字符串匹配之 BM 算法
一、基本概念
字符串匹配是计算机科学领域中最古老、研究最广泛的问题之一,层出不穷的前辈们也总结了非常多经典的优秀算法,例如 BF 算法、RK 算法、BM 算法、KMP 算法,今天我介绍的主角是 BM 算法。
字符串匹配可以简单概括为前缀匹配,后缀匹配,子串匹配,下面的讲解我都以最常见的子串匹配为例。子串匹配的概念很简单,一句话解释就是:在一个字符串 A 中寻找另一个字符串 B,这里的字符串 A 可以叫做 主串,字符串 B 可以叫做 模式串。
二、基础解法
1. BF 算法
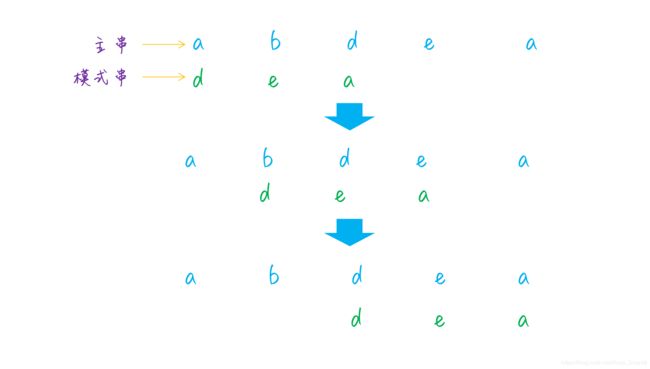
在一个字符串中寻找另一字符串,最容易想到的,也是最简单的办法是:取主串和模式串中的每一位依次比较,如果匹配则同时后移一位继续比较,直至匹配到模式串的最后一位;如果出现不匹配的字符,则模式串向后移动一位,继续比较。这种解决问题的思路简单暴力,也是这个算法被叫做BF(Brute Force)的原因。
整个匹配的过程可以参考下图:
整个代码实现也非常简单,我这里写一个示例供参考:
public static int bruteForce(String main, String ptn){
if (main == null || ptn == null){
return -1;
}
int m = main.length();
int n = ptn.length();
if (n > m){
return bf(ptn, main);
}
for (int i = 0; i <= m - n; i++) {
int j = i;
int k = 0;
while (k < n && main.charAt(j) == ptn.charAt(k)){
++j;
++k;
}
if (k == n){
return i;
}
}
return -1;
}
复杂度分析
这个算法的复杂度还是比较好分析的,我们假设主串的长度是 m,模式串的长度是 n,在最好的情况下,在第一个字符处的匹配就能够成功,例如主串是 a b c d ,模式串是a b c,这时只遍历了模式串的长度,因为时间复杂度是 O(n);
在最坏的情况下,每次都需要遍历整个模式串,但是又未能匹配成功,例如主串是 a a a a a ...a,模式串是 a a a a b,所以需要遍历 m - n + 1 次,时间复杂度是 O(m * n) 。
从代码中可以看出,整个过程没有借助额外的存储空间,只使用到了几个常数,因此空间复杂度是 O(1)。
2. RK 算法
RK 算法是以其两位发明者 Rabin、Karp 的名字命名的,它其实是 BF 算法的一个优化版本。
前面讲到的 BF 算法,每次在主串和模式串进行匹配时,都需要遍历模式串,而 RK 算法借助了哈希算法来降低时间复杂度。
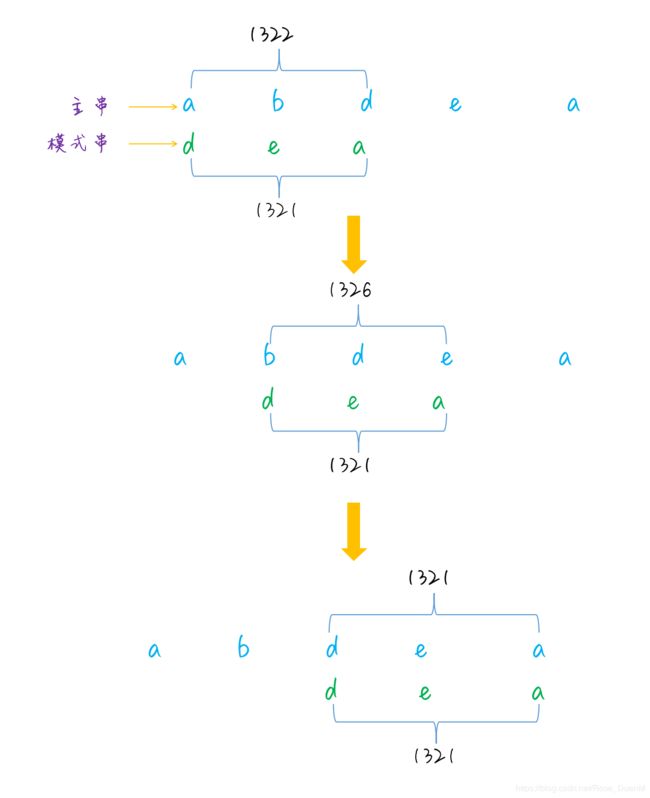
当模式串和主串进行比较时,并不直接依次遍历每个字符,而是计算主串的子字符串的哈希值,然后将哈希值和模式串的哈希值进行比较,如果哈希值相等,则可以判定匹配成功,整个匹配的过程可以参考下图:
