利用 AssemblyAI 在 PyTorch 中建立端到端的语音识别模型

作者 | Comet
译者 | 天道酬勤,责编 | Carol
出品 | AI 科技大本营(ID:rgznai100)
这篇文章是由AssemblyAI的机器学习研究工程师Michael Nguyen撰写的。AssemblyAI使用Comet记录、可视化和了解模型开发流程。
深度学习通过引入端到端的模型改变了语音识别的规则。这些模型接收音频,并直接输出转录。目前最流行的两种端到端模型是百度的Deep Speech和谷歌的Listen Attend Spell(LAS)。Deep Speech和LAS都是基于递归神经网络(RNN)的体系结构,对语音识别进行建模有着不同方法。
Deep Speech使用连接时态分类(CTC)损失函数来预测语音记录。LAS使用序列对网络架构进行预测。
这些模型通过利用深度学习系统从大型数据集中学习的能力,简化了语音识别通道。从理论上讲,有了足够的数据,你就能够构建一个超级强大的语音识别模型,该模型可以解决语音中的所有细微差别,并且不需要花费大量时间和精力手工设计声学特性或处理复杂的通道(例如,老式的GMM-HMM模型架构)。
深度学习是一个快速发展的领域,而Deep Speech和LAS风格的体系结构已经过时。你可以在下面的“最新进展”部分中了解该行业的发展方向。

如何在PyTorch中构建自己的端到端语音识别模型
让我们逐一介绍如何在PyTorch中构建自己的端到端语音识别模型。我们构建的模型受到了Deep Speech 2(百度对其著名模型的第二次修订)的启发,并对结构进行了一些个人改进。
模型的输出是字符的概率矩阵,我们使用该概率矩阵来解码音频中最有可能出现的字符。你可以找到完整的代码,还可以在Google Colaboratory上的GPU支持下运行它。
准备数据管道
数据是语音识别中最重要的方面之一。我们获取原始音频波,并将其转换为Mel频谱图。

你可以在这篇优秀的文章中阅读更多关于这种转变的细节。对于本文,你可以将Mel频谱图视为声音的图片。

为了处理音频数据,我们将使用一个非常有用的工具,被称为torchaudio,它是PyTorch团队专门为音频数据创建的一个库。我们将在LibriSpeech的一个子集上进行训练,该子集是从有声读物中获得的阅读英语语音数据的语料库,包括100个小时的转录音频数据。你可以使用torchaudio轻松下载此数据集:
import torchaudio train_dataset = torchaudio.datasets.LIBRISPEECH("./", url="train-clean-100", download=True)
test_dataset = torchaudio.datasets.LIBRISPEECH("./", url="test-clean", download=True)数据集的每个样本都包含波形、音频采样率、话语/标签,以及样本上更多的元数据。你可以在此处从源代码中查看每个示例。
数据扩充– SpecAugment
数据扩充是一种用于人为增加数据集多样性来增加数据集大小的技术。当数据稀少或模型过度拟合时,此策略特别有用。对于语音识别,你可以执行标准的增强技术,比如更改音高,速度,注入噪声以及向音频数据添加混响。
我们发现频谱图增强(SpecAugment)是一种更简单、更有效的方法。SpecAugment,最早是在论文SpecAugment:一种用于自动语音识别的简单数据增强方法中介绍的,在文中作者发现,简单地裁剪连续的时间和频率维度的随机块可以显著提高模型的泛化能力。

