getUser() {
return user;
}
}
然后将UserProfileFragment修改如下,观察数据并更新UI:
@Override
public void onActivityCreated(@Nullable Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
viewModel.getUser().observe(this, user -> {
// update UI
});
}
一旦用户数据更新,onChanged回调将被调用然后UI会被刷新。
如果你熟悉一些使用观察者模式第三方库,你会觉得奇怪,为什么没有在Fragment的onStop()方法中将观察者移除。对于LiveData来说这是没有必要的,因为它是生命周期感知的,这意味着如果UI处于不活动状态,它就不会调用观察者的回调来更新数据。并且在onDestroy后会自动移除。
我们也不需要处理任何视图重建(如屏幕旋转)。ViewModel会自动恢复重建前的数据。当新的视图被创建出来后,它会接收到与之前相同的ViewModel实例,并且观察者的回调会被立刻调用,更新最新的数据。这也是ViewModel为什么不能直接引用视图对象,因为它的生命周期长于视图对象。
获取数据
现在我们将视图和模型连接起来,但是模型该怎么获取数据呢?在这个例子中,我们假设使用REST API从后台获取。我们将使用Retrofit来向后台请求数据。
我们的retrofit类Webservice如下:
public interface Webservice {
/**
* @GET declares an HTTP GET request
* @Path("user") annotation on the userId parameter marks it as a
* replacement for the {user} placeholder in the @GET path
*/
@GET("/users/{user}")
Call getUser(@Path("user") String userId);
}
如果只是简单的实现,ViewModel可以直接操作Webservice来获取用户数据。虽然这样可以正常工作,但你的应用无法保证它的后续迭代。因为这样做将太多的责任让ViewModel来承担,这样就违反类之前讲到的分层原则。又因为ViewModel的生命周期是绑定在Activity和Fragment上的,所以当UI被销毁后如果丢失所有数据将是很差的用户体验。所以我们的ViewModel将和一个新的模块进行交互,这个模块叫Repository。
Repository模块负责处理数据。它为应用程序的其余部分提供了一个干净的API。他知道在数据更新时从哪里获取数据和调用哪些API调用。你可以将它们视为不同数据源(持久性模型,Web服务,缓存等)之间的中介者。
UserRepository类如下:
public class UserRepository {
private Webservice webservice;
// ...
public LiveData getUser(int userId) {
// This is not an optimal implementation, we'll fix it below
final MutableLiveData data = new MutableLiveData<>();
webservice.getUser(userId).enqueue(new Callback() {
@Override
public void onResponse(Call call, Response response) {
// error case is left out for brevity
data.setValue(response.body());
}
});
return data;
}
}
虽然repository模块看上去没有必要,但他起着重要的作用。它为App的其他部分抽象出了数据源。现在我们的ViewModel并不知道数据是通过WebService来获取的,这意味着我们可以随意替换掉获取数据的实现。
管理组件间的依赖关系
上面这种写法可以看出来UserRepository需要初始化Webservice实例,这虽然说起来简单,但要实现的话还需要知道Webservice的具体构造方法该如何写。这将加大代码的复杂度,另外UserRepository可能并不是唯一使用Webservice的对象,所以这种在内部构建Webservice实例显然是不推荐的,下面有两种模式来解决这个问题:
- 依赖注入:依赖注入允许类定义它们的依赖关系而不构造它们。在运行时,另一个类负责提供这些依赖关系。我们建议在Android应用程序中使用Google的Dagger 2库实现依赖注入。Dagger 2通过遍历依赖关系树自动构建对象,并在依赖关系上提供编译时保证。
- 服务定位器:服务定位器提供了一个注册表,其中类可以获取它们的依赖关系而不是构造它们。与依赖注入(DI)相比,实现起来相对容易,因此如果您不熟悉DI,请改用Service Locator。
这些模式允许你扩展代码,因为它们提供明确的模式来管理依赖关系,而不会重复代码或增加复杂性。两者都允许交换实现进行测试;这是使用它们的主要好处之一。在这个例子中,我们将使用Dagger 2来管理依赖关系。
连接ViewModel和Repository
现在,我们的UserProfileViewModel可以改写成这样:
public class UserProfileViewModel extends ViewModel {
private LiveData user;
private UserRepository userRepo;
@Inject // UserRepository parameter is provided by Dagger 2
public UserProfileViewModel(UserRepository userRepo) {
this.userRepo = userRepo;
}
public void init(String userId) {
if (this.user != null) {
// ViewModel is created per Fragment so
// we know the userId won't change
return;
}
user = userRepo.getUser(userId);
}
public LiveData getUser() {
return this.user;
}
}
缓存数据
上面的Repository虽然网络请求做了封装,但是它依赖后台数据源,所以存在不足。