可以看到,优化的地方在于将每次的遍历模式串比较,变成了哈希值之间的比较,这样的话匹配的速度就加快了。但需要注意的是,如果求解哈希值的函数需要遍历字符串的话,那么这个算法的时间复杂度并没有得到提升,反而还有可能下降,因为每次遍历的话,这和 BF 算法暴力匹配的思路就没有区别了,所以哈希函数的设计就要避免这个问题。
容易想到的一种简单的哈希函数是,直接将每个字符的 ASCII 码相加,得到一个哈希值。假设主串是 a b d e a,模式串为 d e a ,长度是 3,第一次匹配时,取的子字符串是 a b d,第二次取的子字符串是 b d e,可以看到这两个子字符串是有重合的部分的,只有首尾两个字符不一样,所以代码实现可以利用这一点来避免遍历字符串。当然这种哈希函数比较简单,还有其他一些更加精妙的设计,感兴趣的话可以自行研究下。
还有一个问题便是,如果存在哈希冲突的话,即两个字符串的哈希值虽然一样,但是字符串可能并不一样,这个问题的解决思路其实很简单,当哈希值相同时,再依次遍历两个字符串看是否相同,如果相同,则匹配成功。因为哈希冲突并不会经常出现,所以这一次的依次遍历匹配的开销还是可以接受的,对算法整体效率的影响并不大。
下面是一个简单的代码示例供参考:
public static int rabinKarp(String main, String ptn){
if (main == null || ptn == null){
return -1;
}
int m = main.length();
int n = ptn.length();
if (n > m){
return rk(ptn, main);
}
//计算模式串的hash值
int ptnHash = 0;
for (int i = 0; i < n; i++) {
ptnHash += ptn.charAt(i);
}
int mainHash = 0;
for (int i = 0; i <= m - n; i++) {
//i == 0时需要遍历计算哈希值,后续不需要
if (i == 0) {
for (int j = 0; j < n; j++) {
mainHash += main.charAt(j);
}
}else {
mainHash = mainHash - main.charAt(i - 1) + main.charAt(i + n - 1);
}
//如果哈希值相同,为避免哈希冲突,再依次遍历比较
if (mainHash == ptnHash){
int k = i;
int j = 0;
while (j < n && main.charAt(k) == ptn.charAt(j)){
++k;
++j;
}
if (j == n){
return i;
}
}
}
return -1;
}
模式串和主串之间的匹配是常数时间的,最多只需要遍历 m - n + 1 次,再加上可能存在哈希冲突的情况,因此 RK 算法的总体的时间复杂度大概为 O(m)。
在极端情况下,如果哈希函数设计得十分不合理,产生哈希冲突的概率很高的话,那么每次遍历都需要扫描一遍模式串,那么算法的时间复杂度就退化为 O(m * n) 了。
三、BM 算法
