《机器学习入门实战》第 01 篇 如何入门机器学习?
文章目录
- 机器学习与数据挖掘
- 传统入门方法的问题
- 逆向学习方法
- 专栏内容介绍
- 目标人群
- 专栏章节
机器学习与数据挖掘
如果你是一个想要入门数据科学的初学者,首先需要面对的就是各种相关的名词和概念。例如,什么是人工智能、机器学习、数据挖掘以及统计分析?简单来说,它们之间的关系如下图所示。

统计学是通过搜索、整理、分析、描述数据等手段,以达到推断所测对象的本质,甚至预测对象未来的一门综合性科学。统计学方法主要分为描述统计和推断统计;例如计算大学生身高的平均数、标准差以及收入和学历之间是否具有统计相关性都属于描述统计,而通过全国人口普查掌握全国人口的基本情况属于推断统计。
机器学习是人工智能(AI)的一个分支,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。机器学习专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
数据库是按照数据结构来组织、存储和管理数据的仓库;数据仓库(DW)是为了提供报告服务和决策支持的特定数据库。我们常见的数据库有 Oracle、MySQL、SQL Server、MongoDB、以及 Apace Hive、HBase 等。
数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘是集统计学、机器学习和数据库技术于一体的多学科领域。为了便于理解,我们可以将数据挖掘的作用分为两种:通过统计数据分析来解释过去以及基于机器学习算法预测未来,如下图所示。
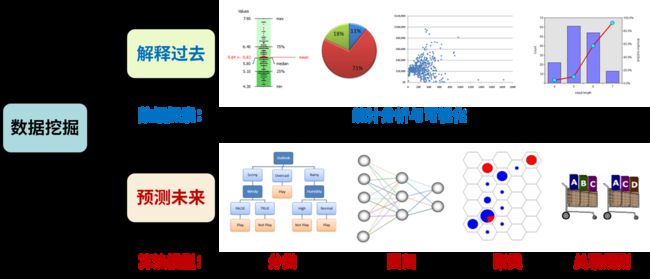
解释过去本质上也是为了能够预测未来。通过统计学和可视化的方法对数据进行探索,从而发现历史数据中的规律或者问题;并且为后续的数据挖掘与数据建模工作做好准备。
预测未来的主要方式是建立预测算法模型。如果预测结果是离散的类别值则称为分类,例如垃圾邮件检测、图像识别等;如果预测结果是连续的数值则称为回归,例如药物反应、股票价格预测等;聚类则是将相似的观测值分配同一个组中,例如用户画像、推荐系统等;关联规则可以在观察结果中找到事务的之间关联,例如哪些产品经常被一起购买。
机器学习领域提供了大量用于数据挖掘的算法,同时也给我们的选择带来一定的困难;下面是一个常见的机器学习算法速查表(英文原版),可以方便我们需要时查询。

知道这些概念之后,我们来讨论一下初学者应该如何入门机器学习。如果你去网络上搜索,大概会得到以下一些建议:
- 阅读专业书籍
- 学习 MOOC 课程
- 阅读各种博客文章
- 尝试 Kaggle/天池竞赛
不过,这些建议实际上大部分都不适合入门学习。学习一门技术或者技能的方法概括起来大概也就两种:理论先行或者实践先行。
传统入门方法的问题
大部分传统学习方法采用理论先行的方式,首先需要我们掌握的基础包括:
- 高等数学
- 微积分
- 概论论与统计
- 线性代数
- 信息论
- 计算机编程语言
- 数据结构与算法
- 机器学习算法
- 最优化理论
然后,我们可以开始实现简单的机器学习算法,参加一些相关领域的竞赛,尝试在实际工作中使用所学的知识。
对于任何初学者来说,如果一开始就要面对这么多的理论知识,不但耗时而且很容易影响学习的积极性。记得以前我们学习英语时,老师总是要求背诵各种单词,记住各种主谓宾、定状补的语法,而很少能够有理解语义的锻炼环境;导致现在还是有些拒绝学习英语。

传统的机器学习入门方法也存在同样的问题:过于专注理论算法和底层细节,而不是解决实际问题。
逆向学习方法
与传统学习方向相反的是,逆向学习方法采用实践先行的理念,以解决数据挖掘的实际问题驱动学习过程。想想我们小时候是怎么学会说话的,肯定不是先学各种拼音、汉字和语法,而是在实际生活中不断地听和说就自然会说话了;当然,想要成为语言学家肯定要研究这些语言细节,也需要付出比常人多很多倍的努力。

当然,并不是说不需要基础理论知识。理论非常重要,但是对于入门的初学者,应该先对整体的流程建立认知;然后再从实践到理论,有针对性的学习各个知识点。这样更容易获得成就感,提高学习的积极性,有利于初学者的入门。
因此,我们将会采用以下方法带领大家入门:
- 选择一个行业成熟的系统化流程;
- 选择适合初学者入门的工具平台;
- 专注于解决实际的数据挖掘问题;
- 针对性地扩展算法原理和知识点。
首先,我们需要站在前人的基础上;数据挖掘领域实际上很早就建立了成熟的行业流程,即 CRISP-DM(cross-industry standard process for data mining)。我们将其转换为以下流程图:

为了解决现实世界中的问题,我们通过采集原始数据,经过格式化、清洗、转换和特征选择等预处理,以及探索性数据分析,得到适合建立模型的数据;然后比较和选择不同的算法,对其进行评估和调优;反复整个过程最终获得并利用结果。
常见的机器学习和数据挖掘平台有很多,包括商业平台 SPSS、SAS 以及 Matlab 等;开源的 Python、R 语言等;大数据平台 Mahout、Spark 等。我们将会使用一个免费开源的机器学习平台:Orange。它是一个非常适合初学者入门的工具,提供了简单易用的图形操作界面,无需任何编程和算法基础就能完成各种机器学习和数据挖掘任务。以下是一个 Orange 分类工作流的界面。

不仅如此,Orange 基于 Python 开发,并且使用 Python 代码库进行科学计算,例如 numpy、scipy 以及 scikit-learn;高级用户既可以通过 Python 编程为其提供扩展的功能,也可以将其作为 Python 的一个编程模块使用。
专栏内容介绍
目标人群
本专栏以实战为主,面向零基础的初学者,学习的前提包括:
- 对数据挖掘和机器学习感兴趣;
- 无需程基础,但会使用计算机;
- 具有最基本的数学知识。
专栏章节
专栏预计包含以下内容:
- 如何入门机器学习?
- Orange 机器学习平台的安装与使用;
- 如何加载本地、网站以及数据库中的数据集;
- 数据预处理:缩放、转换以及缺失值处理;
- 数据的描述性统计分析与数据可视化探索;
- 第一个数据分类实战:识别鸢尾花的品种;
- 算法性能评估:交叉验证和评价指标;
- 常用分类算法性能比较实验;
- 利用集成学习提高机器学习的效果;
- 利用回归算法预测房价和股票走势;
- 通过聚类算法实现用户画像;
- 通过关联规则实现产品推荐;
- 通过特征工程提高模型的上限;
- 模型的保存与上线部署。
欢迎关注❤️、点赞、转发!