from: https://zhuanlan.zhihu.com/p/27657196
1. 写在前面
大概两个月前,接到一个小任务,要做一个深度学习在人体姿态识别领域的一些调研,以前也没做调研相关的事情,连格式怎么写都不知道,前前后后看了接近20篇论文,然后就写下来这篇小总结,感觉都不能算是调研,文章主要列出了一些相关的数据集以及深度学习的方法包括基于无监督学习的行为识别、基于卷积神经网络的行为识别、基于循环神经网络以及一些拓展模型的方法。当然,这里面提到的很多模型都不是最新的技术,还有很多最新的模型和技术都没有包含进来。
因为这篇文章写出来已经很久了,所以很多东西记得都有些模糊,这次只是将原来的md文件拿过来排个版,如果有哪里有什么问题,请指正,谢谢。
2. 本文结构
本文首先提出一共17个人体姿态识别相关的数据集及其链接,然后给出9个深度学习在人体姿态识别领域的应用模型,包括其论文提出的思路、模型结构、实验数据集和使用的加速硬件(如果有的话),本文不提供相关的实现方法。
3. 数据集
3.1 KTH
链接
介绍:视频数据集包括六种动作(走、慢跑、快跑、拳击、挥手和鼓掌),所有动作由25个人分别演示,并且融合了四种场景进行演示,一共有个AVI视频文件。
3.2 Weizmaan
链接
介绍:一共有90个视频文件,由9个人展示,每个人展示十种动作。
3.3 HOHA
链接
介绍:从电影中采集的真实的人类活动。
3.4 Keck Gesture
链接
介绍:包含14中不同手势(军用信号),使用彩色相机拍摄,分辨率为 ,每个手势都有三个人演示,每个视频序列中,一个人重复演示三次同样的手势,训练的一共有个视频序列。并且拍摄角度固定背景也固定。测试的一共个视频序列,并且使用运动相机拍摄并且处于杂乱且有移动物体的背景中。视频格式为AVI。
3.5 MSR action
链接
介绍:数据集包含16个视频序列,并且一共有63个动作,每一个视频序列包含复合动作,一些序列不同人的不同动作,同时有室内和室外场景,所有的视频都是在杂乱并且移动的背景中。视频分辨率为,帧率为15fps,视频序列的长度在32~76秒之间
3.6 YouTube Action
链接
介绍:包含11种动作类,对于每一类动作,视频分为25组, 每一组有4个动作(分在同一组的视频有着一些共同的特征)
3.7 UT-Interaction
链接
介绍:提供了一个人-人交互的数据集。包括6类动作,一共有20个视频序列(时长约1分钟),分辨率为,帧率30fps。
3.8 TRECVID Data Availability
链接
3.9 UCF50
链接
介绍:YouTube Action的拓展。
3.10 UCF101
链接
介绍:UCF50的拓展。