了解了两种基本的字符串匹配算法之后,其实可以发现 BF 算法和 RK 算法都存在一个很明显的缺陷,那就是如果出现了不匹配的情况,那么每次模式串都是向后移动一位,然后再继续比较。那有没有更加高效的办法让模式串多移动几位呢,这就是 BM 算法试图解决的问题。
BM 算法也是由两位发明者 Boyer 和 Moore 的名字命名的,其核心思想是在主串和模式串进行比较时,如果出现了不匹配的情况,能够尽可能多的获取一些信息,借此跳过那些肯定不会匹配的情况,以此来提升字符串匹配的效率,大多数文本编辑器中的字符查找功能,一般都会使用 BM 算法来实现。
BM 算法主要由两部分组成,分别是坏字符规则和好后缀规则,下面依次介绍。
1. 坏字符规则
前面说到的字符串匹配,匹配的顺序都是从前到后,按位依次匹配的,而利用坏字符规则的时候,主串和模式串的匹配顺序是从后往前,倒着匹配的,像下图这样:
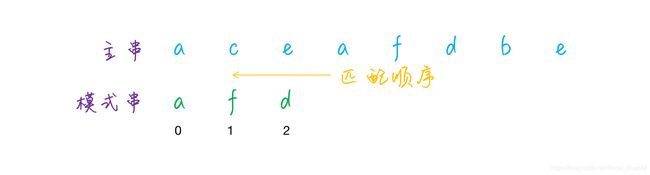
匹配的时候,如果主串中的字符和模式串的字符不匹配,那么就将主串中这个字符叫做坏字符,例如上图中的字符 e ,因为它和模式串中的 d 不匹配:
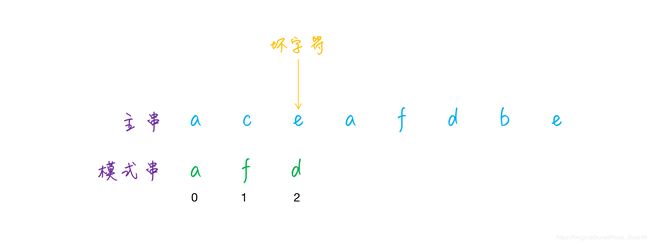
如果遇到了坏字符,可以看到坏字符 e 在模式串中是不存在的,那么可以判定,主串中字符 e 之前的部分肯定不会匹配,因此可以直接将模式串移动至坏字符 e后面继续匹配,相较于暴力匹配每次移动一位,这样显然更加高效:
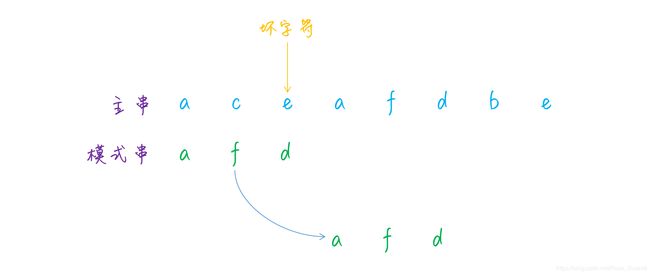
但需要注意的是,如果坏字符在模式串中是存在的,那么就不能直接移动模式串至坏字符的后面了,而是将模式串移动至和坏字符相同的字符处,然后继续比较,参考下图:
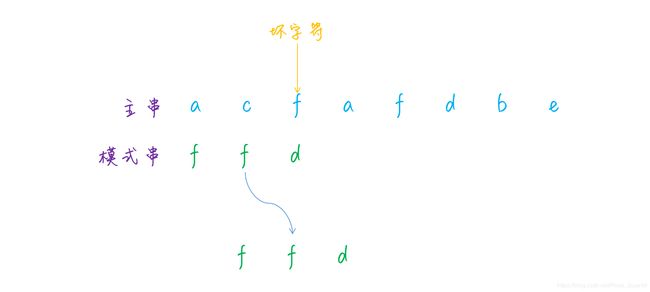
可以看到,坏字符可能在模式串中存在多个,那么移动模式串的时候,应该移动至更靠前的那个,还是更靠后的那个呢?为了避免错过正确匹配的情况,我们应该移动更少的位数,因此必须移动至更靠后的那个坏字符处。就像上图中的那样,坏字符 f在模式串中存在两个,移动时需要将模式串移动至更靠后的那个坏字符处。
总结一下规律,当匹配的时候,如果遇到了坏字符,有两种情况:一是坏字符不在模式串中,那么直接移动模式串至坏字符后一位;如果坏字符在模式串中,那么移动模式串至与坏字符匹配的最靠后的那个字符处,然后继续比较。
现在很关键的一个问题来了,我们怎么知道一个字符在模式串中是否存在呢?最常规的思路是遍历整个模式串,查找是否存在,但是这样的时间复杂度是 O(n),对算法效率的影响很大,有没有更加高效的方法呢?此时很容易想到哈希表,哈希表的特性是通过哈希映射实现了高效的查找,用到现在这个场合是非常合适的。
先假设一种比较基础的情况,我们的匹配的字符只包含常规的英文字符,总共 256 个,那么可以构建一个数组,模式串中字符的 ACSII 码为数组的下标,下标对应的值为模式串每个字符的位置,参考下图:
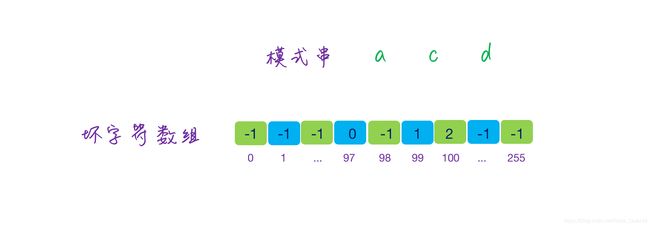
