简单聊聊NLP中的全局信息: Global information(第二弹)
全局信息第二弹来啦!接着上文,小编整理完了上次没能梳理完的三篇文章,请大家多多指教哦!
另外, 在公众号深度学习的知识小屋回复"全局信息", 将获取这次全局信息系列的六篇论文合集哦~
-
EMNLP2019: Extractive Summarization of Long Documents by Combining Global and Local Context
-
EMNLP2019: Hierarchical Modeling of Global Context for Document-Level Neural Machine Translation
-
EMNLP2019: Learning Dynamic Context Augmentation for Global Entity Linking
Extractive Summarization of Long Documents by Combining Global and Local Context
- url: https://www.aclweb.org/anthology/D19-1298.pdf
这篇文章的任务是完成抽取式的文本摘要,即通过直接从文本中抽取出重要的句子,来构成这篇文章summary的方法。然而作者注意到,越是篇幅较长的文章,就越可能是讨论了多个主题(topic), 尤其人们在写长文的时候,往往会把它们分为若干个章节(section)。基于此,作者提出 应当同时利用全局信息global context和local contextm来决定文章中的每个句子是否应该被保留下来作为摘要的内容, 而此处 global 和 local 的具体含义是:
- Global: The whole document
- Local: The section, topic

基于此,在本文提出的文本摘要模型,主要包括以下三个部分:
-
Sentence Encoder: 提供文本中每个句子的embedding表示 s e se se
在本文中,作者用Average Word Embedding的方法来生成句子表示,即对句子中所有词的词向量求平均,作为该句子的表示
s e = 1 n ∑ w 0 w n e m b ( w i ) , s e ∈ R d e m b se = \frac{1}{n}\sum_{w_0}^{w_n}emb(w_i), se \in \mathbb{R}^{d_{emb}} se=n1w0∑wnemb(wi),se∈Rdemb -
Document Encoder: Document Encoder需要完成三项工作,分别是学习文本中每个句子的表示 s r sr sr, 整篇文本的表示 d d d, 以及文本中每个topic的表示 l t l_t lt
-
Sentence Representation: 以每个句子的embedding作为输入,通过双向GRU学习每个句子的表示, 如图中A部分所示;
s r i = ( h t f : h t b ) , s r t ∈ R 2 ∗ d h i d sr_i = (h_t^f: h_t^b), srt \in \mathbb{R}^{2 * d_{hid}} sri=(htf:htb),srt∈R2∗dhid -
Document Representation: 以文章中第一个句子的后向表示和最后一个句子的前向表示的concat,作为整个篇章的表示,这也就是本文所用的global context, 如图中B部分所示:
d = ( h n f : h 0 b ) , d ∈ R 2 ∗ d h i d d= (h_n^f: h_0^b), d \in \mathbb{R}^{2 * d_{hid}} d=(hnf:h0b),d∈R2∗dhid -
Topic Segment Representation: 如图中C部分所示, 借鉴LSTM-Minus的方法,在通过BiGRU得到每个句子表示的基础上,根据topic将整篇文章划分若干个section, 每个section 含有若干个句子。对于第 t t t个部分对应的topic segment表示 l t l_t lt, 通过如下方法计算:
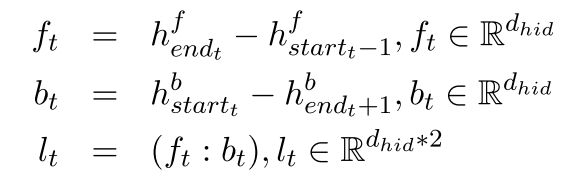
例如,对于Section2的表示为 l 2 = ( f 5 − f 2 , b 3 − b 6 ) l_2 = (f_5 - f_2, b_3 - b_6) l2=(f5−f2,b3−b6)。
-
-
Decoder: 相当于一个关于句子的分类器,根据 d d d (global context) 和 l l l (local context)用来判断某个句子 s t i st_i sti是否应该被保留下来构成summary,具体有两种方法可以计算:
- Concatentation
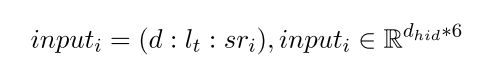
- Attentive Context: global context 和 local context 作为两种context,先分别求它们相对于句子 s r i sr_i sri的权重,通过加权方式得到一个总的context, 然后再进行concatentation:

得到 inputs 后,通过MLP+Sigmoid来得到句子是否要留下的概率:

