图神经网络学习记录:《图神经网络综述:模型与应用》
Graph Neural Networks: A Review of Methods and Applications
摘要:大量的学习任务要求处理元素间含有丰富关系信息的图形数据。物理系统的建模、分子指纹的学习、蛋白质界面的预测和疾病的分类都需要模型从图形输入中学习。在其他领域,如文本、图像等非结构数据的学习中,提取结构的推理,如句子的依赖树和图像的场景图,是一个需要图推理模型的重要研究课题。图神经网络 (GNN) 是一种连接模型,它通过图的节点之间的消息传递来捕捉图的依赖关系。与标准神经网络不同的是,图神经网络保留了一种状态,可以表示来自其邻域的具有任意深度的信息。虽然发现原始的 GNN 很难为一个固定点进行训练,但是网络结构、优化技术和并行计算的最新进展使它们能够成功地学习。近年来,基于图卷积网络 (GCN) 和门控图神经网络 (GGNN) 的系统在上述众多任务中表现出突破性的性能。在本综述中,我们对现有的图神经网络模型进行了详细的回顾,对应用进行了系统的分类,并提出了四个有待进一步研究的问题。
1. Introduction
图是一种数据结构,它为一组对象(节点)及其关系(边)建模。近年来,机器学习图分析的研究越来越受到人们的重视,因为图有很强的表达能力,可以作为许多系统的外延,包括社会科学 (social networks) , 自然科学 (物理系统和蛋白质相互作用网络) , 知识图谱等许多研究领域。图分析作为一种用于机器学习的独特的非欧几里得数据结构,主要集中在节点分类、链接预测和聚类等方面。图神经网络(GNN)是在图域上运行的基于深度学习的方法。GNN 以其令人信服的性能和较高的可解释性,近年来已成为一种广泛应用的图论分析方法。在下面几段中,我们将说明图神经网络的基本动机。
GNNs 的第一个动机源于卷积神经网络 (CNN)。CNN能够提取多尺度的局部空间特征并将其组合起来,构建出高度表达的表示形式,在几乎所有的机器学习领域都取得了突破,开启了深度学习的新时代。然而,CNN只能处理常规的欧几里德数据,如图像(2D 网格)和文本(1D 序列),而这些数据结构可以看作是图的实例。随着我们对CNN和图表的深入,我们发现了CNN的关键:局部连接、共享权重和多层使用。这些对解决图域问题也具有重要意义,因为:①图是最典型的局部连通结构;②与传统的谱图理论相比,共享权值降低了计算量;③多层结构是处理层次化模式的关键,它能捕获各种尺寸的特征。因此,很容易就能发现 CNN 对图形的推广。但是,如1所示,局部化的卷积滤波器和集合算子很难定义,这阻碍了CNN从欧几里得域向非欧几里得域的转化。

另一个动机来自图嵌入,它学习在低维向量中表示图节点、边或子图。在图分析领域,传统的机器学习方法通常依赖于手工设计的特征,且受其灵活性和高成本的限制。 DeepWalk 是第一个基于表示学习的图嵌入方法,它遵循表示学习的思想和词嵌入的成功,在生成的随机游动上应用了 SkipGram 模型。类似的方法如node2vec、LINE和 TADW 也取得了突破。然而,这些方法遭受两个严重的缺点。首先,编码器中的节点之间没有共享参数,这导致计算效率低下,因为这意味着参数数量随节点数量线性增长。直接嵌入法由于缺乏推广能力,不能处理动态图,也不能推广到新图。
基于CNN和图形嵌入,图形神经网络(GNN)被提出用于对图形结构中的信息进行集合。因此,它们可以对由元素组成的输入和/或输出及其依赖性进行建模,并且图神经网络可以用RNN核同时对图上的扩散过程进行建模。
