CVPR2020 | 旷视研究院提出SAT:优化解决半监督视频物体分割问题

IEEE国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 将于 6 月 14-19 日在美国西雅图举行。近日,大会官方论文结果公布,旷视研究院 16 篇论文被收录,研究领域涵盖物体检测与行人再识别(尤其是遮挡场景),人脸识别,文字检测与识别,实时视频感知与推理,小样本学习,迁移学习,3D感知,GAN与图像生成,计算机图形学,语义分割,细粒度图像等众多领域,取得多项领先的技术研究成果,这与即将开源的旷视AI平台Brain++密不可分。
本文是旷视CVPR2020论文系列解读第2篇,探索了在半监督条件下如何高效利用视频时空特性解决视频物体分割(VOS)问题。本文提出一个全新的pipeline,称之为状态感知跟踪器(State-Aware Tracker/SAT),其可以在给出高精确的结果的同时实现实时分割。论文代码已开源。

论文名称:State-Aware Tracker for Real-Time Video Object Segmentation
论文链接:https://arxiv.org/abs/2003.00482
论文代码:https://github.com/MegviiDetection/video_analyst
目录
导语
简介
方法
架构
估计
反馈
剪裁策略回路
全局建模回路
实验
结论
参考文献
往期解读
导语
半监督视频物体分割(VOS)需要在视频序列仅有初始掩膜(mask)的情况下,分割目标物体,这是一项计算机视觉基本任务。VOS提供初始掩膜作为视觉引导。但是,在整个视频序列中,目标物体可能遭遇较大的姿态、尺寸和表面的变化,进而,甚至遇到异常情况,比如遮挡、快速移动和切断。因此,通过半监督方式在视频序列中获得鲁棒表示是一项颇具挑战性的任务。
幸运的是,视频序列带有VOS任务所需的更多的上下文信息。首先,视频的帧间一致性使得帧之间的高效信息传递成为可能。其次,在VOS任务中,前一帧的信息可看作临时的语境,可为后续预测提供有益的线索。因此,高效利用视频自带的额外信息对VOS任务非常重要。
但是,先前工作并未充分利用视频的特性,多是完全忽略了帧之间的关系,单独处理每一帧,造成巨大的信息浪费;其他方法则使用特征级联和关联,或者光流,把已预测的掩膜从前一帧传播至下一帧,这有着明显缺陷。
首先,先前工作通常在整张图像上传播信息,目标物体通常占有较小的区域。在这种情况下,整张图像上的操作可能造成冗余计算。此外,整个视频中目标物体会经历不同的状态,但是这些方法采用固定传播策略,没有适应性,从而在长序列上变得不稳定。
它们只能从第一个或前一帧中寻找目标建模的线索,不足以进行整体的表示。结果,大多数现有方法无法在VOS任务中同时实现较佳的精度和较快的速度。因此,需要一个针对半监督视频物体分割任务的更加有效和鲁棒的pipeline。
简介
本文中,旷视研究院把VOS表示为一个状态估计和目标建模的连续过程,其中分割是状态估计的一个特殊方面。具体而言,本文提出一个简单而高效的pipeline,称之为状态感知跟踪器(State-Aware Tracker/SAT)。
借助帧间一致性,SAT把每一个目标物体看作tracklet,这不仅使pipeline更加有效,还会过滤错误而有助于目标建模。为构建一个更可靠的信息流,本文提出一个估计-反馈机制,使得模型可以感知当前状态,并自适应不同状态。
为了更整全的目标建模,SAT在整个视频序列中通过临时的语境信息动态构建整体表示,以提供鲁棒的视觉引导。如图1所示,在DAVIS2017验证集上,SAT取得了较具竞争力的精度 ,并且快于所有其他方法。
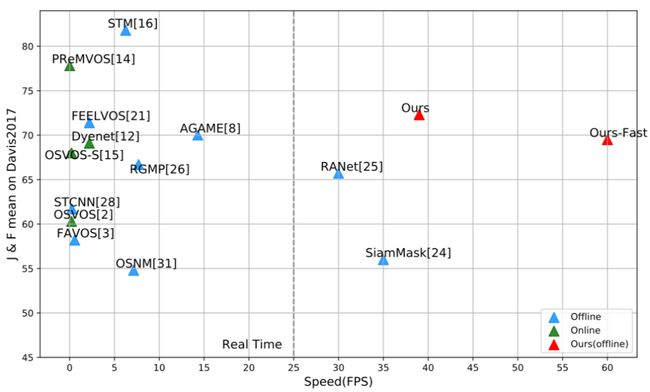
图1:DAVIS2017验证集上的速度和精度结果
本文pipeline的简单图示见图2。推理过程可总结为分割-评估-反馈。