3.11 UCF sport actions
连接
3.12 VTB
链接
3.13 VOT
链接
3.14 JHMDB
链接
3.15 MPII Cooking Activities
连接
3.16 HMDB51
链接
3.17 Spots-1M
链接
4. 深度学习算法
4.1 基于无监督学习的行为识别
4.1.1 案例1
论文[1] 将独立子空间分析(Independent subspace analysis,ISA)扩展到三维的视频数据上,使用无监督的学习算法对视频块进行建模。这个方法首先在小的输入块上使用ISA算法,然后将学习到的网络和较大块的输入图像进行卷积,将卷积过程得到的响应组合在一起作为下一层的输入,将得到的描述方法运用到视频数据上。
模型
文章提出,为了克服过大数据量带来的ISA算法的低效,将ISA改为一种堆叠卷积ISA网络,网络结构如下:
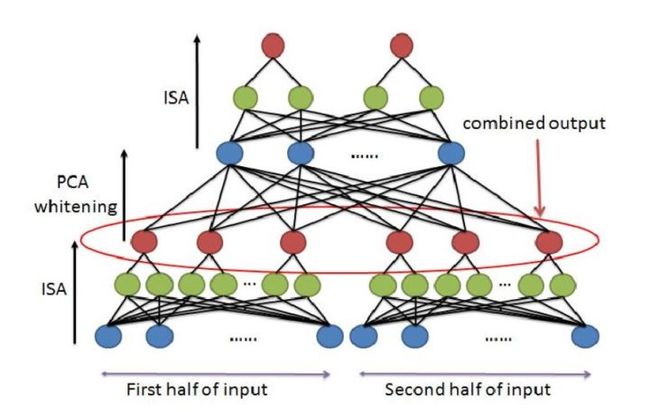
首先使用小批量的数据训练ISA网络,然后将训练好的网络与较大的输入卷积,然后使用PCA算法处理,最后再经过一层ISA网络训练。
为了适应三维的视频信息,将一段视频序列压缩成一个向量作为输入,得到最终模型如下图所示:
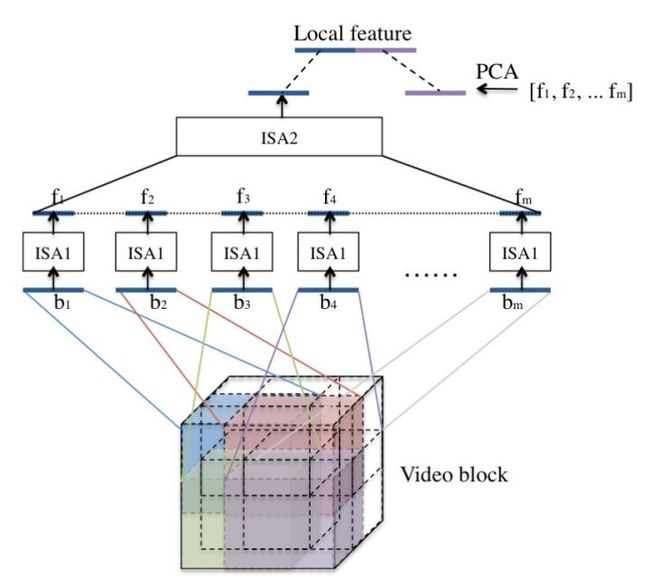
数据集
KTH
UCF sport actions
Hollywood 2
YouTube action
加速硬件
GPU
4.2 基于卷积神经网络的行为识别
4.2.1 案例1
论文[2] 将传统的CNN拓展到具有时间信息的3D-CNN,在视频数据的时间维度和空间维度上进行特征计算,在卷积过程中的特征图与多个连续帧中的数据进行连接。
模型
简单来说,3D-CNN就是将连续的视频帧看作一个盒子,使用一个三维的卷积核进行卷积,通过这种结构,就能捕获动作信息,三维卷积如下所示:
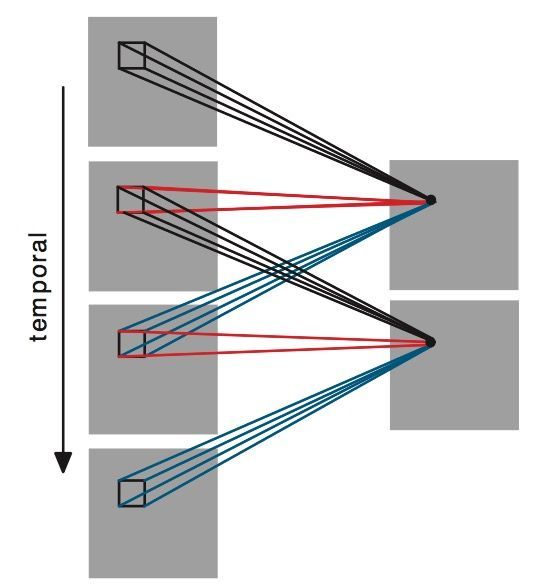
3D-CNN网络结构如下:
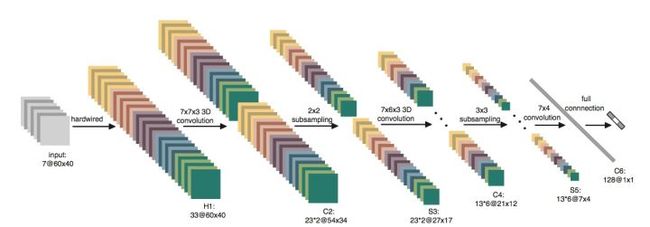
使用7帧大小帧序列作为输入,第一层为硬编码的卷积核,然后进行两次卷积和下采样,最后得到一个128维的特征集合。
数据集
-
TRECVID 2008
-
KTH
4.2.2 案例2
论文[3] 提出一种称为P-CNN的模型,使用单帧数据和光流数据,从而捕获运动信息。
模型
原理如下所示:
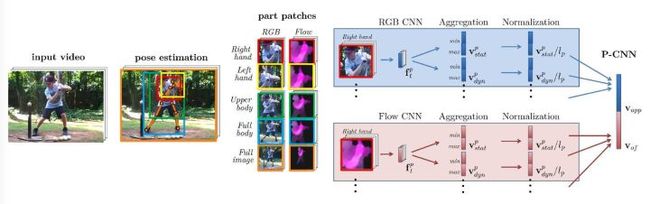