在PyTorch中,你可以使用torchaudio函数FrequencyMasking来掩盖频率维度,并使用TimeMasking来度量时间维度。
torchaudio.transforms.FrequencyMasking()
torchaudio.transforms.TimeMasking()
有了数据后,我们需要将音频转换为Mel频谱图,并将每个音频样本的字符标签映射为整数标签:
class TextTransform:
"""Maps characters to integers and vice versa"""
def __init__(self):
char_map_str = """
' 0
<SPACE> 1
a 2
b 3
c 4
d 5
e 6
f 7
g 8
h 9
i 10
j 11
k 12
l 13
m 14
n 15
o 16
p 17
q 18
r 19
s 20
t 21
u 22
v 23
w 24
x 25
y 26
z 27
"""
self.char_map = {}
self.index_map = {}
for line in char_map_str.strip().split('\n'):
ch, index = line.split()
self.char_map[ch] = int(index)
self.index_map[int(index)] = ch
self.index_map[1] = ' '
def text_to_int(self, text):
""" Use a character map and convert text to an integer sequence """
int_sequence = []
for c in text:
if c == ' ':
ch = self.char_map['']
else:
ch = self.char_map[c]
int_sequence.append(ch)
return int_sequence
def int_to_text(self, labels):
""" Use a character map and convert integer labels to an text sequence """
string = []
for i in labels:
string.append(self.index_map[i])
return ''.join(string).replace('', ' ')
train_audio_transforms = nn.Sequential(
torchaudio.transforms.MelSpectrogram(sample_rate=16000, n_mels=128),
torchaudio.transforms.FrequencyMasking(freq_mask_param=15),
torchaudio.transforms.TimeMasking(time_mask_param=35)
)
valid_audio_transforms = torchaudio.transforms.MelSpectrogram()
text_transform = TextTransform()
def data_processing(data, data_type="train"):
spectrograms = []
labels = []
input_lengths = []
label_lengths = []
for (waveform, _, utterance, _, _, _) in data:
if data_type == 'train':
spec = train_audio_transforms(waveform).squeeze(0).transpose(0, 1)
else:
spec = valid_audio_transforms(waveform).squeeze(0).transpose(0, 1)
spectrograms.append(spec)
label = torch.Tensor(text_transform.text_to_int(utterance.lower()))
labels.append(label)
input_lengths.append(spec.shape[0]//2)
label_lengths.append(len(label))
spectrograms = nn.utils.rnn.pad_sequence(spectrograms, batch_first=True).unsqueeze(1).transpose(2, 3)
labels = nn.utils.rnn.pad_sequence(labels, batch_first=True)
return spectrograms, labels, input_lengths, label_lengths

定义模型-DeepSpeech 2
我们的模型将类似于Deep Speech 2结构。该模型将具有两个主要的神经网络模块——学习相关的音频特征的N层残差卷积神经网络(ResCNN),以及利用学习后的ResCNN音频特征的一组双向递归神经网络(BiRNN)。该模型的顶部是一个全连通层,用于按时间步长对字符进行分类。