在接下来的部分,我们解释了图神经网络为什么值得研究的根本原因。第一,像 CNN 和 RNN 这样的标准神经网络不能正确处理图形输入,因为它们按特定的顺序堆叠节点的特征。然而,图中并没有一个自然的节点顺序。为了完整地表示一个图,我们应该像 CNN 和 RNN 一样遍历所有可能的顺序作为模型的输入,这在计算时是非常多余的。为了解决这个问题,GNN 分别在每个节点上传播,忽略节点的输入顺序。换句话说,GNNs 的输出对于节点的输入顺序是不变的。第二,图中的边表示两个节点之间的依赖信息。在标准神经网络中,依赖信息仅仅作为节点的特征。然而,GNN 可以在图形结构的引导下进行传播,而不是将其作为特性的一部分。GNN 通常通过邻域状态的加权和来更新节点的隐藏状态。第三,推理是高级人工智能的一个重要研究课题,人脑中的推理过程几乎都是基于从日常经验中提取的图。标准的神经网络已经显示出通过学习数据的分布来生成合成图像和文档的能力,而他们仍然不能从大量的实验数据中学习推理图。然而,GNN 探索从像场景图片和故事文档这样的非结构性数据生成图形,这可以成为进一步高级 AI 的强大神经模型。最近已经证明,一个未经训练的 GNN 与一个简单的体系结构也表现良好。
关于图神经网络有几个全面的综述。[18] 给出了早期图神经网络方法的正式定义。[19] 证明了图神经网络的逼近性质和计算能力。[20] 提出了一个统一的框架Monet,将CNN架构推广到非欧几里得域(图和流形),该框架可以推广图[2]、[21]上的几种光谱方法以及流形[22]、[23]上的一些模型。[24] 提供了几何深度学习的全面回顾,其中介绍了它的问题、困难、解决方案、应用和未来的方向。[20] 和 [24] 的研究重点是将卷积推广到图或流形上,但本文只关注图上定义的问题,并研究了图神经网络中的其它机制,如门机制、注意机制和跳过连接。[25] 提出了消息传递神经网络 (MPNN),它可以推广几种图神经网络和图卷积网络的方法。给出了消息传递神经网络的定义,并演示了其在量子化学中的应用。[26]提出了非局部神经网络(NLNN),它统一了几种“自我关注”方式。然而,模型并没有在原始文件的图表上明确定义。以具体的应用领域为重点,[25] 和 [26] 只举例说明如何使用框架推广其他模型,而不提供对其他图神经网络模型的评审。[27] 提出了图网络 (GN) 框架。该框架具有很强的泛化其他模型的能力,其关系归纳偏差促进了组合泛化,被认为是 AI 的重中之重。然而,[27] 是部分立场文件,部分评审和部分统一,它只是一个粗略的分类申请。在本文中,我们提供了一个全面评审不同图形神经网络的模型以及一个系统的分类方法的应用。
总之,本文对具有以下贡献的图神经网络进行了广泛的综述。一、我们提供了一个详细的评审现有图形神经网络的模型。我们介绍了原始模型、它的变体和几个通用框架。我们研究了这方面的各种模型,并提供了一个统一的表示,以在不同的模型中呈现不同的传播步骤。通过识别相应的聚合器和更新器,可以很容易地使用我们的表示区分不同的模型。二、我们对应用程序进行了系统分类,并将应用程序分为结构场景、非结构场景和其他场景。我们介绍了几种主要的应用程序及其相应的方法在不同的情况。三、我们提出了四个有待进一步研究的问题。图神经网络存在过度光滑和尺度问题。目前还没有有效的方法来处理动态图以及建模非结构感知数据。我们对每一个问题都进行了透彻的分析,并提出了今后的研究方向。
本次调查的其余部分整理如下。第2节,我们介绍了图神经网络家族中的各种模型。我们首先介绍原始框架及其局限性。然后我们展示它的变体,试图释放这些限制。最后,我们介绍了最近提出的几个通用框架。在第3节中,我们将介绍图神经网络在结构场景、非结构场景和其他场景中的几个主要应用。在第4节中,我们提出了图神经网络的四个开放问题以及未来的研究方向。最后,我们在第5节结束了调查。
2. Models