这样,当匹配的时候,如果遇到了坏字符,就可以从数组中对应的下标查询,如果值大于等于 0,说明坏字符在模式串中,并且数组中的值是字符在模式串中的位置,可以利用这个值来判断模式串移动的位数,大致的代码实现如下:
private static final int[] badChar = new int[256];
public static int bm(String main, String ptn){
if (main == null || ptn == null){
return -1;
}
int m = main.length();
int n = ptn.length();
badCharRule(ptn, badChar);
int i = n - 1;
while (i <= m - 1) {
int j = n - 1;
while (j >= 0 && main.charAt(i) == ptn.charAt(j)){
--i;
if (--j == -1){
return i + 1;
}
}
//计算坏字符规则下移动的位数
int moveWithBC = j - badChar[main.charAt(i)];
i += moveWithBC;
}
return -1;
}
/**
* 生成坏字符数组
*/
private static void badCharRule(String str, int[] badChar){
if (str == null){
return;
}
Arrays.fill(badChar, -1);
for (int i = 0; i < str.length(); i++) {
badChar[str.charAt(i)] = i;
}
}
坏字符规则虽然利用起来比较高效,但是在某些情况下,它还是有点问题的,例如主串是 a a a a a a a a ,模式串是 b a a a的这种情况,如果利用坏字符规则,那么计算出来的移动位数有可能是负数,因此 BM 算法还需要使用好后缀规则来避免这种情况。
2. 好后缀规则
好后缀规则要稍微复杂一点了,当匹配的时候,如果遇到了坏字符,并且如果前面已经有匹配的字符的话,那么就把这段字符叫做好后缀,参考下图:
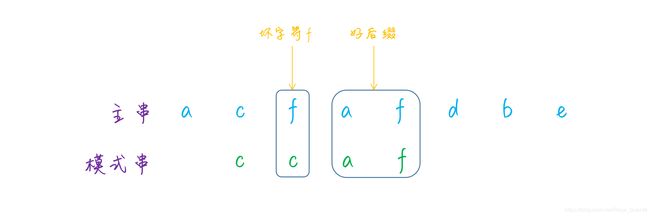
和坏字符规则的处理思路类似,如果出现了好后缀,那么可以查看好后缀在模式串中是否存在。
第一种情况,如果不存在的话,则直接移动模式串至好后缀的后一位,然后继续匹配。例如下图中的好后缀 a f 在模式串中是不存在的,因此移动模式串至a f 后面:
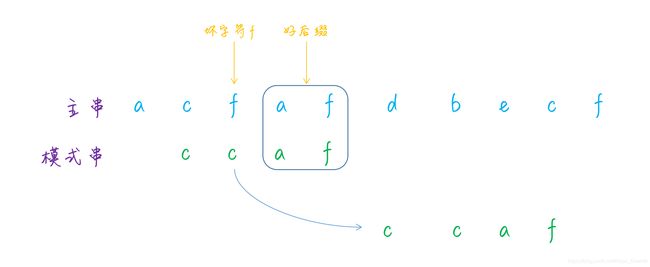
但是这样移动会存在一个问题,例如下面的这个例子,主串是c a c d e f a d e f c a,模式串是e f a d e f,好后缀 d e f 虽然在模式串中是不存在的,如果直接移动模式串至好后缀的后面,那么就会错过正确匹配的情况,所以下图这样的移动方式就是错误的:
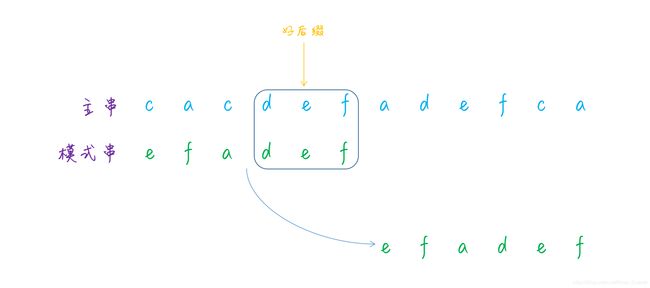
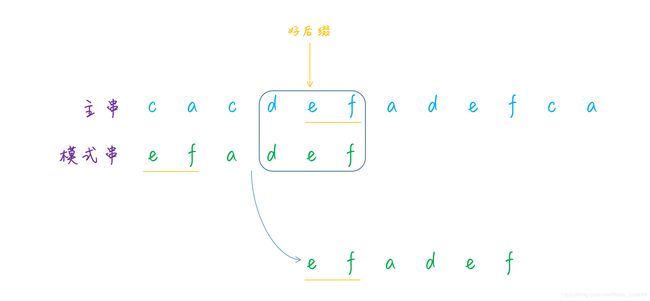
