PAKDD2020 阿里巴巴智能运维算法大赛 总结(初赛33,决赛19)

赛题地址:PAKDD2020 阿里巴巴智能运维算法大赛-大规模硬盘故障预测
Githun代码地址:初赛+复赛
感谢另外两名队友的帮助,在整理资料和查阅文献方面给予了不少帮助。
另外一名队友的相关文章分析:磁盘故障预测问题比赛思路、难点与问题总结
问题描述
给定一段连续采集(天粒度)的硬盘状态监控数据(Self-Monitoring, Analysis, and Reporting Technology; often written as SMART)以及故障标签数据,参赛者需要自己提出方案,按天粒度判断每块硬盘是否会在未来30日内发生故障。例如,可以将预测故障问题转化为传统的二分类问题,通过分类模型来判断哪些硬盘会坏;或者可以转化为排序问题,通过Learning to rank的方式判断硬盘的损坏严重程度等。
初赛会提供训练数据集,供参赛选手训练模型并验证模型效果使用。同时,也将提供测试集,选手需要对测试集中的硬盘按天粒度进行预测,判断该硬盘是否会在未来30天内发生故障,并将模型判断出的结果上传至竞赛平台,平台会根据提交的预测结果,来评估模型预测的效果。
总的来说就是要在未来30天内,把会发生故障的硬盘找出来,只要提交的Log日期,距离真正坏的日期距离在30天内就算预测成功
数据描述
1)表1: disk_sample_smart_log_*.csv为SMART LOG数据表,共514列。每列的含义如下:
| 列名 | 字段类型 | 描述 |
|---|---|---|
| serial_number | string | 硬盘序列号代号 |
| manufacturer | string | 硬盘的厂商代号 |
| model | string | 硬盘型号代号 |
| smart_n_normalized | integer | SMART ID=n的归一化SMART数据 |
| smart_nraw | integer | SMART ID=n的SMART原始数据 |
| dt | string | 采集日期 |
smart_n_normalized和 smart_nraw是硬盘的smart数据,也就是原始特征,总共有510列,每个raw都对应有个normalized ,对于不同厂家,normalized的方式不一样,我们不得而知
2)表2: disk_sample_fault_tag.csv为故障标签表,共5列。每列含义如下:
| 列名 | 字段类型 | 描述 |
|---|---|---|
| serial_number | string | 硬盘序列号代号 |
| manufacturer | string | 硬盘的厂商代号 |
| model | string | 硬盘型号代号 |
| fault_time | string | 硬盘的故障时间 |
| tag | integer | 硬盘的故障类型代号 |
tag标签数据,给出的是所有坏了的硬盘的损坏日期,以及损坏类别。(一个disk可能有多种类型的损坏)
初赛训练集数据范围2017-07-31 至 2018-07-31。初赛A榜的测试集为disk_sample_smart_log_test_a.csv,数据范围为2018-08-01~2018-08-31整月的smart log数据,选手根据测试集数据按时间维度,每天预测硬盘是否会在未来30天内发生故障,例如: 8月1号的预测结果可以根据8月1号当天数据及历史数据来判断未来30天内哪些硬盘会出现故障,8月N号的预测结果可以根据8月N号当天数据及历史数据来判断未来30天内哪些硬盘会出现故障,以此类推。初赛测试集不提供故障label。