在第 2.1 节中,我们描述了[18] 提出的原始图神经网络。我们还列出了原始 GNN 在表达能力和训练效率上的局限性。在 2.2 节中,我们介绍了图神经网络的几种变体,旨在释放其局限性。这些变量对不同类型的图进行操作,使用不同的传播函数和高级训练方法。在第 2.3 节中,我们提出了三个通用框架,可以推广和扩展几条工作线。具体而言,消息传递神经网络 (MPNN) [25] 将各种图神经网络和图卷积网络方法统一起来;非局部神经网络 (NLNN) [26] 将几种自我关注式方法统一起来。图网络 (GN) [27] 可以推广本文提到的几乎每个图神经网络变量。
在进一步进入不同的部分之前,我们给出了将在整个论文中使用的符号。符号的详细描述见表 1。

2.1 Graph Neural Networks
图神经网络 (GNN) 的概念是在 [18] 首次提出的,它扩展了现有的用于处理图域中的数据的神经网络。在一个图中,每个节点由它的特征和相关的节点自然地定义。GNN 的目标是学习一个状态嵌入 ![]() ,其中包含每个节点的邻域信息。状态嵌入
,其中包含每个节点的邻域信息。状态嵌入 ![]() 是节点
是节点  的
的  维向量,可用于产生节点标签等输出
维向量,可用于产生节点标签等输出 ![]() 。设
。设  为参数函数,称为局部转移函数,在所有节点间共享,并根据输入邻域更新节点状态。
为参数函数,称为局部转移函数,在所有节点间共享,并根据输入邻域更新节点状态。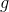 是局部输出函数,它描述了输出是如何产生的。然后,
是局部输出函数,它描述了输出是如何产生的。然后,![]() 和
和 ![]() 定义如下:
定义如下:
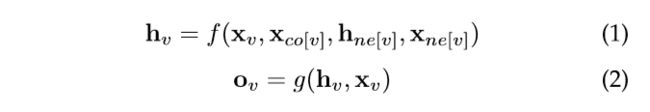
其中 ![]() 分别是 的特征、其边的特征、状态以及 附近节点的特征。
分别是 的特征、其边的特征、状态以及 附近节点的特征。
让 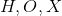 和
和 ![]() 分别是通过堆叠所有状态、所有输出、所有特征和所有节点特征构建的向量。然后我们有一个紧凑的形式:
分别是通过堆叠所有状态、所有输出、所有特征和所有节点特征构建的向量。然后我们有一个紧凑的形式:
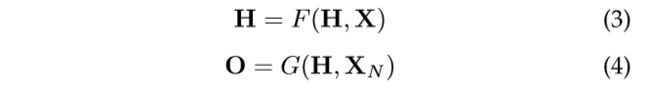
其中  是全局转换函数,
是全局转换函数, 是全局输出函数,是图中所有节点
是全局输出函数,是图中所有节点 ![]() 函数的叠加形式。H的值是等式3的固定点,并以f为收缩图的假设进行了独特的定义。
函数的叠加形式。H的值是等式3的固定点,并以f为收缩图的假设进行了独特的定义。 的值是由等式(3)确定的,并且假设 是收缩图, 的值被唯一定义。
的值是由等式(3)确定的,并且假设 是收缩图, 的值被唯一定义。
在 Banach 不动点定理 [28] 的建议下,GNN 使用以下经典迭代方案计算状态:
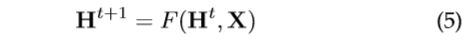
式中,![]() 表示 的
表示 的  次迭代。对于任何初始值
次迭代。对于任何初始值![]() ,动态方程(5)以指数形式快速收敛到方程(3)的解。注意, 和 中描述的计算可以解释为前馈神经网络。
,动态方程(5)以指数形式快速收敛到方程(3)的解。注意, 和 中描述的计算可以解释为前馈神经网络。
当我们有GNN的框架时,下一个问题是如何学习 和 的参数。利用目标信息(特定节点 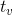 )进行指导,损失可以写如下:
)进行指导,损失可以写如下:
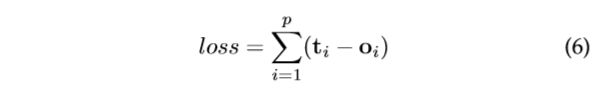
其中  是受指导节点的数量。学习算法基于梯度下降策略,由以下步骤组成:①状态