所以这种情况下应该怎么移动呢?可以看到,虽然好后缀 d e f 不在模式串中,但是好后缀的后缀子串 e f 和模式串的前缀子串 e f 是相同的,因此我们需要移动模式串至和好后缀的后缀子串重合的地方。
这段话稍微有点不好理解,再来解释一下,一个字符串的后缀子串,就是除了第一个字符的其余子串,例如字符串 d e f,它的后缀子串就有两个,分别是 f、e f;而一个字符串的前缀子串,就是除了最后一个字符的其余子串,例如 a d e f,它的前缀子串就有 a、a d、a d e 这三个。
具体到上面的那个例子,好后缀是 d e f ,它的一个后缀子串 e f 和模式串的前缀子串 e f 是匹配的,因此需要移动至两部分重合的地方:
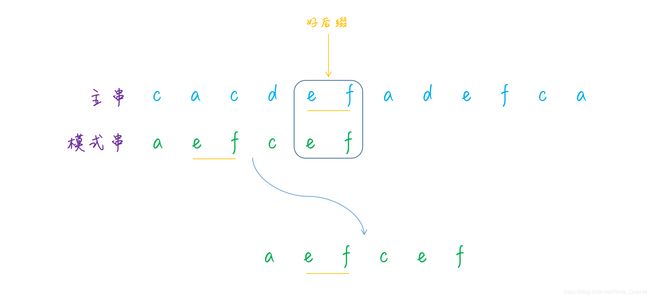
然后再看第二种情况,就很简单了,如果好后缀在模式串中是存在的,那么移动模式串至和好后缀匹配的地方:
总结一下规律,好后缀情况下,模式串的移动总体分为了三种情况,一是好后缀在模式串中,那么移动模式串至好后缀匹配的地方,二是好后缀不在模式串中,并且好后缀的后缀子串和模式串的前缀子串无重合部分,那么直接移动模式串至好后缀的后一位,三是好后缀不在模式串中,但是好后缀的后缀子串和模式串的前缀子串有重合部分,那么需要移动模式串至和好后缀的后缀子串重合的地方,参考下图:
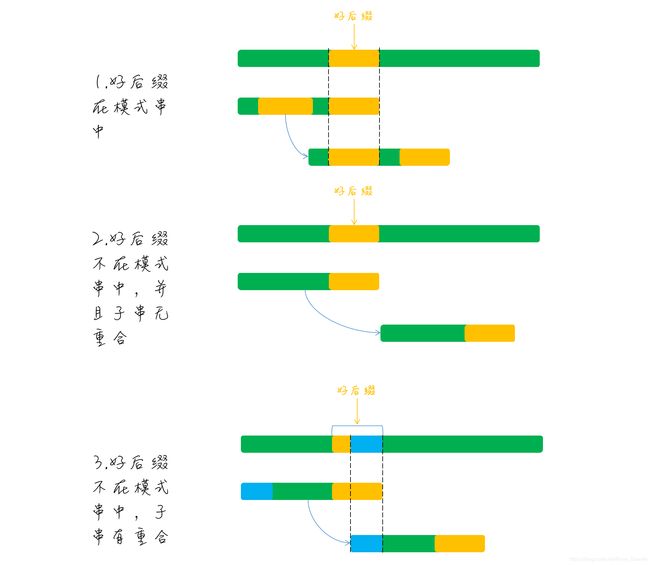
再来看看这部分的代码实现,因此好后缀本身也是在模式串中的,所以整个好后缀的匹配都可以通过预处理模式串来解决。
这里引入一个 int 类型的数组 suffix,长度为模式串的长度,数组的下标为模式串后缀子串的长度,值为后缀子串在模式串中可匹配的子串的起始下标;然后再引入一个 boolean 类型的 prefix 数组,它表示的是模式串的后缀子串是否有可匹配的前缀子串,如果有,则值为 true。

计算 suffix 数组和 prefix 数组的代码如下:
/**
* 生成好后缀数组
*/
private static void goodSuffixRule(String str, int[] suffix, boolean[] prefix){
if (str == null){
return;
}
Arrays.fill(suffix, -1);
Arrays.fill(prefix, false);
int n = str.length();
for (int i = 0; i < n - 1; i++){
int j = i;
int k = 0;
while (j >= 0 && str.charAt(j) == str.charAt(n - k - 1)){
--j;
++k;
suffix[k] = j + 1;
}
if (j == -1){
prefix[k] = true;
}
}
}
这段代码稍微有点难以理解,看的时候可以举一个具体的例子,然后根据代码推出来结果,这样理解起来会比较容易些。
根据生成的这两个数组,就可以计算在好后缀情况下的模式串移动位数,需要注意的是,前面坏字符情况下也有一个模式串移动的位数,这两者该如何选择呢?其实非常简单,我们当然希望模式串能够尽量多移动一点,因此只需要取这两个规则所计算出来的移动位数中的较大的那个值即可。