注:代码必须包含仿线上真实故障预测逻辑,即从9月1日开始按照时间顺序每天根据历史数据(含当天)构造特征,并将疑似坏盘的预测结果输出到规定文件当中,不允许出现’取30天预测结果中概率值最大的预测日作为输出’的情况;
提交的格式要求如下:
| manufacture | model | serial_number | dt |
|---|---|---|---|
| A | 1 | disk_1 | 2018-08-15 |
| A | 1 | disk_123 | 018-08-16 |
| A | 1 | disk_1 | 2018-08-17 |
| … | … | … | … |
比赛的指标是类似f1的评价指标,详细可以去官网查看下,这里就不过多介绍。另外为了防止选手投机,官方对线上的log数据在时间维度上做了截断处理。
数据处理
1、清洗数据
由于数据量非常大,全量数据大概有16G左右,所以我们对每个月的数据逐步分析,首先去除smart特征中,大量nan值以及单值特征,这些特征对于模型预测是无效的。在对特征进行精度转换。最后筛选出34列smart特征,单月数据内存缩小到400M左右。
2、数据分析
由于数据是以天为颗粒细度的log数据,每个disk 都有一串几乎连续的log数据,这是典型的时间序列数据,可以做传统的窗函数特征,统计特征,以及差分特征。对于每个smart,我们需要了解它的实质性含义,才能根据具体情况去做特征工程。smart数据说明标如下图:
表上的特征在比赛给的数据组并不是全都有,这就需要具体查看和分析了。
但是通过比赛发现,最有效的还是历史差分特征,它能体现disk的变异程度。对于窗函数的统计特征,发现在整个建模中表现都不是很好。(注意:为了防止leak,我们都只使用历史数据做特征工程)
相关性分析
比赛给的feature中,既有normalized也有raw,这两者之间存在着很强的相关性,为了减少数据内存,同时去除拢余的重复特征,用pandas进行了pearman相关分析,打得到如下相关矩阵:
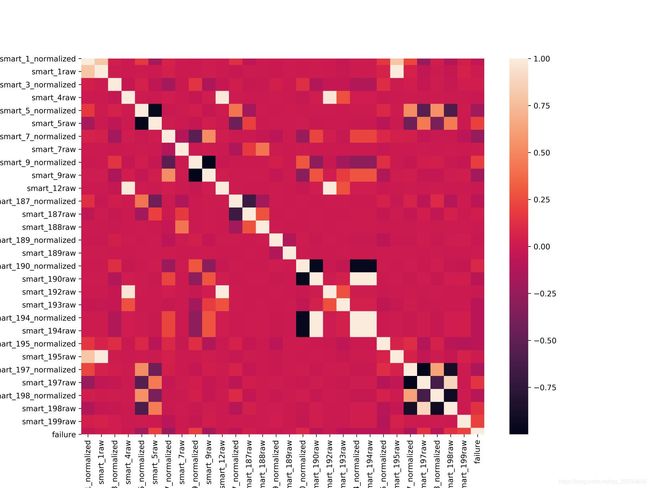
但是实际建模和验证发现,normalized和raw虽然相关性很高,但两都不能随便删除,否则对模型性能有一定影响,所以具体筛选还需要逐一验证,在设备条件足够好的情况下,可以不用考虑此问题!
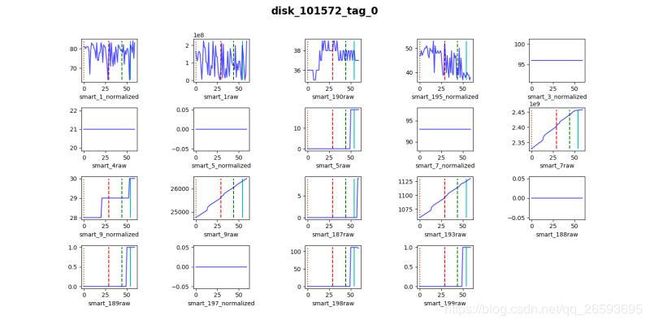
数据特点
特征之间分布差异还是比较大的,没有明显规律,并存在大量缺损值
特征工程
在做特征之前,对Nan值进行了处理,采用三次样条差值补全nan。
由于有些数据前后nan值缺失较多,无法插值补齐,故插值之后还有少量nan值。(这是个上分点)
lgb模型可以自动处理nan值,故插值未对少量nan值做后续处理。
对于数据的观察和分析,主要根据smart具体含义以及数据集分布的情况来制作特征,我们发现大多数特征基本上在bad与good的disk中并没有明显的分布差异。并且由于样本极度不均衡,我们很难从中找到一定的分布规律。
但是通过实验我们发现差分特征是个强有效的特征!