上面的UserRepository实现的问题是,在获取数据之后,它不会保留在任何地方。如果用户离开UserProfileFragment并重新进来,则应用程序将重新获取数据。这是不好的,有两个原因:它浪费了宝贵的网络带宽和迫使用户等待新的查询完成。为了解决这个问题,我们将向我们的UserRepository添加一个新的数据源,它将把User对象缓存在内存中。如下:
@Singleton // informs Dagger that this class should be constructed once
public class UserRepository {
private Webservice webservice;
// simple in memory cache, details omitted for brevity
private UserCache userCache;
public LiveData getUser(String userId) {
LiveData cached = userCache.get(userId);
if (cached != null) {
return cached;
}
final MutableLiveData data = new MutableLiveData<>();
userCache.put(userId, data);
// this is still suboptimal but better than before.
// a complete implementation must also handle the error cases.
webservice.getUser(userId).enqueue(new Callback() {
@Override
public void onResponse(Call call, Response response) {
data.setValue(response.body());
}
});
return data;
}
}
持久化数据
在当前的实现中,如果用户旋转屏幕或离开并返回到应用程序,现有UI将立即可见,因为Repository会从内存中检索数据。但是,如果用户离开应用程序,并在Android操作系统杀死进程后几小时后又会怎么样?
在目前的实现中,我们将需要从网络中再次获取数据。这不仅是一个糟糕的用户体验,也是浪费,因为它将使用移动数据来重新获取相同的数据。你以通过缓存Web请求来简单地解决这个问题,但它会产生新的问题。如果请求一个朋友列表而不是单个用户,会发生什么情况?那么你的应用程序可能会显示不一致的数据,这是最令人困惑的用户体验。例如,相同的用户的数据可能会不同,因为朋友列表请求和用户请求可以在不同的时间执行。你的应用需要合并他们,以避免显示不一致的数据。
正确的处理方法是使用持久模型。这时候Room就派上用场了。
Room是一个对象映射库,它提供本地数据持久性和最少的样板代码。在编译时,它根据模式验证每个查询,从而错误的SQL查询会导致编译时错误,而不是运行时失败。Room抽象了使用原始SQL表和查询的一些基本实现细节。它还允许观察数据库数据(包括集合和连接查询)的更改,通过LiveData对象公开这些更改。
要使用Room我们首先需要使用@Entity来定义实体:
@Entity
class User {
@PrimaryKey
private int id;
private String name;
private String lastName;
// getters and setters for fields
}
接着创建数据库类:
@Database(entities = {User.class}, version = 1)
public abstract class MyDatabase extends RoomDatabase {
}
值得注意的是MyDatabase是一个抽象了,Room会在编译期间提供它的一个实现类。
接下来需要定义DAO:
@Dao
public interface UserDao {
@Insert(onConflict = REPLACE)
void save(User user);
@Query("SELECT * FROM user WHERE id = :userId")
LiveData load(String userId);
}
接着在MyDatabase中添加获取上面这个DAO的方法:
@Database(entities = {User.class}, version = 1)
public abstract class MyDatabase extends RoomDatabase {
public abstract UserDao userDao();
}
这里的load方法返回的是LiveData
现在我们可以修改UserRepository了:
@Singleton
public class UserRepository {
private final Webservice webservice;
private final UserDao userDao;
private final Executor executor;
@Inject
public UserRepository(Webservice webservice, UserDao userDao, Executor executor) {
this.webservice = webservice;
this.userDao = userDao;
this.executor = executor;
}
public LiveData getUser(String userId) {
refreshUser(userId);
// return a LiveData directly from the database.
return userDao.load(userId);
}
private void refreshUser(final String userId) {
executor.execute(() -> {
// running in a background thread
// check if user was fetched recently
boolean userExists = userDao.hasUser(FRESH_TIMEOUT);
if (!userExists) {
// refresh the data
Response response = webservice.getUser(userId).execute();
// TODO check for error etc.
