xlnet中文文本分类
X L N e t XLNet XLNet 模型由卡内基梅隆大学与 G o o g l e B r a i n Google Brain GoogleBrain 团队在 2019 年 6 月携手推出的 ,其在 20 项 N L P NLP NLP 任务中超过 B E R T BERT BERT 模型,且在其中 18 项任务中拿到最优成绩,包括机器问答、自然语言推断、情感分析和文档排序等。同 B E R T BERT BERT 一样,我这里就不讲原理了,网上各种博客对 X L N e t XLNet XLNet 的介绍都很详细,感兴趣的可以自己去搜索一下,我这里还是只讲文本分类的应用。
X L N e t XLNet XLNet 融合了自回归( A R AR AR,单向语言模型)、自编码( A E AE AE,双向语言模型)等语言模型特征,采用最先进的 t r a n s f o r m e r transformer transformer 特征提取器( t r a n s f o r m e r − x l transformer-xl transformer−xl,利用分割循环机制和相对位置编码进行高并发-超长文本处理),开创性地提出了排列语言模型。
自回归语言模型
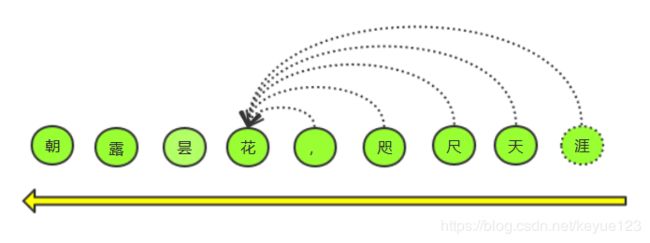
自回归( A R AR AR)是一种使用上下文词来预测下一个词的模型。但是上下文的方向只能使用前向或后向。
A R AR AR 的优势是擅长生成式自然语言处理任务。 因为在生成上下文时,通常是前向的,但是它也有自己的缺点,只能利用上文或者下文的信息,不能同时使用。

自编码语言模型
自编码( A E AE AE)采用的就是以上下文的方式,最典型的成功案例就是 B e r t Bert Bert。通过在输入语句中随机 M a s k Mask Mask 掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被 M a s k Mask Mask 掉的单词。

A E AE AE 能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文,但是它在预训练中使用 [ M A S K ] [MASK] [MASK],但这种 MASK 在真实数据中是不存在的,这就会导致预训练和微调的数据不统一,反而会带来一些人为的误差。
乱序语言模型
综合以上两种语言模型的弊端与优势, X L N e t XLNet XLNet 最大的贡献即为提出了乱序语言模型。乱序语言模型使用一个序列的所有可能排序方式来构建一个 A R AR AR 语言模型,理论上,如果模型的参数在所有的顺序中共享,那么模型就能学到从所有位置收集上下文信息。还是利用网上流行的序列 [ 1 , 2 , 3 , 4 ] [1, 2, 3, 4] [1,2,3,4] 来预测 3 的例子:
对于传统的 A R AR AR 模型来说,结果是
p ( 3 ) = ∐ t = 1 3 p ( 3 ∣ x < t ) {\rm{p}}(3) = \coprod\nolimits_{t = 1}^3 {p(3|x < t)} p(3)=∐t=13p(3∣x<t)
如果采用乱语言模型的方法,先对该序列进行因式分解,最终会有24种排列方式,下图是其中可能的四种情况