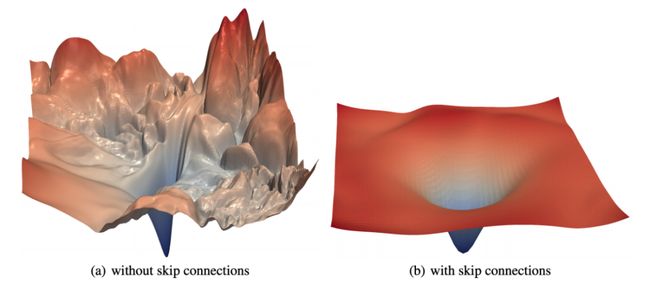
卷积神经网络(CNN)善于提取抽象特征,我们会将相同的特征提取能力应用于音频频谱图。我们选择使用残差的CNN层,而不只是普通的CNN层。残差连接(又称为跳过连接)是在“用于图像识别的深度残差学习”一文中首次引入。作者发现,如果将这些连接添加到CNN中,可以建立真正的深度网络,并获得较高的准确性。
添加这些残差连接有助于模型更快地学习和更好地推广。这篇可视化神经网络的损失图景的论文表明,具有残留连接的网络具有一个“平坦的”损失面,使模型更容易描绘损失状况,并找到一个更低且更通用的最小值。
递归神经网络(RNN)擅长处理序列建模问题。RNN会逐步处理音频特征,在使用前一帧的上下文的同时对每一帧进行预测。我们使用BiRNN是因为我们不仅需要每个步骤之前框架的上下文,还希望得到它之后框架的上下文。
这可以帮助模型做出更好的预测,因为音频中的每一帧在进行预测之前都会有更多信息。我们使用RNN的门控递归单元(GRU)变种,因为它比LSTM需要的的计算资源更少,并且在某些情况下工作效果也一样。
该模型为输出字符的概率矩阵,我们将使用该矩阵将其输入到解码器中,提取模型认为是概率最高的字符。
class CNNLayerNorm(nn.Module):
"""Layer normalization built for cnns input"""
def __init__(self, n_feats):
super(CNNLayerNorm, self).__init__()
self.layer_norm = nn.LayerNorm(n_feats)
def forward(self, x):
# x (batch, channel, feature, time)
x = x.transpose(2, 3).contiguous() # (batch, channel, time, feature)
x = self.layer_norm(x)
return x.transpose(2, 3).contiguous() # (batch, channel, feature, time)
class ResidualCNN(nn.Module):
"""Residual CNN inspired by https://arxiv.org/pdf/1603.05027.pdf
except with layer norm instead of batch norm
"""
def __init__(self, in_channels, out_channels, kernel, stride, dropout, n_feats):
super(ResidualCNN, self).__init__()
self.cnn1 = nn.Conv2d(in_channels, out_channels, kernel, stride, padding=kernel//2)
self.cnn2 = nn.Conv2d(out_channels, out_channels, kernel, stride, padding=kernel//2)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.layer_norm1 = CNNLayerNorm(n_feats)
self.layer_norm2 = CNNLayerNorm(n_feats)
def forward(self, x):
residual = x # (batch, channel, feature, time)
x = self.layer_norm1(x)
x = F.gelu(x)
x = self.dropout1(x)
x = self.cnn1(x)
x = self.layer_norm2(x)
x = F.gelu(x)
x = self.dropout2(x)
x = self.cnn2(x)
x += residual
return x # (batch, channel, feature, time)
class BidirectionalGRU(nn.Module):
def __init__(self, rnn_dim, hidden_size, dropout, batch_first):
super(BidirectionalGRU, self).__init__()
self.BiGRU = nn.GRU(
input_size=rnn_dim, hidden_size=hidden_size,
num_layers=1, batch_first=batch_first, bidirectional=True)
self.layer_norm = nn.LayerNorm(rnn_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.layer_norm(x)
x = F.gelu(x)
x, _ = self.BiGRU(x)
x = self.dropout(x)
return x
class SpeechRecognitionModel(nn.Module):
"""Speech Recognition Model Inspired by DeepSpeech 2"""
def __init__(self, n_cnn_layers, n_rnn_layers, rnn_dim, n_class, n_feats, stride=2, dropout=0.1):
super(SpeechRecognitionModel, self).__init__()
n_feats = n_feats//2
self.cnn = nn.Conv2d(1, 32, 3, stride=stride, padding=3//2) # cnn for extracting heirachal features
# n residual cnn layers with filter size of 32
self.rescnn_layers = nn.Sequential(*[
ResidualCNN(32, 32, kernel=3, stride=1, dropout=dropout, n_feats=n_feats)
for _ in range(n_cnn_layers)
])
self.fully_connected = nn.Linear(n_feats*32, rnn_dim)
self.birnn_layers = nn.Sequential(*[
BidirectionalGRU(rnn_dim=rnn_dim if i==0 else rnn_dim*2,
hidden_size=rnn_dim, dropout=dropout, batch_first=i==0)
for i in range(n_rnn_layers)
])
self.classifier = nn.Sequential(
nn.Linear(rnn_dim*2, rnn_dim), # birnn returns rnn_dim*2
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(rnn_dim, n_class)
)
def forward(self, x):
x = self.cnn(x)
x = self.rescnn_layers(x)
sizes = x.size()
x = x.view(sizes[0], sizes[1] * sizes[2], sizes[3]) # (batch, feature, time)
x = x.transpose(1, 2) # (batch, time, feature)
x = self.fully_connected(x)
x = self.birnn_layers(x)
x = self.classifier(x)
return x