图2:本文pipeline图示
首先,SAT裁剪目标物体周围的一个搜索区域,并把每个目标作为一个tracklet。联合分割网络为每个tracklet预测掩膜;第二,状态估计器评估分割的结果,给出状态值,表征当前状态;第三,基于状态估计结果设计两个状态回路。
剪裁策略回路(Cropping Strategy Loop)适应性地采取不同方法预测目标的检测框;接着,根据已经预测的框裁剪下一帧的搜索区域。这一转换策略使得跟踪过程越发稳定。
同时,整体建模回路(Global Modeling Loop)通过状态估计结果动态地更新整体的特征。反过来,整体特征也有助于联合分割网络生成更加的分割结果。
方法
架构
本文提出的全新pipeline称之为状态感知跟踪器(SAT),它的高效率在于把每个目标看作一个tracklet。另外,SAT 不仅可以感知每个状态,而且通过两个反馈回路发展出了自适应能力。
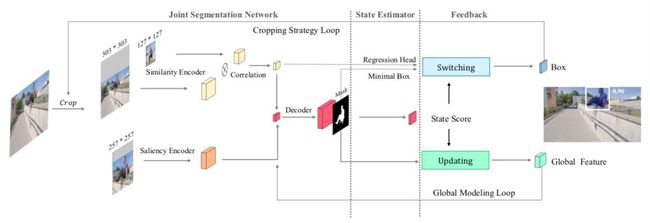
图 3:SAT pipeline
如图3所示,SAT的推理分为三步:1)分割,2)估计,3)反馈。首先,联合分割网络融合相似性编码器、显著性编码器和全局特征的特征,生成一个掩膜预测;第二,状态估计器评估分割结果,通过状态值描述当前状态,并评估状态异常与否;第三,构建两个反馈回路,针对不同状态进行自适应。
在裁剪策略回路中,如果一个状态正常,则使用一个已预测的掩膜生成一个最小的检测框;状态异常,则通过一个回归head预测边界框并结合多帧进行平滑。
接着,基于已预测的检测框,裁剪下一帧的搜索区域。在全局建模回路中,本文使用状态估计结果、已预测的掩膜和当前的帧图像块更新全局特征,并使用全局特征提升联合分割网络以得到更好的分割结果。
估计
本文提出置信值表示表示掩膜预测的置信度,用集中度表示已预测掩膜的几何集中程度。本文计算置信度,如等式1所示:
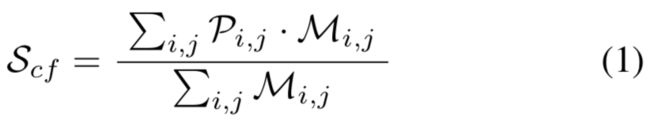
本文把集中度值定义为最大连接区域和已预测的二值掩膜的整个区域的比率,见等式2:
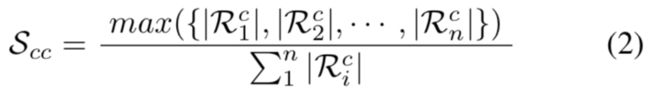
最后,计算状态值,见等式3:
![]()
反馈
基于估计结果,本文构建了两个反馈回路,一个转换剪裁策略以使跟踪器越发稳定,另一个则更新全局表示以提升分割的质量。
剪裁策略回路
本文在推理时,本文为正常状态选择掩膜框,以生成更精确的定位;异常状态则选择回归框,获得更鲁棒的预测。图4给出了策略转换的一些实例。