首先,要对视频序列计算光流数据并且存储为图片的形式,对于给定的视频信息和相对应的骨骼位置,将RGB图片和光流图片分割为5类(左手、右手、上部分身体、下部分身体和整张图片),将其大小均初始化为,然后使用两个不同的卷积网络,每个网络都含有5个卷积层和3个全连层,然后通过聚合和归一化,最后整合为一个P-CNN的特征集合,最后使用线性SVM进行训练。
数据集
JHMDB
MPII Cooking Activities
4.2.3 案例3
论文[4] 提出一种称为Long-term Temporal Convolutions(LTC-CNN)的网络,在定长时间的视频内使用三维的CNN。
模型
结构如下所示:
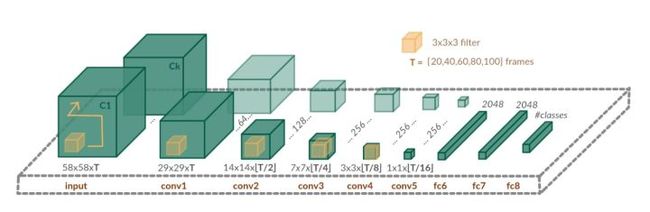
相比于其他的将视频切分为短时间的序列,该模型最大限度的保留了视频的时空信息,网络有5个时空卷积层和3个全连层,对于每个时空卷积核尺寸都为,都采用ReLU函数和最大值池化层(max pooling,除了第一层为,其他尺寸均为 ),并且在卷积时采用1像素的边缘填充。
在实验中,尝试使用不同大小的输入(时间长短,视频分辨率)和不同的数据(RGB数据,几种不同的光流数据)。
数据集
UCF101
HMDB51
加速硬件
GPU
4.2.4 案例4
论文[5] 使用多分辨率的卷积神经网络对视频特征进行提取。输入视频被分作两组独立的数据流:低分辨率的数据流和原始分辨率的数据流。这两个数据流都交替地包含卷积层、 正则层和抽取层,同时这两个数据流最后合并成两个全连接层用于后续的特征识别。
模型
该论文首先考察了几种融合(fusion)方式,如下图所示:
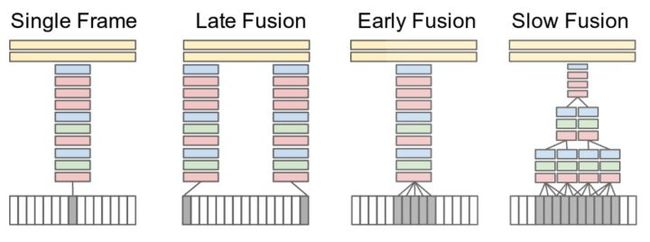
-
Single Frame:使用单一帧进行训练。
-
Late Fusion:两个分离的单帧共享参数,然后在第一个全连层合并,分离的帧获取不到任何运动信息,但是全连层可以通过对比获取到运动特性。
-
Early Fusion:一段时间内的视频帧共享参数,这种连接可以精确获取局部运动方向和速度。
-
Slow Fusion:前两种方式的混合。
上图中红色代表卷积,绿色代表归一化,蓝色代表池化。
最终采用的模型网络结构如下:
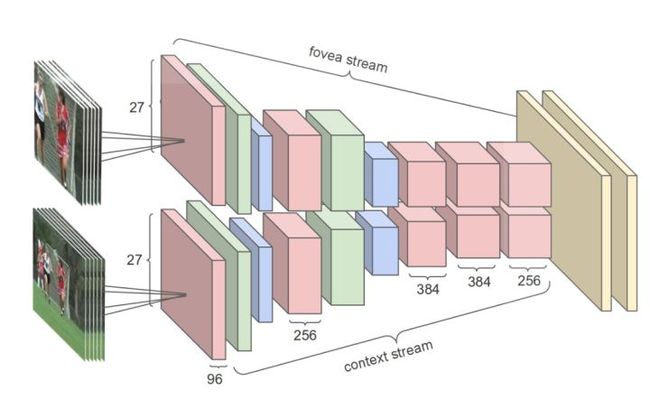
输入视频被分成两个独立的数据流:低分辨率和高分辨率,交替通过卷积、归一化和池化最后经过两个全连层。
上图中红色代表卷积,绿色代表归一化,蓝色代表池化。
数据集
实验数据集:Spots-1M
迁移学习数据集:UCF-101
加速硬件
GPU
4.2.5 案例5