选择合适的优化器和调度器–具有超融合的AdamW
优化器和学习率调度器在使模型收敛到最佳点方面起着非常重要的作用。选择合适的的优化器和调度器还可以节省计算时间,并有助于你的模型更好应用到实际案例中。
对于我们的模型,我们将使用AdamW和一个周期学习率调度器。Adam是一种广泛使用的优化器,可帮助你的模型更快地收敛,节省计算时间,但由于没有推广性,和随机梯度下降(SGD)一样臭名昭著。
AdamW最初是在“去耦权重衰减正则化”中引入的,被认为是对Adam的“修复”。该论文指出,原始的Adam算法权重衰减的实现上存在错误,AdamW试图解决该问题。这个修复程序有助于解决Adam的推广问题。
单周期学习率调度算法最早是在《超收敛:大学习率下神经网络的快速训练》一文中引入的。本文表明,你可以使用一个简单的技巧,在保持其可推广能力的同时,将神经网络的训练速度提高一个数量级。
开始时学习率很低,逐渐上升到一个很大的最大学习率,然后线性衰减到最初开始时的位置。
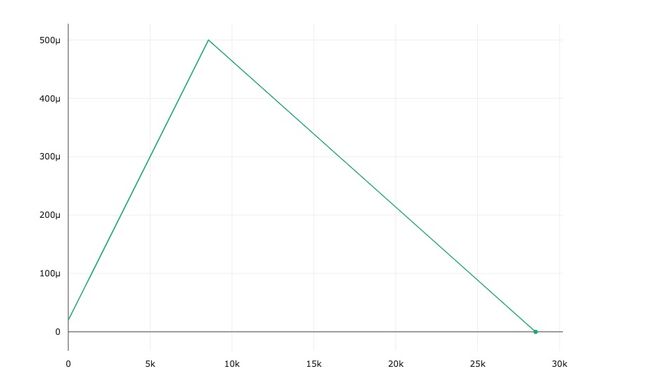
最大学习率比最低学习率要高很多,你可以获得一些正则化好处,如果数据量较小,可以帮助你的模型更好地推广。
使用PyTorch,这两种方法已经成为软件包的一部分。
optimizer = optim.AdamW(model.parameters(), hparams['learning_rate'])
scheduler = optim.lr_scheduler.OneCycleLR(optimizer,
max_lr=hparams['learning_rate'],
steps_per_epoch=int(len(train_loader)),
epochs=hparams['epochs'],
anneal_strategy='linear')

CTC损失功能–将音频与文本对齐
我们的模型将接受训练,预测输入到模型中的声谱图中每一帧(即时间步长)字母表中所有字符的概率分布。

传统的语音识别模型将要求你在训练之前将文本与音频对齐,并且将训练模型来预测特定帧处的特定标签。
CTC损失功能的创新之处在于它允许我们可以跳过这一步。我们的模型将在训练过程中学习对齐文本本身。关键在于CTC引入的“空白”标签,该标签使模型能够表明某个音频帧没有产生字符。你可以在这篇出色的文章中看到有关CTC及其工作原理的更详细说明。
PyTorch还内置了CTC损失功能。
criterion = nn.CTCLoss(blank=28).to(device)