对于第一种情况因为3的左边没有其他的值,所以该情况无需做对应的计算,第二种情况3的左边还包括了2与4,所以得到的结果是 p ( 3 ) = p ( 3 ∣ 2 ) ∗ p ( 3 ∣ 2 , 4 ) p(3)=p(3∣2)∗p(3∣2,4) p(3)=p(3∣2)∗p(3∣2,4) ,同样的后两种情况分别是 p ( 3 ) = p ( 3 ∣ 1 ) ∗ p ( 3 ∣ 1 , 4 ) ∗ p ( 3 ∣ 1 , 4 , 2 ) p(3)=p(3∣1)∗p(3∣1,4)*p(3∣1,4,2) p(3)=p(3∣1)∗p(3∣1,4)∗p(3∣1,4,2), p ( 3 ) = p ( 3 ∣ 4 ) p(3)=p(3∣4) p(3)=p(3∣4),其他序列的情况都很类似,这时候我们会发现,乱续不但保留了序列的上下文信息,也避免了采用mask标记位,巧妙的改进了bert与传统AR模型的缺点。
但是单纯上面的语言建模是不成功的,因为因式分解顺序是任意的、训练目标是模糊的。因此,研究人员提出,对 T r a n s f o r m e r ( − X L ) Transformer(-XL) Transformer(−XL) 网络的参数化方式进行修改,移除模糊性。
模型架构:对目标感知表征的双流自注意力
针对上述优缺点, X L N e t XLNet XLNet 的作者又提出来对目标感知表征的双流自注意力。结合双流注意力和 T r a n s f o r m e r − X L Transformer-XL Transformer−XL 的改进,得到最终的排列语言建模架构。
中文分类
前面的章节简单的讲了 X L N e t XLNet XLNet 解决了之前语言模型的缺点并整合其优点,这里我们就开始进行实践。
X L N e t XLNet XLNet 的中文训练模型现在只有哈工大版本,模型采用的 s e n t e n c e p i e c e sentencepiece sentencepiece 做分词。官方推荐的 P y T o r c h PyTorch PyTorch 版本为 t r a n s f o r m e r s transformers transformers,安装和使用可以参考官方文档。这里还是使用深度学习(十二)-基于 Bert 的情感分析的数据。
- 数据处理
数据处理的方法依然跟 B e r t Bert Bert 一样,这里不多做介绍。
from transformers.tokenization_xlnet import XLNetTokenizer
class Processor(Base):
def __init__(self):
super(Processor, self).__init__()
self.tokenizer = XLNetTokenizer.from_pretrained(os.path.join(DATA_PATH, 'model', 'spiece.model')) # 加载分词模型
def _truncate_seq_pair(self, tokens_a, tokens_b, max_length):
while True:
total_length = len(tokens_a) + len(tokens_b)
if total_length <= max_length:
break
if len(tokens_a) > len(tokens_b):
tokens_a.pop()
else:
tokens_b.pop()
def convert_examples_to_features(self, text_a, text_b, seq_length):
tokens_a = self.tokenizer.tokenize(text_a) # 分词
tokens_b = None
if text_b:
tokens_b = self.tokenizer.tokenize(text_b)
if tokens_b:
self._truncate_seq_pair(tokens_a, tokens_b, seq_length - 3)
else:
if len(tokens_a) > seq_length - 2:
tokens_a = tokens_a[0:(seq_length - 2)]
tokens = []
segment_ids = []
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append('' )
segment_ids.append(0)
if tokens_b:
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append('' )
segment_ids.append(1)
tokens.append('' )
segment_ids.append(2)
input_ids = self.tokenizer.convert_tokens_to_ids(tokens) # 向量化
input_mask = [0] * len(input_ids)
if len(input_ids) < seq_length:
delta_len = seq_length - len(input_ids)
input_ids = [0] * delta_len + input_ids
input_mask = [1] * delta_len + input_mask
segment_ids = [4] * delta_len + segment_ids
return input_ids, input_mask, segment_ids
def input_x(self, text, ans_comment):
word_ids, word_mask, word_segment_ids = self.convert_examples_to_features(text_a=text, text_b=None, seq_length=128)
return word_ids, word_mask, word_segment_ids
- 准备模型
X L N e t XLNet XLNet 的模型也跟 B e r t Bert Bert 一样分了几个小模型,可以让用户根据需求来选择。我们这里使用 X L N e t F o r S e q u e n c e C l a s s i f i c a t i o n XLNetForSequenceClassification XLNetForSequenceClassification:
from transformers.modeling_xlnet import XLNetForSequenceClassification, XLNetConfig
xlnet_config = XLNetConfig.from_json_file(os.path.join(DATA_PATH, 'model', 'config.json')) # 加载模型初始化参数
xlnet_config.num_labels = 2 # 根据自己几分类来确定
xlnet_model = XLNetForSequenceClassification.from_pretrained(
pretrained_model_name_or_path=os.path.join(DATA_PATH, 'model', 'pytorch_model.bin'), config=xlnet_config) # 加载模型
- 优化/损失函数
- 优化
优化函数使用的是 A d a m Adam Adam, t r a n s f o r m e r transformer transformer 已经封装了对应的函数,可以直接调用, A d a m Adam Adam 的原理网上讲解的非常多,感兴趣可以自己去网上搜索。
from transformers.optimization import AdamW, WarmupLinearSchedule
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in xlnet_model.named_parameters() if not any(nd in n for nd in no_decay)],
'weight_decay': 0.01},
{'params': [p for n, p in xlnet_model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
# 优化函数
optimizer = AdamW(optimizer_grouped_parameters, lr=1e-4, eps=1e-6)
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=1000, t_total=10000)
- 损失
模型使用的为均方误差 ( M S E ) (MSE) (MSE),跟 B e r t Bert Bert 一样,直接封装在模型里面,不需要自己再定义。

模型训练
同 B e r t Bert Bert模型训练
模型测试
同 B e r t Bert Bert模型测试
总结
因为前面已经写过 B e r t Bert Bert 了,所以这里写的非常简单,感兴趣的可以留言或者私信一起讨论。