论文[6] 使用两个数据流的卷积神经网络来进行视频行为识别。他们将视频分成静态帧数据流和帧间动态数据流,静态帧数据流可使用单帧数据,帧间动态的数据流使用光流数据,每个数据里都使用深度卷积神经网络进行特征提取。最后将得到的特征使用SVM进行动作的识别。他们提出只使用人体姿势的关节点部分的相关数据进行深度卷积网络进行特征提取,最后使用统计的方法将整个视频转换为一个特征向量,使用SVM进行最终分类模型的训练和识别。
模型
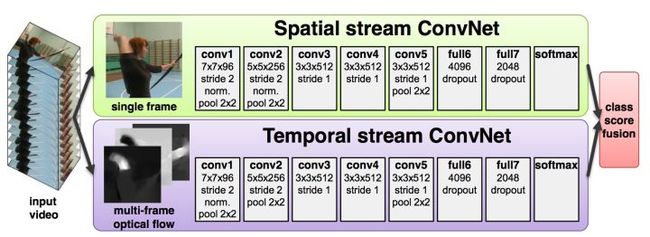
该模型输入为视频序列,然后将视频序列处理为两个流数据:代表空间信息单帧静态数据流和代表时间信息的动态数据流,其中,动态数据流为几种不同的光流数据的组合。
数据集
UCF-101
HMDB-51
在ImageNet ILSVRC-2012数据集上进行预训练
实验平台
使用Caffe toolbox训练
使用OpenCV toolbox计算光流数据
加速硬件
使用4块NVIDIA的Titan训练一个ConvNet,时长1天,比单GPU训练速度快了3.2倍
计算光流数据的时候也使用GPU
4.3 循环神经网络及扩展模型
4.3.1 案例1
论文[7] 使用LSTM对视频进行建模,LSTM将底层CNN的输出连接起来作为下一时刻的输入,在UCF101数据库上获得了82.6% 的识别率。
模型
该文献的整体思路如下:

将图像数据和光流数据分别通过底层CNN处理,然后输出的连接通过Feature pooling或者LSTM,文章对比了这两种处理手段。
其中LSTM的结构如下所示:
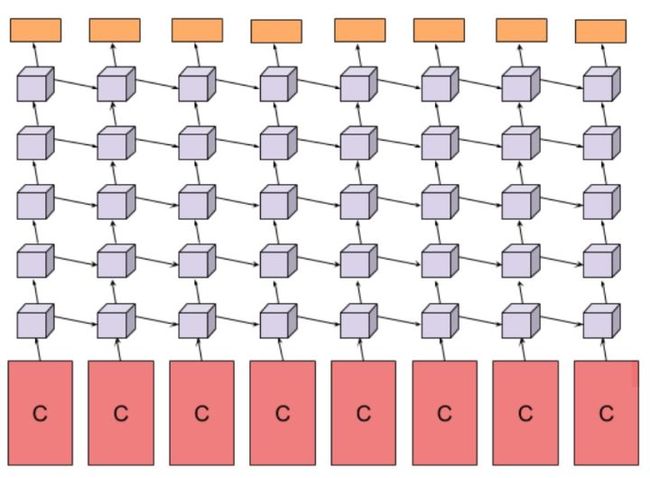
该模型首先将数据输入到卷积网络中,然后将卷积网络的输出作为输入传给一个深度LSTM结构,深度为5层,每一层都有512个记忆细胞,最后有一个softmax层用来做预测。其中卷积结构使用的是AlexNet和GoogLeNet。
数据集
Sports-1M
UCF-101
4.3.2 案例2
论文[8]提出了长时递归卷积神经网络(Long-term recurrent convolutional network,LRCN),这个网络将CNN和LSTM结合在一起对视频数据进行特征提取,单帧的图像信息通过CNN获取特征,然后将CNN的输出按时间顺序通过LSTM,这样最终将视频数据在空间和时间维度上进行特征表征,在UCF101数据库上得到了82.92% 的平均识别率。
模型
模型结构如下:
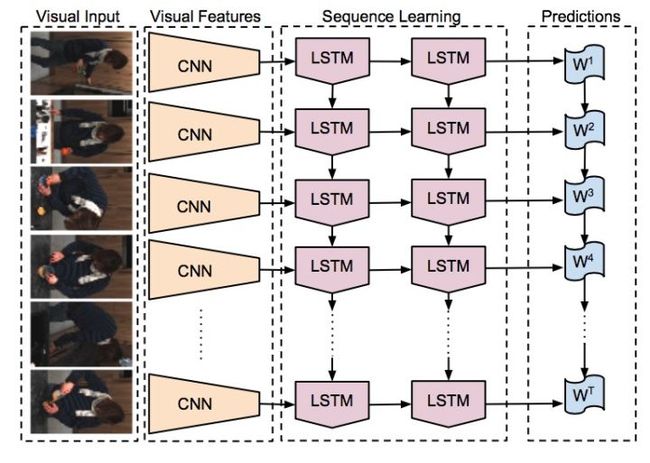
该模型将卷积神经网络和LSTM相结合,输入可以是一个单独的图片或者是一个视频的一帧,将该输入进行死绝特征提取,可以得到一个用来表示数据特征的定长向量,然后将其输入到LSTM中学习到其中时间相关的信息,最后做出预测。