是受指导节点的数量。学习算法基于梯度下降策略,由以下步骤组成:①状态 ![]() 由式(1)迭代更新到时间 ,它们接近式(3)的定点解:
由式(1)迭代更新到时间 ,它们接近式(3)的定点解:![]() ;②权重
;②权重 的梯度由损失计算得出;③根据上一步计算的梯度更新权重。
的梯度由损失计算得出;③根据上一步计算的梯度更新权重。
Limitations 虽然实验结果表明,GNN是一种强大的结构数据建模体系结构,但原始GNN仍然存在一些局限性。首先,对于固定点迭代更新节点的隐藏状态是低效的。如果放宽固定点的假设,我们可以设计一个多层GNN,以得到节点及其邻域的稳定表示。其次,GNN在迭代中使用相同的参数,而大多数流行的神经网络在不同的层中使用不同的参数,这是一种分层特征提取方法。此外,节点隐藏状态的更新是一个顺序过程,可以从RNN内核(如GRU和LSTM)中获益。第三,边上也存在一些信息性特征,这些特征在原始GNN中无法有效建模。例如,知识图中的边具有关系类型,通过不同边的消息传播应根据它们的类型而有所不同。此外,如何了解边的隐藏状态也是一个重要的问题。最后,如果我们把重点放在节点的表示上而不是图上,就不适合使用固定点,因为固定点上的表示分布在数值上是平滑的,区分每个节点的信息量也比较少。
2.2 Variants of Graph Neural Networks
在本节中,我们介绍了图神经网络的几种变体。第2.2.1节重点介绍在不同图类型上操作的变体。这些变体扩展了原始模型的表示能力。第2.2.2节列出了传播步骤的几种模式(卷积、门机制、注意机制和跳跃连接),这些模型可以学习更高质量的表示。第2.2.3节介绍了使用高级培训方法的变体,这些方法可提高培训效率。图2概述了图神经网络的不同变体。

2.2.1 Graph Types
在原GNN[18]中,输入图由带标签信息的节点和无向边组成,这是最简单的图格式。然而,世界上有许多图形变体。在本小节中,我们将介绍一些设计用于对不同类型的图进行建模的方法。
Directed Graphs 图的第一个变量是有向图。无向边可以看作是两个有向边,这表明两个节点之间存在一种关系。然而,有向边比无向边能带来更多的信息。例如,在一个知识图中,边从头部实体开始到尾部实体结束,头部实体是尾部实体的父类,这意味着我们应该区别对待父类和子类的信息传播过程。ADGPM[29]使用了两种权重矩阵, 和
和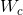 ,以合并更精确的结构信息。传播规则如下:
,以合并更精确的结构信息。传播规则如下:
![]()
其中,![]() 分别是父代和子代的标准化邻接矩阵。
分别是父代和子代的标准化邻接矩阵。
Heterogeneous Graphs 图的第二个变种是异构图,其中有几种节点。处理异构图的最简单方法是将每个节点的类型转换为一个与原始特征连接的热特征向量。此外,GraphInception[30] 将 metapath 的概念引入到异构图的传播中。使用metapath,我们可以根据相邻节点的类型和距离对其进行组。对于每个相邻组,GraphInception 将其视为同构图中的一个子图进行传播,并将来自不同同构图的传播结果连接起来以进行集体的节点表示。
Graph with Edge Information 在图形的最终变体中,每个边还具有诸如边的权重或类型等信息。处理这种图有两种方法:首先,我们可以将图转换为二分图,其中原始边也成为节点,并且将一个原始边拆分为两个新边,这意味着边节点和开始/结束节点之间有两个新边。G2S[31]的编码器对邻域使用以下聚合函数:
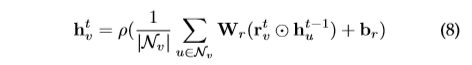
其中,![]() 和