图4:掩膜框(白色)和回归框(彩色)之间的转换
如果为所有帧选择掩膜框,那么异常状态出现时,本文模型将无法跟踪目标;如果保持使用回归框,当目标较好展示或背景有干扰因素时,定位预测精度将下降。
因此,两者之间的转换使得本文模型可以自适应不同状态,并且跟踪过程更加精确和稳定。
全局建模回路
全局建模回路为目标物体动态地更新一个全局的特征,并使用这一全局特征改进分割过程,见图5:
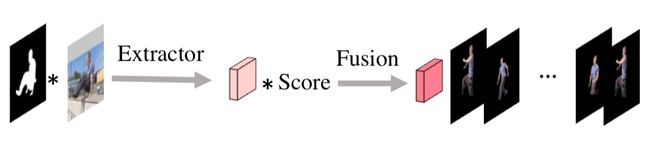
图5:全局建模回路的更新过程
全局建模回路会更新一个全局特征,它随着时间对视觉变化越发鲁棒。反过来,本文使用这一全局特征提升联合分割网络的高阶表示。这一反馈回路使得本文的目标表示在长视频序列中更加全局和鲁棒。
实验
本文方法与一些当前最佳方法在DAVIS2017验证集、DAVIS2016验证集和YouTube-VOS数据集上做了实验对比,量化结果证明了本文方法同时在速度和精度上取得了出色的性能。
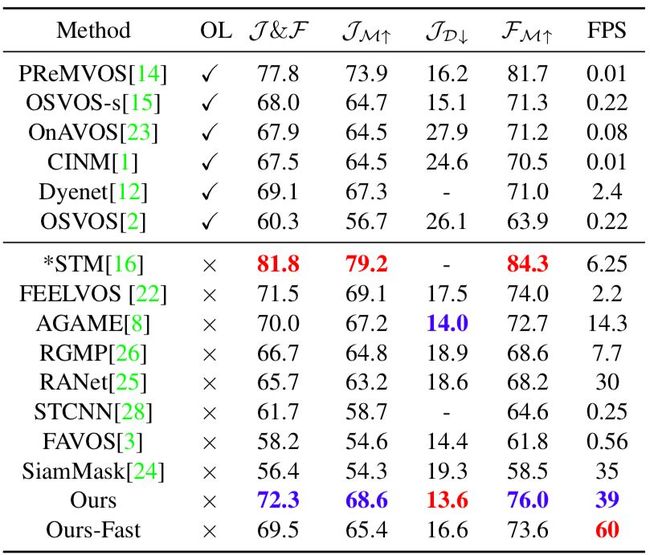
表4:DAVIS2017验证集上的量化结果对比
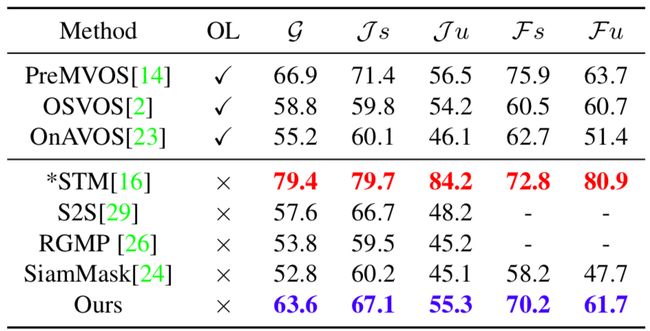
表6:YouTube-VOS数据集上的量化结果对比
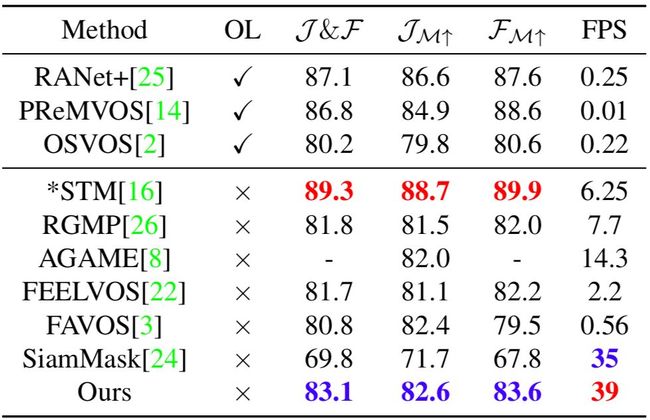
表7:DAVIS2016验证集上的量化结果对比
结论
本文提出状态感知跟踪器SAT,在半监督视频分割任务中取得了高效而出色的表现。SAT把每一个目标物体看作一个tracklet,以更高效地执行视频物体分割任务。借助估计反馈机制,SAT可以感知当前的状态,并自适应以取得稳定而鲁棒的性能。在一些主要的VOS经典数据集上,本文方法以出色的精度与速度权衡获得由竞争力的结果。
加入社群
旷视物体检测技术交流群

或添加 farman7230 入群
参考文献
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural net- works. In Advances in neural information processing sys- tems, pages 1097–1105, 2012.
Yinda Xu, Zeyu Wang, Zuoxin Li, Yuan Ye, and Gang Yu. SiamFC++: Towards Robust and Accurate Visual Track- ing with Target Estimation Guidelines. arXiv e-prints, page arXiv:1911.06188, 2019.
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bela ́ez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675, 2017.
Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 724– 732, 2016.
Ning Xu, Linjie Yang, Yuchen Fan, Jianchao Yang, Dingcheng Yue, Yuchen Liang, Brian Price, Scott Cohen, and Thomas Huang. Youtube-vos: Sequence-to-sequence video object segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 585–601, 2018.
往期解读
CVPR2020 | 旷视研究院提出PVN3D:基于3D关键点投票网络的单目6DoF位姿估计算法
传送门
欢迎大家关注如下 旷视研究院 官方微信号????