// Update the database.The LiveData will automatically refresh so
// we don't need to do anything else here besides updating the database
userDao.save(response.body());
}
});
}
}
这里虽然我们将UserRepository的直接数据来源从Webservice改为本地数据库,但我们却不需要修改UserProfileViewModel或者UserProfileFragment。这就是抽象层带来的好处。这也给测试带来了方便,因为你可以提供一个虚假的UserRepository来测试你的UserProfileViewModel。
现在,如果用户重新回到这个界面,他们会立刻看到数据,因为我们已经将数据做了持久化的保存。当然如果有用例需要,我们也可不展示太老旧的持久化数据。
在一些用例中,比如下拉刷新,如果正处于网络请求中,那UI需要告诉用户正处于网络请求中。一个好的实践方式就是将UI与数据分离,因为UI可能因为各种原因被更新。从UI的角度来说,请求中的数据和本地数据类似,只是它还没有被持久化到数据库中。
以下有两种解决方法:
- 将getUser的返回值中加入网络状态。
- 在Repository中提供一个可以返回刷新状态的方法。如果你只是想在用户通过下拉刷新来告诉用户目前的网络状态的话,那这个方法是比较适合的。
数据唯一来源
在以上实例中,数据唯一来源是数据库,这样做的好处是用户可以基于稳定的数据库数据来更新页面,而不需要处理大量的网络请求状态。数据库有数据则使用,没有数据则等待其更新。
测试
我们之前提到分层可以个应用提供良好的测试能力,接下来就看看我们怎么测试不同的模块。
- 用户界面与交互:这是唯一一个需要使用到
Android UI Instrumentation test的测试模块。测试UI的最好方法就是使用Espresso框架。你可以创建Fragment然后提供一个虚假的ViewModel。因为Fragment只跟ViewModel交互,所以虚拟一个ViewModel就足够了。 - ViewModel:ViewModel可以用JUnit test进行测试。因为其不涉及界面与交互。而且你只需要虚拟UserRepository即可。
- UserRepository:测试UserRepository同样使用JUnit test。你可以虚拟出Webservice和DAO。你可以通过使用正确的网络请求来请求数据,让后将数据通过DAO写入数据库。如果数据库中有相关数据则无需进行网络请求。
- UserDao:对于DAO的测试,推荐使用instrumentation进行测试。因为此处无需UI,并且可以使用in-memory数据库来保证测试的封闭性,不会影响到磁盘上的数据库。
- Webservice:保持测试的封闭性是相当重要的,因此即使是你的Webservice测试也应避免对后端进行网络呼叫。有很多第三方库提供这方面的支持。例如,MockWebServer是一个很棒的库,可以帮助你为你的测试创建一个假的本地服务器。
架构图
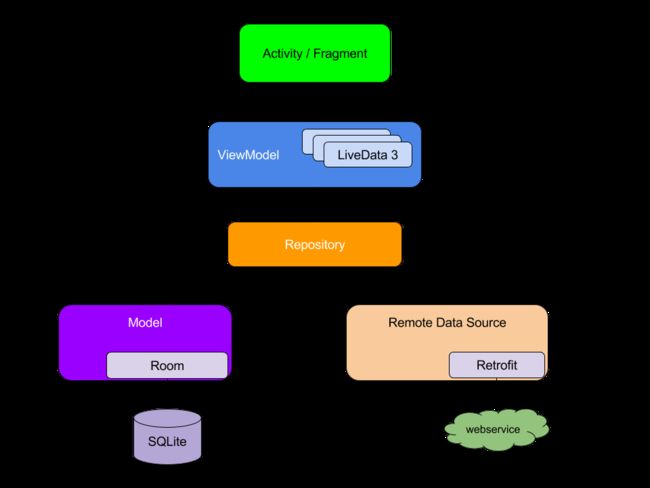
指导原则
编程是一个创意领域,构建Android应用程序也不例外。有多种方法来解决问题,无论是在多个Activity或Fragment之间传递数据,还是检索远程数据并将其在本地保持离线模式,或者是任何其他常见的场景。
虽然以下建议不是强制性的,但经验告诉我们,遵循这些建议将使你的代码库从长远来看更加强大,可测试和可维护。
- 在AndroidManifest中定义的Activity,Service,Broadcast Receiver等,它们不是数据源。相反,他们只是用于协调和展示数据。由于每个应用程序组件的寿命相当短,运行状态取决于用户与其设备的交互以及运行时的整体当前运行状况,所以不要将这些组件作为数据源。
- 你需要在应用程序的各个模块之间创建明确界定的责任范围。例如,不要在不同的类或包之间传递用于加载网络数据的代码。同样,不要将数据缓存和数据绑定这两个责任完全不同的放在同一个类中。
- 每个模块之间要竟可能少的相互暴露。不要抱有侥幸心理去公开一个关于模块的内部实现细节的接口。你可能会在短期内获得到便捷,但是随着代码库的发展,你将多付多次技术性债务。