1、时序的差分特征
用当前log的feature与之前log的feature做差值,时间间隔可以取
例如 1 3 7,但由于设备有限,支撑不了这么多特征,
所以选取了部分特征做差值,同时取1 3 7 间隔差值的mean 来将三个
不同时间间隔的特征融合成一个。
2、初始状态变化特征
同样用当前log的feature与serial表中,disk的初始状态做差值,同样由于设备内存限制,只选了几个做,如果全做,效果会好很多。
3、disk使用时长
一般来说disk 使用的时间越久,坏的机率越大
serve_time=dt-init_dt
4、数据丢失率特征
通过观察数据分布,发现数据缺失越多,越容易发生故障。
miss_data_rate=(disk当前为止所有log数量)/(disk使用时长)
5、其他特征
比如加窗的统计特征,由于是时间序列,可以构建加窗的聚合函数
由于设备原因,以及这些特征构建后发现效果不是很明显,故舍去
6、尝试的特征提取
对于时序数据,采用LSTM提取时序特征,初步尝试,效果不好,可能是数据
预处理不恰当,后期可以继续尝试。对于连续特征和部分可以当作离散特征的高阶
组合,可以采用DNN,FM 进一步挖掘。
(对于数据的预处理还尝试用Log平滑化,以及标准化处理,但是从结果上看,由于分布差异较大,标准化会改变feature一些特性,所以舍去这部分处理)
复赛阶段:
相对于初赛增加了一些特征:
1、curr rate :当天统计分数,即特征在当天log中的评分
2、model count:发现disk分布中 拥有两种model的disk 坏其中一个的概率较大
3、 gather erro: 选取了几种对于错误描述的smart进行累和。
4、 gct_change: 带窗函数的特征变化率
5、 ewm_calculate: 指数平滑 取mean 和std
6、 ewm_var_diff : var*diff 增大变异程度
7、 scale_smart : raw/normlized 一种规范化的方式
8、 diff_cumsum : 在原差分的基础上,做了积分,仿照dpi类似的思想,累计误差
9、 data_smoother: 一种加权的线下处理
10、 tag_predict :给每个disk 打上tag的标签,一定程度上预知坏的类别
建模
初赛
初赛的时候采样用的是二分类lgb模型,对于距离坏日期小于30的disk的log数据标记为1 正样本,大于30天的标记为负样本,由于正负样本及其不均,lgb添加了is_unbalance =True,后期也尝试过用SMOTE做样本均衡,采用负采样或者生成正样本的策略,但是实际测试效果没有很大的提升,可能是训练样本的数据集没有构造好,或者lgb模型对于不均衡样本的处理已经很优秀了。
当然我们也尝试了一些nn模型,比如dppfm,lstm等,但是效果都不佳,这可能是nn模型对数据比较敏感,对大量缺失值的数据不太好处理,同时不同数据间的分布尺度差异也比较大。lgb或者catbosst,xgb这类的随机森林模型效果会比较好。
复赛
复赛阶段,重新换了个思路,采用回归模型,我们只需要得到对于disk的log,判断其坏的可能性,只要设置合适的阈值,就能把距离坏日期小于30天的log筛选出来。
这里需要注意的一点是,打标签的方式,不同的方式,对于模型的预测效果影响非常巨大,我们尝试了多种方式,最终确定的方式如下:
| gap_day | label |
|---|---|
| >30 | 0 |
| 20<=gap_day<30 | 10 |
| 10<=gap_day<20 | 20 |
| 5<=gap_day<10 | 30 |
| 2<=gap_day<5 | 40 |
| gap_day<2 | 100 |
相对于初赛的建模方式,采用回归建模,分数能多上十个点左右。
值得注意的是,比赛结束后,发现第一名也是该用回归建模的,但是奇怪的是他们label的方式和我们不同,他们的label是0,1,2,3…,31,gap_day 大于30天的label为1,小于30天的label分别为1 2 3… 以此类推。
这种方式的label我们最初也尝试过,但是效果特别差。我们最后分析的原因可能是因为我们的部分特征和时间序列强相关,导致模型不能很好的根据特征来区分,而只能预测出一种变化趋势。(总之这还是比较玄学的,我们的特征和思路和第一名几乎一致,但是分数却相差挺大的,细节部分也不好探究,感兴趣的读者可以做做实验,对比下两种标签的差异和性能)
总结
1、线上策略
在整个比赛过程中,主要的亮点在于建模方式和思考问题的角度。其次,本次比赛的评价指标主要是f1,而f1对于阈值是非常敏感的,所以我们大量工作也是在于如何选取一个较好的阈值,我们提出了一些选取策略,比如阈值搜索,排序,投票,以及根据每天的disk数量的动态阈值方式等等。具体的选取策略可以在代码中查看。
2、特征筛选
其次,特征工程还有一个很重要的方面就是特征筛选,我们最初是根据随机森林分类器的特点,得到特征重要度的排序,去除一些贡献为0或者较小的特征。但是后来发现这种方式不太可取,有些特征虽然贡献度小,但是对于模型影响比较大,其次部分特征可能要和其他特征组合才能强有效。所以后期我们具体分析了特征的含义,启发式地赛选特征。当然也尝试了sklearn的一些特征筛选的算法,但是对于这种大规模的数据不是一个很好的方式。
3、训练集构建
本次比赛数据还有一个特点就是用全量的数据进行增量的模型训练效果并不理想,我们采用两个月的数据隔月验证的方式是最好的。比如4,5月数据训练,7月数据进行验证。这是因为label的时间维度上跨度为30天,为了防止leak,这样做是必须的。其次,如果将前一个月,比如6月的坏盘数据加入到训练,反而会让模型不收敛。原因可能是同一个disk的log好坏区分度不大,如果放在用一个训练集中,容易让模型confused而无法收敛。所以比赛的训练集构建也很关键,具体用哪两个月的数据集作为训练也是个隐藏的上分点。
摘取另一名队友的问题总结:
4、文献
在比赛过程中查阅了以往大量关于disk预测的文献,并对里面的一些方案进行了复现,从这次的比赛中也发现了,很多论文提到的方法,在实际比赛和工业中并不一定适用,由于内存限制或者数据集分布的差异。而往往简单粗暴的方法更能达到好的效果。
下面是比赛期间收集的部分论文:
-
