Spark ML 分布式机器学习(二):pipeline
一、pipeline主要概念
pipeline在结构上把原有的机器学习各个流程整合成一个流水线式的工作流程。一个完整的pipeline主要有:DataFrame、Transformer、Estimator、pipeline以及parameter。一个pipeline在结果是会包含一个或多个步骤,每个步骤都会完成相应的任务,如数据的处理转化、模型训练,参数设置以及模型预测等,而最主要的两个步骤为Transformer和Estimator。Transformer主要来操作一个DataFrame生成另一个DataFrame,这个Transformer可以是一个特征提取工具或者时一个Model。Estimator主要用于模型拟合用的,是通过DataFrame拟合一个Model,也就生成了一个TransFormer。
二、其工作原理
以文本数据为例,在TrainData上pipeline的工作机制:
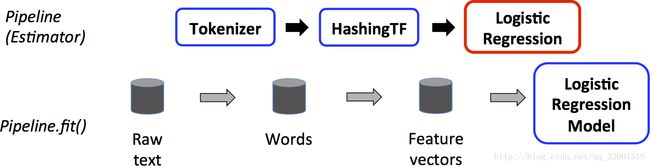
备注:蓝色框是TransFormer所用具体的方法,红色是Estimator所fit()的算法Model。灰色圆柱是DataFrame。
原始文本数据Rawtext,经过分词器Tokenizer进行分词,得到词数据,然后通过哈希变换HashingTF转换成特征向量,然后利用Estimator的fit()进行训练一个Model(如,LR模型)。
在TestData上pipeline的工作机制:
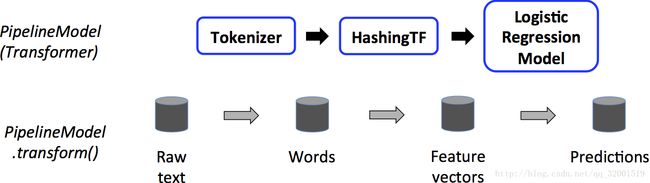
在TestData上是用的训练得来的Model,其实也是个Transformer,然后把TestData进行上述的预处理操作,得到特征向量,然后放到已经得到好的model中得到Prdictions。
示例代码可以参考官网指南python部分。
参考链接:1、http://blog.csdn.net/liulingyuan6/article/details/53576550
2、http://spark.apache.org/docs/latest/ml-pipeline.html
3、http://blog.csdn.net/zbc1090549839/article/details/50935274