Spark MLlib分布式机器学习源码分析:朴素贝叶斯
Spark是一个极为优秀的大数据框架,在大数据批处理上基本无人能敌,流处理上也有一席之地,机器学习则是当前正火热AI人工智能的驱动引擎,在大数据场景下如何发挥AI技术成为优秀的大数据挖掘工程师必备技能。本文结合机器学习思想与Spark框架代码结构来实现分布式机器学习过程,希望与大家一起学习进步~
目录
1.贝叶斯模型思想
2.贝叶斯模型原理
3.Spark实例
4.源码分析
(1)计算每个标签对应的term的频率
(2)迭代计算p(C)和p(F|C)
本文采用的组件版本为:Ubuntu 19.10、Jdk 1.8.0_241、Scala 2.11.12、Hadoop 3.2.1、Spark 2.4.5,老规矩先开启一系列Hadoop、Spark服务与Spark-shell窗口:

1.贝叶斯模型思想
朴素贝叶斯是一种简单的多类分类算法,假设每对特征之间具有独立性。朴素贝叶斯可以非常有效地训练。在一次传递训练数据的过程中,它计算给定标签的每个特征的条件概率分布,然后应用贝叶斯定理计算给定观察值的标签的条件概率分布,并将其用于预测。
举个例子,如果一种水果其具有红,圆,直径大概3英寸等特征,该水果可以被判定为是苹果。尽管这些特征相互依赖或者有些特征由其他特征决定,然而朴素贝叶斯分类器认为这些属性在判定该水果是否为苹果的概率分布上独立的。朴素贝叶斯的优缺点:
-
优点:学习和预测的效率高,且易于实现;在数据较少的情况下仍然有效,可以处理多分类问题。
-
缺点:分类效果不一定很高,特征独立性假设会是朴素贝叶斯变得简单,但是会牺牲一定的分类准确率。
2.贝叶斯模型原理
从统计学知识回到我们的数据分析。假如我们的分类模型样本是:
![]()
即我们有m个样本,每个样本有n个特征,特征输出有K个类别,定义为:![]() ,从样本我们可以学习得到朴素贝叶斯的先验分布
,从样本我们可以学习得到朴素贝叶斯的先验分布![]() ,接着学习到条件概率分布
,接着学习到条件概率分布![]() ,然后我们就可以用贝叶斯公式得到X和Y的联合分布P(X,Y)了。联合分布P(X,Y)定义为:
,然后我们就可以用贝叶斯公式得到X和Y的联合分布P(X,Y)了。联合分布P(X,Y)定义为:
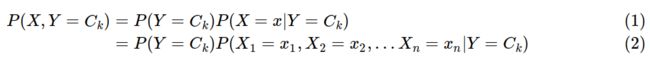
从上面的式子可以看出![]() 比较容易通过最大似然法求出,得到的
比较容易通过最大似然法求出,得到的![]() 就是类别在训练集里面出现的频数。但是
就是类别在训练集里面出现的频数。但是![]() 很难求出,这是一个超级复杂的有n个维度的条件分布。朴素贝叶斯模型在这里做了一个大胆的假设,即X的n个维度之间相互独立,这样就可以得出:
很难求出,这是一个超级复杂的有n个维度的条件分布。朴素贝叶斯模型在这里做了一个大胆的假设,即X的n个维度之间相互独立,这样就可以得出:

从上式可以看出,这个很难的条件分布大大的简化了,但是这也可能带来预测的不准确性。你会说如果我的特征之间非常不独立怎么办?如果真是非常不独立的话,那就尽量不要使用朴素贝叶斯模型了,考虑使用其他的分类方法比较好。但是一般情况下,样本的特征之间独立这个条件的确是弱成立的,尤其是数据量非常大的时候。虽然我们牺牲了准确性,但是得到的好处是模型的条件分布的计算大大简化了,这就是贝叶斯模型的选择。
既然是贝叶斯模型,当然是后验概率最大化来判断分类了。我们只要计算出所有的K个条件概率 ![]() 然后找出最大的条件概率对应的类别,这就是朴素贝叶斯的预测了。
然后找出最大的条件概率对应的类别,这就是朴素贝叶斯的预测了。
3.Spark实例
spark.mllib支持多项式朴素贝叶斯和Bernoulli朴素贝叶斯。这些模型通常用于文档分类。在这种情况下,每个观察值都是一个文档,每个特征都代表一个术语,其值是该术语的出现频率(在多项式朴素贝叶斯中),或者为零或一个,表示该术语是否在文档中找到(在Bernoulli朴素贝叶斯中)。特征值必须为非负数。使用可选参数“ multinomial”或“ bernoulli”(默认值为“ multinomial”)选择模型类型。可以通过设置参数λ(默认值为1.0)来使用加法平滑。对于文档分类,输入特征向量通常是稀疏的,应提供稀疏向量作为输入,以利用稀疏性。由于训练数据仅使用一次,因此无需将其缓存。
NaiveBayes实现多项式朴素贝叶斯。它以LabeledPoint的RDD和可选的平滑参数lambda作为输入,可选的模型类型参数(默认为“多项式”)作为输入,并输出NaiveBayesModel(可用于评估和预测)。
import org.apache.spark.mllib.classification.{NaiveBayes, NaiveBayesModel}import org.apache.spark.mllib.util.MLUtils// 加载数据文件val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")// 切分数据集:训练集60% 测试集40%val Array(training, test) = data.randomSplit(Array(0.6, 0.4))val model = NaiveBayes.train(training, lambda = 1.0, modelType = "multinomial")val predictionAndLabel = test.map(p => (model.predict(p.features), p.label))val accuracy = 1.0 * predictionAndLabel.filter(x => x._1 == x._2).count() / test.count()// 保存和加载模型model.save(sc, "target/tmp/myNaiveBayesModel")val sameModel = NaiveBayesModel.load(sc, "target/tmp/myNaiveBayesModel")
4.源码分析
从上文的原理分析我们可以知道,朴素贝叶斯模型的训练过程就是获取概率p(C)和p(F|C)的过程。根据MLlib的源码,我们可以将训练过程分为两步。第一步是聚合计算每个标签对应的term的频率,第二步是迭代计算p(C)和p(F|C)。
(1)计算每个标签对应的term的频率
val aggregated = data.map(p => (p.label, p.features)).combineByKey[(Long, DenseVector)](createCombiner = (v: Vector) => {if (modelType == Bernoulli) {requireZeroOneBernoulliValues(v)} else {requireNonnegativeValues(v)}(1L, v.copy.toDense)},mergeValue = (c: (Long, DenseVector), v: Vector) => {requireNonnegativeValues(v)//c._2 = v*1 + c._2BLAS.axpy(1.0, v, c._2)(c._1 + 1L, c._2)},mergeCombiners = (c1: (Long, DenseVector), c2: (Long, DenseVector)) => {BLAS.axpy(1.0, c2._2, c1._2)(c1._1 + c2._1, c1._2)}//根据标签进行排序).collect().sortBy(_._1)
这里我们需要先了解createCombiner函数的作用。createCombiner的作用是将原RDD中的Vector类型转换为(long,Vector)类型。
如果modelType为Bernoulli,那么v中包含的值只能为0或者1。如果modelType为multinomial,那么v中包含的值必须大于0。
//值非负val requireNonnegativeValues: Vector => Unit = (v: Vector) => {val values = v match {case sv: SparseVector => sv.valuescase dv: DenseVector => dv.values}if (!values.forall(_ >= 0.0)) {throw new SparkException(s"Naive Bayes requires nonnegative feature values but found $v.")}}//值为0或者1val requireZeroOneBernoulliValues: Vector => Unit = (v: Vector) => {val values = v match {case sv: SparseVector => sv.valuescase dv: DenseVector => dv.values}if (!values.forall(v => v == 0.0 || v == 1.0)) {throw new SparkException(s"Bernoulli naive Bayes requires 0 or 1 feature values but found $v.")}}
mergeValue函数的作用是将新来的Vector累加到已有向量中,并更新词率。mergeCombiners则是合并不同分区的(long,Vector)数据。通过这个函数,我们就找到了每个标签对应的词频率,并得到了标签对应的所有文档的累加向量。
(2)迭代计算p(C)和p(F|C)
//标签数val numLabels = aggregated.length//文档数var numDocuments = 0Laggregated.foreach { case (_, (n, _)) =>numDocuments += n}//特征维数val numFeatures = aggregated.head match { case (_, (_, v)) => v.size }val labels = new Array[Double](numLabels)//表示logP(C)val pi = new Array[Double](numLabels)//表示logP(F|C)val theta = Array.fill(numLabels)(new Array[Double](numFeatures))val piLogDenom = math.log(numDocuments + numLabels * lambda)var i = 0aggregated.foreach { case (label, (n, sumTermFreqs)) =>labels(i) = label//训练步骤的第5步pi(i) = math.log(n + lambda) - piLogDenomval thetaLogDenom = modelType match {case Multinomial => math.log(sumTermFreqs.values.sum + numFeatures * lambda)case Bernoulli => math.log(n + 2.0 * lambda)case _ =>// This should never happen.throw new UnknownError(s"Invalid modelType: $modelType.")}//训练步骤的第6步var j = 0while (j < numFeatures) {theta(i)(j) = math.log(sumTermFreqs(j) + lambda) - thetaLogDenomj += 1}i += 1}
这段代码计算上文提到的p(C)和p(F|C)。这里的lambda表示平滑因子,一般情况下,我们将它设置为1。代码中,p(c_i)=log (n+lambda)/(numDocs+numLabels*lambda),这对应上文训练过程的第5步prior(c)=N_c/N。
根据modelType类型的不同,p(F|C)的实现则不同。当modelType为Multinomial时,P(F|C)=T_ct/sum(T_ct),这里sum(T_ct)= sumTermFreqs.values.sum + numFeatures * lambda。这对应多元朴素贝叶斯训练过程的第10步。当modelType为Bernoulli时,P(F|C)=(N_ct+lambda)/(N_c+2*lambda)。这对应伯努利贝叶斯训练算法的第8行。需要注意的是,代码中的所有计算都是取对数计算的。
Spark朴素贝叶斯的内容至此结束,有关Spark的基础文章可参考前文:
Spark MLlib分布式机器学习源码分析:矩阵向量
Spark MLlib分布式机器学习源码分析:基本统计
Spark MLlib分布式机器学习源码分析:线性模型
Spark大数据分布式处理实战笔记(一):快速开始
Spark大数据分布式处理实战笔记(二):RDD、共享变量
Spark大数据分布式处理实战笔记(三):Spark SQL
Spark大数据分布式处理实战笔记(四):Spark Streaming
Spark大数据分布式机器学习处理实战
Spark大数据分布式图计算处理实战
参考链接:
https://github.com/endymecy/spark-ml-source-analysis
https://www.cnblogs.com/pinard/p/6069267.html
![]()
历史推荐
“高频面经”之数据分析篇
“高频面经”之数据结构与算法篇
“高频面经”之大数据研发篇
“高频面经”之机器学习篇
“高频面经”之深度学习篇
爬虫实战:Selenium爬取京东商品
爬虫实战:豆瓣电影top250爬取
爬虫实战:Scrapy框架爬取QQ音乐

数据分析与挖掘
数据结构与算法
机器学习与大数据组件
欢迎关注,感谢“在看”,随缘稀罕~