和 ![]() 是不同类型边(关系)的传播参数。其次,我们可以调整不同的权重矩阵,使其在不同的边上传播。当关系数(不同类型边数量)很大时,r-GCN[32] 引入两种正则化方法来减少关系建模的参数:基对角分解和块对角分解,通过基分解,每个
是不同类型边(关系)的传播参数。其次,我们可以调整不同的权重矩阵,使其在不同的边上传播。当关系数(不同类型边数量)很大时,r-GCN[32] 引入两种正则化方法来减少关系建模的参数:基对角分解和块对角分解,通过基分解,每个 ![]() 定义如下:
定义如下:
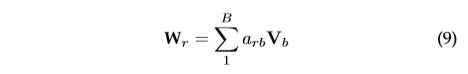
也就是说,作为基变换 ![]() 与系数
与系数 ![]() 的线性组合,只有系数依赖于
的线性组合,只有系数依赖于 。在块对角分解中,r-GCN 通过对一组低维矩阵的直接求和来定义每个
。在块对角分解中,r-GCN 通过对一组低维矩阵的直接求和来定义每个![]() ,这比第一个矩阵需要更多的参数。
,这比第一个矩阵需要更多的参数。
2.2.2 Propagation Types
传播步骤和输出步骤在模型中对于获得节点(或边)的隐藏状态至关重要。如下所列,在原始图神经网络模型的传播步骤中有几个主要修改,而研究人员通常在输出步骤中遵循简单的前馈神经网络设置。可以在表2中找到GNN不同变体的比较。变体使用不同的聚集器从每个节点的邻域收集信息,并指定更新器来更新节点的隐藏状态。

Convolution.
人们对将卷积推广到图域越来越感兴趣。这方面的进展通常分为Spectral Methods 和Non-Spectral Methods。谱方法使用图的谱表示。[35]提出了谱网络。通过计算拉普拉斯图的特征分解,在傅立叶域中对卷积运算进行了定义。该运算可以定义为信号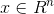 (每个节点的标量)与参数化的滤波器
(每个节点的标量)与参数化的滤波器![]() (
(![]() )的乘积:
)的乘积:
![]()
其中,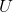 为归一化的拉普拉斯图
为归一化的拉普拉斯图 ![]() 的特征向量矩阵 (
的特征向量矩阵 ( 是Degree Matrix,
是Degree Matrix, 是图的邻接矩阵),其特征值的对角矩阵为
是图的邻接矩阵),其特征值的对角矩阵为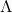 。
。
该运算会导致潜在的密集计算和非空间局部化滤波器。[36]试图通过引入具有平滑系数的参数化来使谱滤波器进行空间局部化。[37]提出,![]() 可以用切比雪夫多项式
可以用切比雪夫多项式![]() 的截断展开近似,直到
的截断展开近似,直到![]() 。因此,运算是:
。因此,运算是:
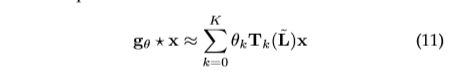
其中,![]() 。
。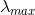 表示
表示  的最大特征值。
的最大特征值。![]() 现在是切比雪夫系数的向量。切比雪夫多项式被定义为
现在是切比雪夫系数的向量。切比雪夫多项式被定义为![]() ,其中
,其中![]() 。可以看到该运算是
。可以看到该运算是 -局部化的,因为它是拉普拉斯算子中的阶多项式。[38] 使用这种-局域卷积来定义卷积神经网络,它可以消除计算拉普拉斯特征向量的需要。
-局部化的,因为它是拉普拉斯算子中的阶多项式。[38] 使用这种-局域卷积来定义卷积神经网络,它可以消除计算拉普拉斯特征向量的需要。
[2]将逐层卷积运算限制在![]() ,以缓解节点度分布非常宽的图的局部邻域结构过度设置的问题。它进一步近似