将坏字符规则和好后缀规则两种情况结合在一起,就是 BM 算法的完整实现,代码如下:
public class BoyerMoore {
private static final int[] badChar = new int[256];
public static int bm(String main, String ptn){
if (main == null || ptn == null){
return -1;
}
int m = main.length();
int n = ptn.length();
badCharRule(ptn, badChar);
int[] suffix = new int[n];
boolean[] prefix = new boolean[n];
goodSuffixRule(ptn, suffix, prefix);
int i = n - 1;
while (i <= m - 1) {
int j = n - 1;
while (j >= 0 && main.charAt(i) == ptn.charAt(j)){
--i;
if (--j == -1){
return i + 1;
}
}
//计算坏字符规则下移动的位数
int moveWithBC = j - badChar[main.charAt(i)];
//计算好后缀规则下移动的位数
int moveWithGS = Integer.MIN_VALUE;
if (j < n - 1){
moveWithGS = moveWithGS(n, j, suffix, prefix);
}
i += Math.max(moveWithBC, moveWithGS);
}
return -1;
}
/**
* 生成坏字符数组
*/
private static void badCharRule(String str, int[] badChar){
Arrays.fill(badChar, -1);
for (int i = 0; i < str.length(); i++) {
badChar[str.charAt(i)] = i;
}
}
/**
* 生成好后缀数组
*/
private static void goodSuffixRule(String str, int[] suffix, boolean[] prefix){
Arrays.fill(suffix, -1);
Arrays.fill(prefix, false);
int n = str.length();
for (int i = 0; i < n - 1; i++){
int j = i;
int k = 0;
while (j >= 0 && str.charAt(j) == str.charAt(n - k - 1)){
--j;
++k;
suffix[k] = j + 1;
}
if (j == -1){
prefix[k] = true;
}
}
}
/**
* 计算好后缀情况下的移动位数
*/