[1] Shen, J., Wan, J., Lim, S. J., & Yu, L. (2018). Random-forest-based failure prediction for hard disk drives. International Journal of Distributed Sensor Networks, 14(11). https://doi.org/10.1177/1550147718806480
-
[2] Han, S., Wu, J., Xu, E., He, C., Lee, P. P. C., Qiang, Y., … Li, R. (2019). Robust Data Preprocessing for Machine-Learning-Based Disk Failure Prediction in Cloud Production Environments. Retrieved from http://arxiv.org/abs/1912.09722
-
[3] Zhang, J., Zhou, K., Huang, P., He, X., Xie, M., Cheng, B., … Wang, Y. hu. (2020). Minority Disk Failure Prediction based on Transfer Learning in Large Data Centers of Heterogeneous Disk Systems. IEEE Transactions on Parallel and Distributed Systems. https://doi.org/10.1109/TPDS.2020.2985346
-
[4] Li, J., Stones, R. J., Wang, G., Li, Z., Liu, X., & Xiao, K. (2016). Being Accurate Is Not Enough: New Metrics for Disk Failure Prediction. Proceedings of the IEEE Symposium on Reliable Distributed Systems, 71–80. https://doi.org/10.1109/SRDS.2016.019
-
[5] Kaur, K., & Kaur, K. (2019). Failure prediction, lead time estimation and health degree assessment for hard disk drives using voting based decision trees. Computers, Materials and Continua, 60(3), 913–946. https://doi.org/10.32604/cmc.2019.07675
-
[6] Jiang, T., Zeng, J., Zhou, K., Huang, P., & Yang, T. (2019). Lifelong disk failure prediction via GAN-based anomaly detection. Proceedings - 2019 IEEE International Conference on Computer Design, ICCD 2019, (Iccd), 199–207. https://doi.org/10.1109/ICCD46524.2019.00033
-
[7] Yang, W., Hu, D., Liu, Y., Wang, S., & Jiang, T. (2015). Hard Drive Failure Prediction Using Big Data. Proceedings of the IEEE Symposium on Reliable Distributed Systems, 2016-January, 13–18. https://doi.org/10.1109/SRDSW.2015.15
-
[8] Lu, S., Luo, B., Clara, S., Lu, S., & Luo, B. (2020). Making Disk Failure Predictions SMARTer ! Fast
-
[9] Basak, S., Sengupta, S., & Dubey, A. (2019). Mechanisms for integrated feature normalization and remaining useful life estimation using LSTMs applied to hard-disks. Proceedings - 2019 IEEE International Conference on Smart Computing, SMARTCOMP 2019, 208–216. https://doi.org/10.1109/SMARTCOMP.2019.00055
-
[10] Botezatu, M., Giurgiu, I., Bogojeska, J., & Wiesmann, D. (2016). Predicting disk replacement towards reliable data centers. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 13-17-August-2016(1), 39–48. https://doi.org/10.1145/2939672.2939699
-
[11] 硕士学位论文 基于在线学习的磁盘故障预测技术. (2018).
Lewis, B., Smith, I., Fowler, M., & Licato, J. (2017). The robot mafia: A test environment for deceptive robots. 28th Modern Artificial Intelligence and Cognitive Science Conference, MAICS 2017, 189–190. https://doi.org/10.1145/1235