,以缓解节点度分布非常宽的图的局部邻域结构过度设置的问题。它进一步近似![]() ,公式简化为:
,公式简化为:
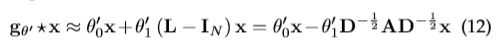
其中有两个自由参数![]() 和
和 ![]() 。用
。用![]() 约束参数数量后,我们可以获得以下表达式:
约束参数数量后,我们可以获得以下表达式:
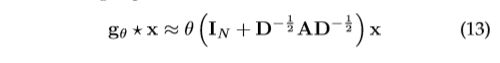
注意,叠加此运算可能会导致数值不稳定和梯度爆炸/消失,[2]引入重正化技巧:![]() ,其中
,其中 ![]() 和∙
和∙![]() 。最后,[2]将特征映射的定义推广到具有输入通道
。最后,[2]将特征映射的定义推广到具有输入通道  和滤波器 的信号
和滤波器 的信号
![]() ,如下所示:
,如下所示:
![]()
其中![]() 是滤波器参数矩阵,
是滤波器参数矩阵,![]() 是卷积信号矩阵。
是卷积信号矩阵。
[39]提出了一种基于高斯过程的贝叶斯方法来解决图的半监督学习问题。它展示了模型和光谱滤波方法之间的相似之处,这可以从另一个角度给我们一些启示。
然而,在上述所有谱方法中,所学习的滤波器依赖于拉普拉斯特征基,拉普拉斯特征基依赖于图结构,也就是说,在特定结构上训练的模型不能直接应用于具有不同结构的图。
非谱方法直接在图上定义卷积,在空间上邻域上操作。非谱方法的主要挑战是定义具有不同大小邻域的卷积运算,并保持CNNs的局部不变性。
[33]对不同度的节点使用不同的权重矩阵,其中![]() 是 层上具有
是 层上具有![]() 度的节点的权重矩阵。该方法的主要缺点是它不能应用于具有更多节点度的大规模图。
度的节点的权重矩阵。该方法的主要缺点是它不能应用于具有更多节点度的大规模图。

[21]提出了扩散卷积神经网络。转移矩阵用于定义DCNN中节点的邻域。对于节点分类,它有
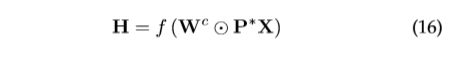
其中 是输入特征的
是输入特征的![]() 张量(
张量( 是节点数,是特征数)。
是节点数,是特征数)。![]() 是一个
是一个![]() 的张量,它包含矩阵
的张量,它包含矩阵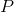 的幂级数
的幂级数![]() , 是图邻接矩阵 的度归一化转换矩阵。每个实体都转换为扩散卷积表示,它是由图在 特征上扩散的 跳定义的
, 是图邻接矩阵 的度归一化转换矩阵。每个实体都转换为扩散卷积表示,它是由图在 特征上扩散的 跳定义的![]() 矩阵。然后用一个
矩阵。然后用一个![]() 权矩阵和一个非线性激活函数 来定义,最后
权矩阵和一个非线性激活函数 来定义,最后![]() 表示图中每个节点的扩散表示。
表示图中每个节点的扩散表示。
至于图的分类,DCNN只是取节点表示的平均值,这里![]() 是
是![]() 维向量。DCNN还可以应用于边分类任务,这需要将边转换为节点并增加邻接矩阵。
维向量。DCNN还可以应用于边分类任务,这需要将边转换为节点并增加邻接矩阵。
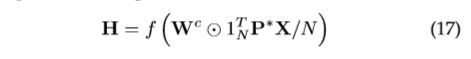
[40]为每个节点提取并规一化恰好K个节点的邻域。然后,归一化邻域作为卷积运算的接收域。[20]提出了一个非欧几里得域上的空间域模型(MoNet),它可以概括前面的几种技术。流形上的GCNN[22] 和 ACNN[23] 或图上的GCN[2] 和DCNN[21] 可以作为 MoNet 的特殊实例。
[1]提出了 GraphSAGE,一个通用归纳框架。该框架通过从节点的本地邻域采样和聚集特征来生成嵌入。然而,[1]没有利用等式18中的全部邻域集,而是通过均匀采样来利用固定大小的邻域集。