private static int moveWithGS(int n, int j, int[] suffix, boolean[] prefix){
int k = n - j - 1;
if (suffix[k] != -1){
return j - suffix[k] + 1;
}
for (int i = k - 1; i >= 0; i--) {
if (prefix[i]){
return n - i;
}
}
return n;
}
}
四、indexOf 方法解析
在 Java 语言中,常用的字符串匹配的方法是 String 类中的 indexOf() 方法,它的设计思路又是怎么样的呢?其实 indexOf 方法的逻辑非常简单,看看源代码就知道它其实就是 BF 算法的实现,其源代码是这样的:
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (targetCount == 0) {
return fromIndex;
}
char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount);
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}
主要的匹配逻辑在代码中的 for 循环这一段,可以看到匹配的过程主要分为了两步,第一步是找出第一个匹配的字符,然后再依次遍历模式串看是否匹配。这和 BF 算法的思路是一致的,只是代码实现上和上面我写的那个版本略有差别。
五、总结反思
现在回过头来总结一下,普通的字符串匹配算法,例如 BF 算法和 RK 算法,匹配的方式比较简单,相应的效率也不是很高,但实际上它们的应用还是较多的。因为在大多数情况下,如果匹配的字符串并不是很长的话,那么使用较简单的算法是一种更好的选择,代码也更加简单,维护的成本较低。这也是为什么 Java 中的字符串匹配 indexOf 方法采用了一种较简单的实现方式。
软件设计中有一个 Kiss 原则,即 Keep it simple & stupid,指的是在设计当中在能够解决问题的前提下,应该尽量注重简约,避免不必要的复杂性,这样系统维护的成本会降到最低。
但是在某些情况下,不得不应对更加复杂的字符串搜索场景,因此简单且效率底下的算法就不适用了,由此引出了 BM 算法,BM 算法是目前为止字符串匹配效率最高的算法之一,其效率可以达到著名的 KMP 算法的 3-5 倍。但是效率提升了,代码随之变得更加复杂,维护起来就会更加的困难。
有人可能会觉得,BM 算法这么复杂,就算我搞懂了,在实际的应用中也难以派的上用场。的确是这样的,我们几乎不可能遇到需要自己动手实现一个 BM 算法的场景,但是这并不代表算法就白学了。
算法的学习对逻辑思维的训练是比较好的,我自认为自己的逻辑思维能力是稍微差一点的,因此有时候会寻求一些刻意的训练,就拿 BM 算法来说,它解决问题的思路,对一些边界条件的处理,都对思维的严谨性起到了很好的提升作用。
学习算法其实主要学的是算法的思想,例如 BM 算法中的预处理思想,对模式串预先进行处理来提升匹配效率,这和现在的缓存技术的思想基本上是类似的,万变不离其宗,思路打开了,再去解决其他的一些问题才能够游刃有余。