- 当你定义模块之间的交互时,请考虑如何使每个模块隔离。例如,拥有用于从网络中提取数据的定义良好的API将使得更容易测试在本地数据库中持久存在该数据的模块。相反,如果将这两个模块的逻辑组合在一起,或者将整个代码库中的网络代码放在一起,那么测试就更难(如果不是不可能)。
- 你的应用程序的核心是什么让它独立出来。不要花时间重复轮子或一次又一次地编写相同的样板代码。相反,将精力集中在使你的应用程序独一无二的同时,让Android架构组件和其他推荐的库来处理重复的样板代码。
- 保持尽可能多的相关联的新鲜数据,以便你的应用程序在设备处于脱机模式时可用。虽然你可以享受恒定和高速连接,但你的用户可能不会。
- 你的Repository应指定一个数据源作为真实的单一来源。每当你的应用程序需要访问这些数据时,它应该始终源于真实的单一来源。
扩展: 公开网络状态
在上面的小结我们故意省略了网络错误和加载状态来保证例子的简洁性。在这一小结我们演示一种使用Resource类来封装数据及其状态。以此来公开网络状态。
下面是简单的Resource实现:
//a generic class that describes a data with a status
public class Resource {
@NonNull public final Status status;
@Nullable public final T data;
@Nullable public final String message;
private Resource(@NonNull Status status, @Nullable T data, @Nullable String message) {
this.status = status;
this.data = data;
this.message = message;
}
public static Resource success(@NonNull T data) {
return new Resource<>(SUCCESS, data, null);
}
public static Resource error(String msg, @Nullable T data) {
return new Resource<>(ERROR, data, msg);
}
public static Resource loading(@Nullable T data) {
return new Resource<>(LOADING, data, null);
}
}
以为从网络上抓取视频的同时在UI上显示数据库的旧数据是很常见的用例,所以我们要创建一个可以在多个地方重复使用的帮助类NetworkBoundResource。以下是NetworkBoundResource的决策树:
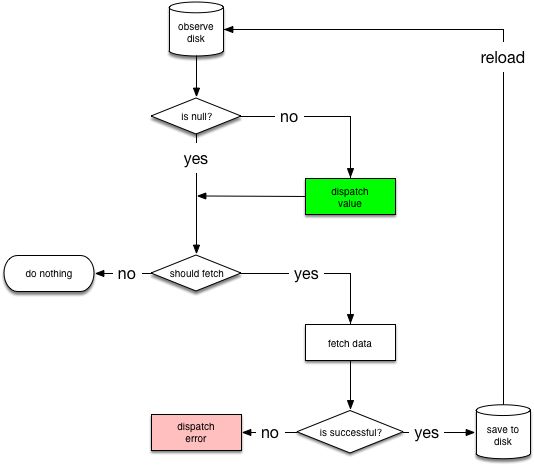
NetworkBoundResource从观察数据库开始,当第一次从数据库加载完实体后,NetworkBoundResource会检查这个结果是否满足用来展示的需求,如不满足则需要从网上重新获取。当然以上两种情况可能同时发生,你希望先将数据显示在UI上的同时去网络上请求新数据。
如果网络请求成果,则将结果保存到数据库,然后重新从数据库加载数据,如果网络请求失败,则直接传递错误信息。
注意:在上面的过程中可以看到当将新数据保存到数据库后,我们重新从数据库加载数据。虽然大部分情况我们不必如此,因为数据库会为我们传递此次更新。但另一方面,依赖数据库内部的更新机制并不是我们想要的如果更新的数据与旧数据一致,则数据谷不会做出更新提示。我们也不希望直接从网络请求中获取数据直接用于UI,因为这样违背了单一数据源的原则。
下面是NetworkBoundResource类的公共api:
// ResultType: Type for the Resource data
// RequestType: Type for the API response
public abstract class NetworkBoundResource {
// Called to save the result of the API response into the database
@WorkerThread
protected abstract void saveCallResult(@NonNull RequestType item);
// Called with the data in the database to decide whether it should be
// fetched from the network.