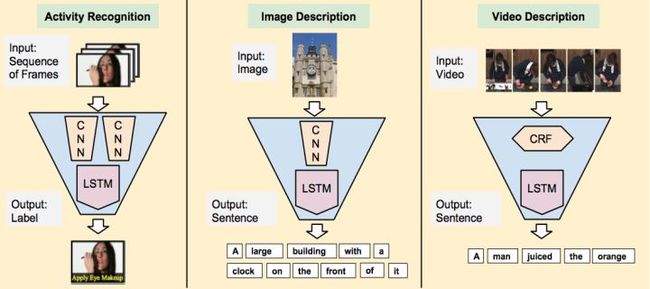
该模型的特点是可以根据不同的输入实现不同的的任务:
-
动作识别:序列输入,固定输出
-
图片描述:固定输入,序列输出
-
视频描述:输入和输入均是序列
数据集
动作识别:UCF-101
加速硬件
NVIDA GPU
4.3.3 案例3
论文[9] 提出一种称为Part-Aware LSTM的模型,该模型主要是在针对使用Kinect采集的骨骼数据进行人体的姿态识别。
模型
Part-Aware LSTM结构如下:
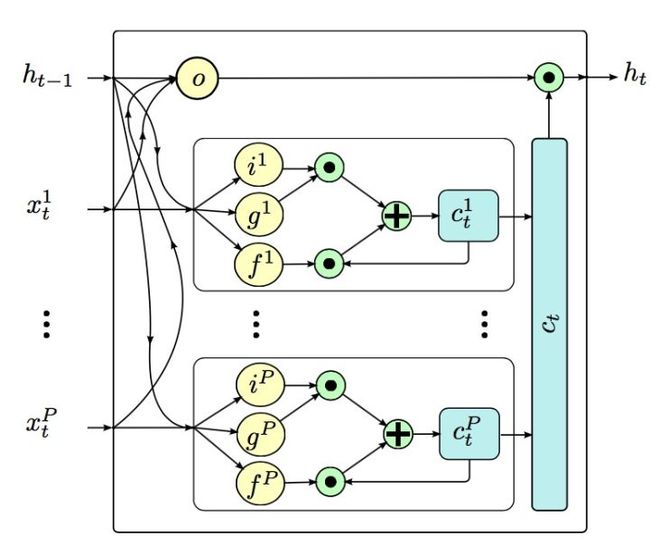
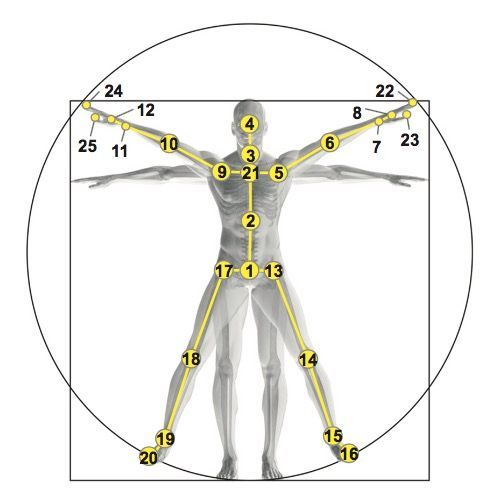
该模型在LSTM的基础上,允许有多个i、g和f门,但是只有一个o门,主要是将下图所示的25个人体骨骼根据动作的相关性分成5个组:躯干、双手和双腿。让这个5个组分别通过自己的i、g和f门,但是却共享一个o门,即每一个时间序列上,豆浆这5个组各自的状态存在细胞状态中,这样不仅可以得到人体关节在时间序列上的关联,也可以通过分组更好获取人体运动的特征。
骨骼如下:
数据集
NTU RGB+D
加速硬件
NVIDIA Tesla K40 GPU
5. 总结
本文第一部分给了16个用于人体姿态识别的常用数据集,这些数据集在后面介绍的9种模型中也大多有使用到,只是不同的地方名字可能不同,这里没有进行统一,所有在后面模型中使用到的数据集均在前面列了出来。
主要看了9个在人体姿态捕捉领域提出的深度学习模型,大体上分为三类:基于非监督学习的行为识别(主要以自编码器为代表);基于卷积神经网络的行为识别;基于循环神经网络与其扩展模型的行为识别。
-
非监督学习的行为识别(论文[1])主要通过ISA(独立子空间分析)的叠加,需要提前训练好ISA网络然后再将其与较大的数据进行卷积。
-
卷积神经网络的使用比较广泛,但总体上都可以将其理解为三维的卷积神经网络即在时间上多了一个维度,其中论文[3]和[6]都借助了光流分析,将原本的视频数据和光流数据处理得到的结果进行整合,论文[5]提出了几种融合(fusion)方式,通过不同的方式可以得到不同的结果,有的可以提取出视频序列局部的运动方向和速度,有的可以进行对比得到运动方式,综合考虑,最后采用了低分辨率和高分辨率两种数据流作为模型的输入通过三维的卷积神经网络进行处理。
-
对于循环神经网络及其拓展模型,给出了三个模型,前两种在结构上略微相似,都是将视频序列经过CNN处理提取出特征数据然后经过若干层LSTM,论文[7]也运用了光流的处理方法,而论文[8]提出的模型可以完成多项任务即行为识别、图像描述和视频描述,应用更为广泛,最后一个P-LSTM的模型与前面都略有不同,主要是基于骨骼的坐标信息而不是图像信息。