- Concatentation
Hierarchical Modeling of Global Context for Document-Level Neural Machine Translation
- url: https://www.aclweb.org/anthology/D19-1168
这篇文章的任务,是篇章级别的机器翻译任务。根据前人的工作,作者指出
篇章级机器翻译的一个重要问题是, 独立地翻译每个句子,导致忽视了整个篇章提供的上下文。针对这一问题,前人提供了一些工作,用每个句子前文的上下文(pre-context)来指导句子的翻译。 然而,一个句子的 pre-context 与其后文的 context,所提供的信息还是存在一定的代沟,因此,只使用pre-context是不够的。
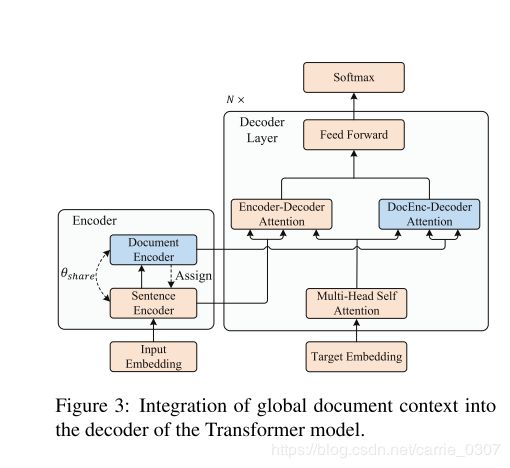
基于以上的问题,本文提出使用全局上下文 global context来提升篇章级机器翻译任务,设计了Hierarchical Modeling of Global Document Context (HM-GDC), 包含一个 (底层的)sentence encoder 对句子内的依赖进行建模, 上层的document encoder 对篇章级的句子间依赖进行建模,然后将global context信息进行融合。
- Sentence Encoder
假设一篇文章 D D D包含n个句子 ( S 1 , S 2 , . . . , S N ) (S_1, S_2, ..., S_N) (S1,S2,...,SN), 每个句子又包含若干个词 ( x i , 1 , . . . , x i , n ) (x_{i,1}, ..., x_{i,n}) (xi,1,...,xi,n), 则通过一个句子编码器(eg. BiRNN, Transformer) 对句子编码得到对应的表示 H i = ( h i , 1 , h i , 2 , . . . , h i , n ) ∈ R D ∗ n H_i = (h_{i,1}, h_{i,2}, ..., h_{i,n}) \in \mathbb{R}^{D * n} Hi=(hi,1,hi,2,...,hi,n)∈RD∗n
H i = S e n t E n c ( S i ) H_i = SentEnc(S_i) Hi=SentEnc(Si)
-
Document Encoder
用类似Transformer中多头注意力的方法,计算 H i H_i Hi 中每个 h j h_{j} hj的重要性并得到对应的 h S i ~ \tilde{h_{S_i}} hSi~, 然后通过篇章编码其 D o c E n c DocEnc DocEnc得到整篇文本的表示;具体如下所示,其中 h S i ∈ R D ∗ n h_{S_i} \in \mathbb{R}^{D * n} hSi∈RD∗n , h S i ~ ∈ R D ∗ n \tilde{h_{S_i}} \in \mathbb{R}^{D * n} hSi~∈RD∗n , h S ~ = ( h S 1 ~ , h S 2 ~ , . . . , h S N ~ ) ∈ R D ∗ n \tilde{h_{S}} = (\tilde{h_{S_1}},\tilde{h_{S_2}},...,\tilde{h_{S_N}}) \in \mathbb{R}^{D * n} hS~=(hS1~,hS2~,...,hSN~)∈RD∗n。

其中, D o c E N c DocENc DocENc表示一个篇章级别的编码器,使用 BiRNN 或 Transformer 来实现, H S ∈ R D ∗ N H_S \in \mathbb{R}^{D * N} HS∈RD∗N。 -
Backpropagation of global context
为了将文档级别的context交付到每个具体的word, 作者通过Multi-head Attention 来计算每个句子中的每个word所需要的对应上下文 d _ c t x i , j d\_{ctx}_{i,j} d_ctxi,j:
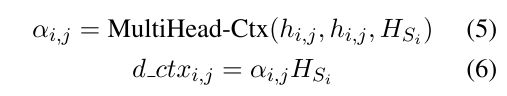
通过以上得到每个word对应的context信息后, 通过残差机制将每个word与其所对应的 d _ c t x i , j d\_{ctx}_{i,j} d_ctxi,j 融合:

其中, P P P 表示残差连接中的Dropout rate.
同样,为了将全局信息融入到Decode阶段, 除了一般的Encoder-Decoder架构外,作者又设计了 DocEnc-Decoder 通过多头Attention来融入全局信息, 具体如下( h _ c t x i h\_ctx_i h_ctxi 是第i个句子的表示):
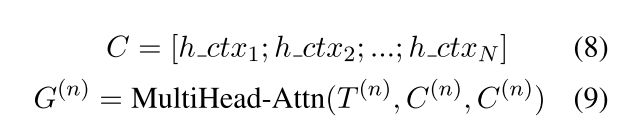
记 Encoder - Decoder 得到的输出为 E ( n ) E^{(n)} E(n), 则通过相加的方式将Encoder-Decoder和DocEnc-Decoder的结果进行融合:
H ( n ) = E ( n ) + G ( n ) H^{(n)} = E^{(n)}+G^{(n)} H(n)=E(n)+G(n)
Learning Dynamic Context Augmentation for Global Entity Linking
- url: https://www.aclweb.org/anthology/D19-1026.pdfl
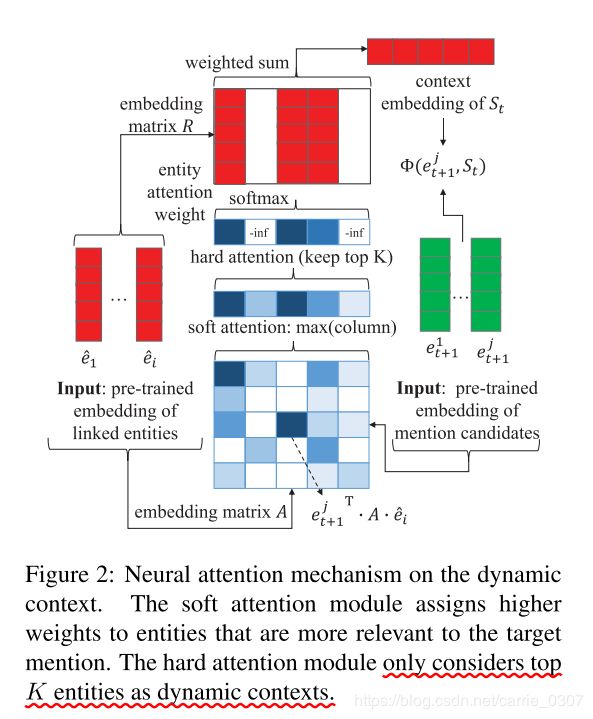
这篇文章的任务,是实体链指,而关于context的作者也给出了明确的定义: accumulate knowledge from previously linked entities as dynamic context to enhance later decisions.
假设将已链指过的实体集合记为 S t = { e 1 ^ , e 2 ^ , . . . , e i ^ } S_t=\{\hat{e_1}, \hat{e_2}, ..., \hat{e_i}\} St={e1^,e2^,...,ei^}, 其中 e i ^ \hat{e_i} ei^表示对应实体的embedding, 则通过对这些实体表示的聚合来构成增强的上下文。
当对第 m + 1 m+1 m+1个mention及对应候选实体 e t + 1 j e^j_{t+1} et+1j进行处理时,以 S t S_t St为参考,为了提高对上下文中相关实体的重要性以及过滤掉噪声信息,作者提出通过如图所示的attention机制方法来计算context:
-
首先计算 S t S_t St中每个实体的相关性分数
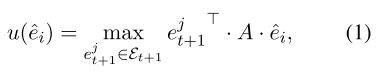
其中 A \rm{A} A 是一个可学习的对角矩阵, S t S_t St中的得分最高的Top K 个实体将被用来构成动态上下文,其他的则被丢弃;这些实体的得分将被转化为attention的权重:
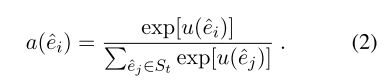
-
然后, 计算 e t + 1 j e_{t+1}^j et+1j与 S t S_t St的加权聚合分数:
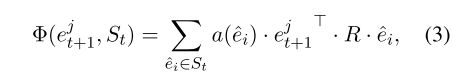
其中,R是一个可学习的对角矩阵;
为了增强链指模型的能力,作者除了使用之前链指过的实体 S t S_t St 外,还引入了 Wikipedia 中与 S t S_t St 中实体所相关的实体。具体地,对于 S t S_t St 中的每个实体 e i ^ \hat{e_i} ei^ , 我们收集 e i ^ \hat{e_i} ei^ 在Wikipedia中的邻居实体中与 e t + 1 j e_{t+1}^j et+1j 有链接关系的实体,将其记为 N ( e i ^ ) N(\hat{e_i}) N(ei^)。将 S t ′ S'_t St′ 记为 { \{ {N(\hat{e_i}) ∣ e i ^ ∈ S t } | \hat{e_i} \in S_t \} ∣ei^∈St}, 则用类似的方式计算 e t + 1 j e_{t+1}^j et+1j 与 S t ′ S'_t St′ 之间的聚合分数:

得到 Φ ( e t + 1 j , S t ) \Phi(e_{t+1}^j, S_t) Φ(et+1j,St) 与 Φ ′ ( e t + 1 j , S t ′ ) \Phi'(e_{t+1}^j, S_t') Φ′(et+1j,St′) 后,他们将与作者文中得到的其他特征一起,共同构成 e t + 1 j e_{t+1}^j et+1j 的表示。(其他特征的计算具体小编就不写啦,大家可以去论文中查阅哦~)
以上就完成了全局信息内容的整理!如有错误疏漏之处,还请大家多多包含并指出错误吖!另外!关注公众号深度学习的知识小屋并回复“全局信息”,小编就会将全局信息的六篇论文打包发给你哦~
了解更多深度学习相关知识与信息,请关注公众号深度学习的知识小屋