语音模型评估
在评估语音识别模型时,行业标准使用的是单词错误率(WER)作为度量标准。错误率这个词的作用就像它说的那样——它获取你的模型输出的转录和真实的转录,并测量它们之间的误差。
你可以在此处查看它是如何实现。另一个有用的度量标准称为字符错误率(CER)。CER测量模型输出和真实标签之间的字符误差。这些指标有助于衡量模型的性能。
在本教程中,我们使用“贪婪”解码方法将模型的输出处理为字符,这些字符可组合创建文本。“贪婪”解码器接收模型输出,该输出是字符的最大概率矩阵,对于每个时间步长(频谱图帧),它选择概率最高的标签。如果标签是空白标签,则将其从最终的文本中删除。
def GreedyDecoder(output, labels, label_lengths, blank_label=28, collapse_repeated=True):
arg_maxes = torch.argmax(output, dim=2)
decodes = []
targets = []
for i, args in enumerate(arg_maxes):
decode = []
targets.append(text_transform.int_to_text(labels[i][:label_lengths[i]].tolist()))
for j, index in enumerate(args):
if index != blank_label:
if collapse_repeated and j != 0 and index == args[j -1]:
continue
decode.append(index.item())
decodes.append(text_transform.int_to_text(decode))
return decodes, targets

使用Comet.ml训练和监测实验
Comet.ml提供了一个平台,允许深度学习研究人员跟踪、比较、解释和优化他们的实验和模型。Comet.ml提高了AssemblyAI的工作效率,我们强烈建议团队使用这个平台进行任何类型的数据科学实验。
Comet.ml非常容易设置。仅需几行代码即可工作。
initialize experiment object
experiment = Experiment(api_key=comet_api_key, project_name=project_name)
experiment.set_name(exp_name)
track metrics
experiment.log_metric('loss', loss.item())
Comet.ml为你提供了一个非常高效的仪表板,你可以查看和跟踪模型的进度。
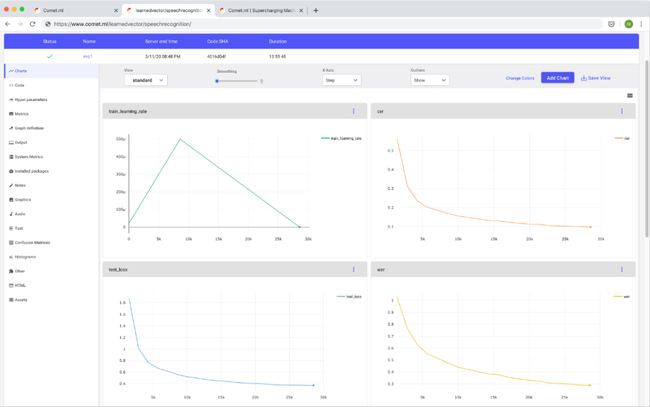
你可以使用Comet来跟踪指标、代码、超参数、模型图等。Comet提供的一项非常方便的功能,能够将你的实验与许多其他实验进行比较。