这些论文的来源主要是文献[10]和文献[11],其中,文献[10]主要介绍的是深度学习在目标跟踪中的应用而文献[11]主要介绍的是深度学习在人体姿态识别上的应用,二者略有不同。在调研的时候,除了上面说的三类,其实还有其他一些分类,比如基于限制玻尔兹曼机及其扩展模型的一些方法(详细可见论文[12]和[13]),因为之前没有接触过玻尔兹曼机,所以没有记录下来。
6. 参考文献
[1] Le Q V, Zou W Y, Yeung S Y, Ng A Y. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI: IEEE, 2011. 3361-3368
[2] Ji S W, Xu W, Yang M, Yu K. 3D convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35 (1) : 221–231.
[3] Chéron G, Laptev I, Schmid C. P-CNN: pose-based CNN features for action recognition. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015. 3218-3226
[4] Varol G, Laptev I, Schmid C. Long-term temporal convolutions for action recognition. arXiV: 1604.04494, 2015
[5] Karpathy A, Toderici G, Shetty S, Leung T, Sukthankar R, Li F F. Large-scale video classification with convolutional neural networks. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, OH: IEEE, 2014. 1725-1732
[6] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos. In: Proceedings of Advances in Neural Information Processing Systems. Red Hook, NY: Curran Associates, Inc., 2014. 568-576
