生磁盘的使用--OS
生磁盘的使用
首先认识一下磁盘是什么东西
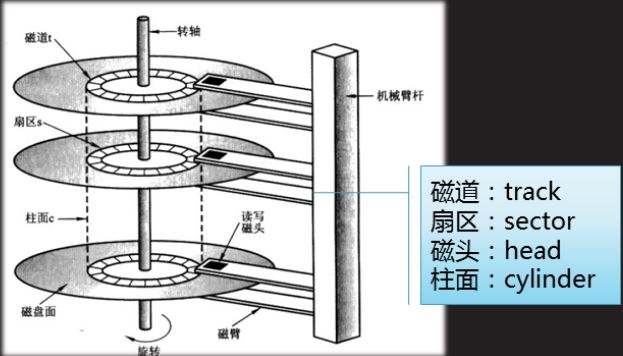
操作系统是如何使用磁盘的?
实际上简化为三步就是
- 磁头放在磁道上
- 旋转磁盘
- 磁生电进行IO读写操作
使用磁盘的最直观想法
就是往磁盘控制器写入柱面(cyl)、磁头(head)、扇区(sect)、缓存位置,然后让磁盘控制器完成磁盘读写操作
关键代码如下
void do_hd_request(void)
{
...
hd_out(dev,nect,sec,head,cyl,WIN_WRITE,...);
port_write(HD_DATA, CURRENT->buffer,256);
}
void hd_out(drive, nsect, sec, head, cyl, cmd...)
{
port = HD_DATA; //数据寄存器端口(0x1f0)
outb_p(nsect, ++port);
outb_p(sect, ++port);
outb_p(cyl, ++port);
outb_p(cyl>>8, ++port);
outb_p(0xA0 | (drive<<4) | head, ++port);
outb_p(cmd, ++port);
}
这样基本上就能使用磁盘了,但是太过复杂,用户必须要有磁头、扇区等数据,因此我们对磁盘的使用进行抽象。
通过盘块号读写磁盘(一层抽象)
通过盘块号(block)读写磁盘,磁盘驱动负责从block计算出cyl,head,sec(CHS);
问题是如何编址,才能让用户使用起来更高效,也就是block相邻的盘块可以快速的读出
磁盘访问时间主要花在寻道时间(磁头从起点开始,找到对应的磁道)
因此我们希望相邻盘块的盘块号尽量放在同一个磁道上
如何才能使相邻盘块的盘块号放在同一个磁道?我们观察一下磁盘的结构,实际上,一个磁道上有多个扇区,我们将相邻盘块放在这些扇区上,就能有效的减少寻道的次数,当第一个盘面的磁道的扇区被用完时,我们在柱面上寻找另一个磁道继续分配盘块,因为磁头是由机械臂杠控制的,所以多个磁头是同时寻道的,我们将其他盘块铺在柱面的其他磁道上,不用重新寻道,可以大大的减少时间,提高效率
盘块的计算公式为
block = C*(heads*sectors)+H*sectors+S
通过block就可以计算出C、H、S了
盘块和扇区的区别?
盘块实际上跟扇区差不多,但是操作系统可以控制盘块的大小,让磁盘一次性读取更多的数据,可以提高效率,因为数据读取非常快,但是也会造成空间浪费
代码如下
static void make_request()
{
struct request *req;
req = request + NR_REQUEST;
req->sector=bh->b_blocknr<<1;
add_request(major+blk_dev,req);
}
void do_hd_request(void)
{
unsigned int block=CURRENT->sector;
__asm__("div1 %4":"=a"(block),"=d"(sec):"0"(block),
"1"(0),"r"(hd_info[dev].sect));
__asm__("div1 %4:":"=a"(cyl),"=d"(head):"0"(block),
"1"(0),"r"(hd_info[dev].head));
hd_out(dev,nsect,sec,head,cyl.WIN_WRITE,...);
...
}
上面的代码就是根据block = C * (headssectors)+Hsectors+S公式计算出C,H,S
多个进程通过队列使用磁盘(第二层抽象)
当有多个进程要求使用磁盘时,操作系统维护一个队列保存各个进程申请的盘块号(block),现在问题就是如何设计调度算法,才能使磁盘访问变得更高效,也就是使寻道时间减少
FCFS磁盘调度算法
- 最公平、最简单的算法
但是这种算法极其低效,因为磁盘请求毫无规律,磁头做了大量的移动,因此我们希望磁头在移动时,如果遇到请求的磁道,就顺便将其读取。
SSTF磁盘调度
- 短磁道优先,Shortest-seek-time First
磁道短的先处理,由于系统读写频繁,磁头可能在一段区域内震荡,容易出现饥饿现象
C-SCAN磁盘调度
电梯算法: 每次都划到磁道距离最大的请求处,然后在寻道过程中顺便处理磁道短的请求,例如一个电梯最高楼层有人请求,则电梯直接到达最高楼层,然后再下楼时同时接上下面楼层的请求
算法实现
static void make_request()
{
...
req->sector = bh->b_blocknr<<1;
add_request(major+blk_dev,req);
}
static void add_request(struct blk_dev_struct *dev, struct request *req)
{
struct request *tmp = dev->current_request;
req->next = NULL;
cli();
for(;tmp->next;tmp=tmp->next)
if((IN_ORDER(tmp,req) || !IN_ORDER(tmp,tmp->next)) &&
IN_ORDER(req, tmp->next))
break;
req->next = tmp->next;
tmp->next = req;
sti();
}
#define IN_ORDER(s1, s2)\
((s1)->dev<(s2)->dev||((s1)->dev==(s2)->dev\
&& (s1)->sector<(s2)->sector))
我们看一下队列插入的这段代码
for(;tmp->next;tmp=tmp->next)
if((IN_ORDER(tmp,req) || !IN_ORDER(tmp,tmp->next)) &&
IN_ORDER(req, tmp->next))
break;
req->next = tmp->next;
tmp->next = req;
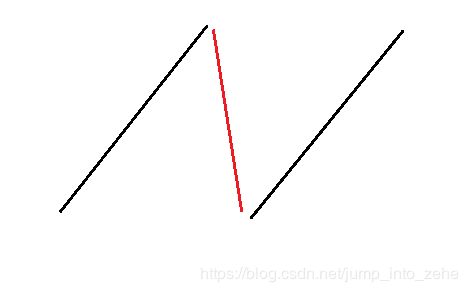
插入的条件有两个,第一个条件是
- tmp
- tmp
next, req next
可以想象一下,第一个条件形成的就是一个递增的队列,但是如果只有第一个条件,那这就变成了SSTF算法了,因此我们要让这个队列往下掉,也就是说不会形成一个递增的队列,当有较小的数时,我们将其插入其中,这样它就会往下掉了,相当于这条红线的作用了
生磁盘使用整理
- 进程“得到盘块号”,算出扇区号(sector)
- 用扇区号make req,用电梯算法add_requset
- 进程sleep_on
- 磁盘中断处理
- do_hd_request算出cyl,head,sectot
- hd_out调用outp(…)完成端口写