Comet具有丰富的功能集,我们在这里不会全部介绍,但是我们强烈建议您使用它来提高生产率和健全性。
下面是我们训练脚本的其余部分。
class IterMeter(object):
"""keeps track of total iterations"""
def __init__(self):
self.val = 0
def step(self):
self.val += 1
def get(self):
return self.val
def train(model, device, train_loader, criterion, optimizer, scheduler, epoch, iter_meter, experiment):
model.train()
data_len = len(train_loader.dataset)
with experiment.train():
for batch_idx, _data in enumerate(train_loader):
spectrograms, labels, input_lengths, label_lengths = _data
spectrograms, labels = spectrograms.to(device), labels.to(device)
optimizer.zero_grad()
output = model(spectrograms) # (batch, time, n_class)
output = F.log_softmax(output, dim=2)
output = output.transpose(0, 1) # (time, batch, n_class)
loss = criterion(output, labels, input_lengths, label_lengths)
loss.backward()
experiment.log_metric('loss', loss.item(), step=iter_meter.get())
experiment.log_metric('learning_rate', scheduler.get_lr(), step=iter_meter.get())
optimizer.step()
scheduler.step()
iter_meter.step()
if batch_idx % 100 == 0 or batch_idx == data_len:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(spectrograms), data_len,
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader, criterion, epoch, iter_meter, experiment):
print('\nevaluating…')
model.eval()
test_loss = 0
test_cer, test_wer = [], []
with experiment.test():
with torch.no_grad():
for I, _data in enumerate(test_loader):
spectrograms, labels, input_lengths, label_lengths = _data
spectrograms, labels = spectrograms.to(device), labels.to(device)
output = model(spectrograms) # (batch, time, n_class)
output = F.log_softmax(output, dim=2)
output = output.transpose(0, 1) # (time, batch, n_class)
loss = criterion(output, labels, input_lengths, label_lengths)
test_loss += loss.item() / len(test_loader)
decoded_preds, decoded_targets = GreedyDecoder(output.transpose(0, 1), labels, label_lengths)
for j in range(len(decoded_preds)):
test_cer.append(cer(decoded_targets[j], decoded_preds[j]))
test_wer.append(wer(decoded_targets[j], decoded_preds[j]))
avg_cer = sum(test_cer)/len(test_cer)
avg_wer = sum(test_wer)/len(test_wer)
experiment.log_metric('test_loss', test_loss, step=iter_meter.get())
experiment.log_metric('cer', avg_cer, step=iter_meter.get())
experiment.log_metric('wer', avg_wer, step=iter_meter.get())
print('Test set: Average loss: {:.4f}, Average CER: {:4f} Average WER: {:.4f}\n'.format(test_loss, avg_cer, avg_wer))
def main(learning_rate=5e-4, batch_size=20, epochs=10,
train_url="train-clean-100", test_url="test-clean",
experiment=Experiment(api_key='dummy_key', disabled=True)):
hparams = {
"n_cnn_layers": 3,
"n_rnn_layers": 5,
"rnn_dim": 512,
"n_class": 29,
"n_feats": 128,
"stride": 2,
"dropout": 0.1,
"learning_rate": learning_rate,
"batch_size": batch_size,
"epochs": epochs
}
experiment.log_parameters(hparams)
use_cuda = torch.cuda.is_available()
torch.manual_seed(7)
device = torch.device("cuda" if use_cuda else "cpu")
if not os.path.isdir("./data"):
os.makedirs("./data")
train_dataset = torchaudio.datasets.LIBRISPEECH("./data", url=train_url, download=True)
test_dataset = torchaudio.datasets.LIBRISPEECH("./data", url=test_url, download=True)
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
train_loader = data.DataLoader(dataset=train_dataset,
batch_size=hparams['batch_size'],
shuffle=True,
collate_fn=lambda x: data_processing(x, 'train'),
**kwargs)
test_loader = data.DataLoader(dataset=test_dataset,
batch_size=hparams['batch_size'],
shuffle=False,
collate_fn=lambda x: data_processing(x, 'valid'),
**kwargs)
model = SpeechRecognitionModel(
hparams['n_cnn_layers'], hparams['n_rnn_layers'], hparams['rnn_dim'],
hparams['n_class'], hparams['n_feats'], hparams['stride'], hparams['dropout']
).to(device)
print(model)
print('Num Model Parameters', sum([param.nelement() for param in model.parameters()]))
optimizer = optim.AdamW(model.parameters(), hparams['learning_rate'])
criterion = nn.CTCLoss(blank=28).to(device)
scheduler = optim.lr_scheduler.OneCycleLR(optimizer, max_lr=hparams['learning_rate'],
steps_per_epoch=int(len(train_loader)),
epochs=hparams['epochs'],
anneal_strategy='linear')
iter_meter = IterMeter()
for epoch in range(1, epochs + 1):
train(model, device, train_loader, criterion, optimizer, scheduler, epoch, iter_meter, experiment)
test(model, device, test_loader, criterion, epoch, iter_meter, experiment)训练功能可在整个数据周期内训练模型。在每个时期之后,测试功能都会根据测试数据评估模型。它获取test_loss以及模型的cer和wer。你现在可以在Google合作实验室的GPU支持下开始运行训练脚本。