[7] Ng J Y H, Hausknecht M, Vijayanarasimhan S, Vinyals O, Monga R, Toderici G. Beyond short snippets: deep networks for video classification. arXiv: 1503.08909, 2015
[8] Donahue J, Hendricks L A, Guadarrama S, Rohrbach M, Venugopalan S, Saenko K, Darrell T. Long-term recurrent convolutional networks for visual recognition and description. arXiv: 1411.4389, 2014.
[9] Amir Shahroudy, Jun Liu, Tian-Tsong Ng, Gang Wang. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. arXiv: 1604.02808
[10] 管皓, 薛向阳, 安志勇. 深度学习在视频目标跟踪中的应用进展与展望[J]. 自动化学报, 2016, 42(6): 834-847. doi: 10.16383/j.aas.2016.c150705
[11] 朱煜, 赵江坤, 王逸宁, 郑兵兵. 基于深度学习的人体行为识别算法综述[J]. 自动化学报, 2016, 42(6): 848-857. doi: 10.16383/j.aas.2016.c150710
[12] Taylor G W, Hinton G E. Factored conditional restricted Boltzmann machines for modeling motion style. In: Proceedings of the 26th Annual International Conference on Machine Learning. New York: ACM, 2009. 1025-1032
[13] Chen B, Ting J A, Marlin B, de Freitas N. Deep learning of invariant spatio-temporal features from video. In: Proceedings of Conferrence on Neural Information Processing Systems (NIPS) Workshop on Deep Learning and Unsupervised Feature Learning. Whistler BC Canada, 2010.
作者:桑燊
2017年7月2日