@MainThread
protected abstract boolean shouldFetch(@Nullable ResultType data);
// Called to get the cached data from the database
@NonNull @MainThread
protected abstract LiveData loadFromDb();
// Called to create the API call.
@NonNull @MainThread
protected abstract LiveData> createCall();
// Called when the fetch fails. The child class may want to reset components
// like rate limiter.
@MainThread
protected void onFetchFailed() {
}
// returns a LiveData that represents the resource
public final LiveData> getAsLiveData() {
return result;
}
}
注意到上面定义了两种泛型,ResultType和RequestType,因为从网络请求返回的数据类型可能会和数据库返回的不一致。
另外注意到上面代码中的ApiResponse这个类,他是将Retroft2.Call转换成LiveData的一个简单封装。
下面是NetworkBoundResource余下部分的实现:
public abstract class NetworkBoundResource {
private final MediatorLiveData> result = new MediatorLiveData<>();
@MainThread
NetworkBoundResource() {
//1初始化NetworkBoundResource
result.setValue(Resource.loading(null));
//2从数据库加载本地数据
LiveData dbSource = loadFromDb();
result.addSource(dbSource, data -> {
//3加载完成后判断是否需要从网上更新数据
result.removeSource(dbSource);
if (shouldFetch(data)) {
//4从网上更新数据
fetchFromNetwork(dbSource);
} else {
//直接用本地数据更新
result.addSource(dbSource,
newData -> result.setValue(Resource.success(newData)));
}
});
}
private void fetchFromNetwork(final LiveData dbSource) {
//5进行网络请求
LiveData> apiResponse = createCall();
// we re-attach dbSource as a new source,
// it will dispatch its latest value quickly
result.addSource(dbSource,
newData -> result.setValue(Resource.loading(newData)));
result.addSource(apiResponse, response -> {
result.removeSource(apiResponse);
result.removeSource(dbSource);
//noinspection ConstantConditions
if (response.isSuccessful()) {
//6请求数据成功,保存数据
saveResultAndReInit(response);
} else {
//请求失败使用,传递失败信息
onFetchFailed();
result.addSource(dbSource,
newData -> result.setValue(
Resource.error(response.errorMessage, newData)));
}
});
}
@MainThread
private void saveResultAndReInit(ApiResponse response) {
new AsyncTask() {
@Override
protected Void doInBackground(Void... voids) {
//7保存请求到的数据
saveCallResult(response.body);
return null;
}
@Override
protected void onPostExecute(Void aVoid) {
// we specially request a new live data,
// otherwise we will get immediately last cached value,
// which may not be updated with latest results received from network.
//8再次加载数据库,使用数据库中的最新数据
result.addSource(loadFromDb(),
newData -> result.setValue(Resource.success(newData)));
}
}.execute();
}
}
接着我们就可以在UserRepository中使用NetworkBoundResource了。
class UserRepository {
Webservice webservice;
UserDao userDao;
public LiveData> loadUser(final String userId) {
return new NetworkBoundResource() {
@Override
protected void saveCallResult(@NonNull User item) {
userDao.insert(item);
}
@Override
protected boolean shouldFetch(@Nullable User data) {
return rateLimiter.canFetch(userId) && (data == null || !isFresh(data));
}
@NonNull @Override
protected LiveData loadFromDb() {
return userDao.load(userId);
}
@NonNull @Override
protected LiveData> createCall() {
return webservice.getUser(userId);
}
}.getAsLiveData();
}
}