如何提高准确性
语音识别需要大量数据和计算资源。这个示例是在LibriSpeech(100小时的音频)的一个子集和一个单独的GPU上进行训练的。为了获得最先进的结果,你需要对数千小时的数据进行分布式训练,并且需要在许多计算机上分布数十个GPU。
提高准确性的另一种方法是使用语言模型和CTC波束搜索算法对CTC概率矩阵进行解码。CTC类型模型非常依赖此解码过程来获得良好的结果。这里有一个方便的开源库允许你这样做。
本教程的使用范围更广,与BERT(3.4亿个参数)相比,它是一个相对较小的模型(2300万个参数)。尽管收益递减,但似乎你的网络规模越大,它的性能就越好。正如OpenAI的研究“ Deep Double Descent”证明的那样,一个更大的模型并不总是等同于更好的性能。
该模型具有3个CNN残差层和5个双向GRU层,允许你在具有至少11GB内存的单个GPU上训练合理的批处理大小。你可以调整main函数中的一些超级参数,减少或增加你的用例和计算可用性的模型大小。

基于深度学习的语音识别的最新进展
深度学习是一个快速发展的领域。似乎你一个星期都不能没有新技术得到最先进的结果。以下是在语音识别领域中值得探索的几个方面。
转换器
转换器席卷了自然语言处理世界。首先在论文中介绍了“无可或缺的注意力”,转换器已经出现和修改,几乎击败所有现有的NLP任务,取代了RNN的类型体系结构。转换器查看序列数据完整上下文的能力也可以转转移到语音中。
无人监督的预训练
如果你密切关注深度学习,你可能听说过BERT,GPT和GPT2。这些Transformer模型首先用于使用未标记文本数据的语言建模任务,并在各种NLP任务上进行了微调,获得了最新的结果。在预训练期间,该模型学习了一些语言统计方面的基础知识,并利用该能力在其他任务上表现出色。我们相信这项技术在语音数据方面也具有广阔的前景。
词块模型
我们的模型在上面定义了输出字符。这样做的一些好处是,在进行语音推理时,模型不必担心词汇量不足。对于单词c h a t,每个字符都有自己的标签。使用字符的缺点是效率低,由于你一次只能预测一个字符,该模型更容易出现错误。
使用整个单词作为标签已经探索了,在一定程度上取得了成功。使用这种方法,整个单词chat将成为标签。如果使用整个单词,你就必须对所有可能的词汇进行索引来才能进行预测,这会使内存效率低,在预测过程中可能会遇到词汇量不足的情况。最有效的方法是使用单词片段或子单词单位作为标签。
你可以将单词分割成子单词单元,使用这些子单词作为标签,即ch at,而不是单个标签的字符。这不仅解决了词汇量不足的问题,并且效率更高,与使用字符相比,它需要更少的步骤来进行解码,而且不需要对所有可能的单词进行索引。词块已成功用于许多NLP模型(如BERT),自然可以解决语音识别问题。
原文链接:https://hackernoon.com/building-an-end-to-end-speech-recognition-model-in-pytorch-with-assemblyai-5o8s3yry
本文由 AI 科技大本营翻译,转载请注明出处。

推荐阅读
重构ncnn,腾讯优图开源新一代移动端推理框架TNN
墨奇科技汤林鹏:如何用 AI 技术颠覆指纹识别?
性能超越最新序列推荐模型,华为诺亚方舟提出记忆增强的图神经网络
研发的未来在哪里?Serverless 云开发来了!
真惨!连各大编程语言都摆起地摊了!
国外小伙怒喷加密货币行业:入行两年,我受够了!
你点的每个“在看”,我都认真当成了AI