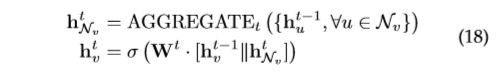
[1]提出了三个聚合函数:
①Mean aggregator。它可以被视为来自转换GCN框架[2] 的卷积运算的近似值,因此GCN变体的归纳版本可以通过等式(19)导出。Mean aggregator不同于其他聚合器,因为它不执行等式(18)中连接 ![]() 和
和 ![]() 的连接操作。它可以被视为“skip connection”[41] 的一种形式,并且可以实现更好的性能。
的连接操作。它可以被视为“skip connection”[41] 的一种形式,并且可以实现更好的性能。
![]()
②LSTM聚合器。[1]还使用了一个基于LSTM的聚合器,它具有更大的表达能力。然而,LSTMs以顺序方式处理输入,因此它们不是排列不变的。[1]通过置换节点的邻域来调整LSTMs以在无序集上操作。
③Pooling aggregator。在池化聚合器中,每个邻居的隐藏状态通过完全连接层提供,然后对节点的邻域集进行最大池化运算。注意,在这里可以使用任何对称函数来代替max pooling运算。
![]()
最近,结构感知卷积和结构感知卷积神经网络被提出[42]。单变量函数用作滤波器,它们可以处理欧几里德和非欧几里德结构化数据。
Gate
有几项工作试图在传播步骤中使用GRU[43] 或LSTM[44] 这样的门机制,以减少以前GNN模型中的限制,并改善信息在图结构中的长期传播。[45]提出了门控图神经网络(GGNN),它在传播步骤中使用门控循环单元(GRU),在固定数量的步骤 中展开循环,并使用随时间的反向传播来计算梯度。具体来说,传播模型的基本循环为
中展开循环,并使用随时间的反向传播来计算梯度。具体来说,传播模型的基本循环为

节点 首先聚集来自其邻域的消息,其中
首先聚集来自其邻域的消息,其中![]() 是图邻接矩阵 的子矩阵,并且表示节点与其邻域的连接。类似GRU的更新函数包含来自其他节点和上一个时间步骤的信息,以更新每个节点的隐藏状态。
是图邻接矩阵 的子矩阵,并且表示节点与其邻域的连接。类似GRU的更新函数包含来自其他节点和上一个时间步骤的信息,以更新每个节点的隐藏状态。 收集节点 的邻域信息,
收集节点 的邻域信息, 和 是更新门和重置门。LSTMs在基于树或图的传播过程中也使用类似于GRU的方式。
和 是更新门和重置门。LSTMs在基于树或图的传播过程中也使用类似于GRU的方式。
[46]提出了对基本LSTM体系结构的两个扩展:Child-Sum Tree-LSTM 和 N-ary LSTM。和标准LSTM单元一样,每个Tree-LSTM单元(用索引)包含输入和输出门![]() 和
和![]() 、存储单元
、存储单元![]() 和隐藏状态
和隐藏状态![]() 。Tree-LSTM单元不是一个遗忘门,而是为每个孩子
。Tree-LSTM单元不是一个遗忘门,而是为每个孩子 包含一个遗忘门
包含一个遗忘门![]() ,允许该单元有选择地合并来自每个子级的信息。Child-Sum Tree-LSTM 转换方程如下:
,允许该单元有选择地合并来自每个子级的信息。Child-Sum Tree-LSTM 转换方程如下:
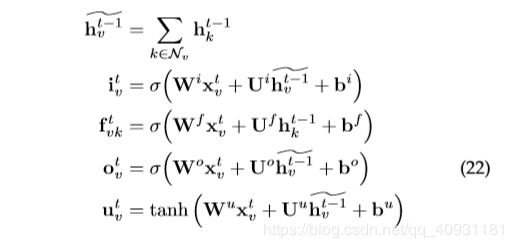
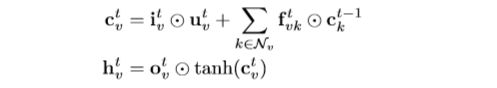
![]() 是标准 LSTM 设置中时间 的输入向量。
是标准 LSTM 设置中时间 的输入向量。
如果一棵树的分支因子最多为,并且一个节点的所有子节点都是有序的,也就是说,它们可以从1索引到,那么就可以使用N-ary Tree-LSTM。对于节点,![]() 和
和![]() 分别表示其第个孩子在时刻的隐藏状态和存储单元。转换方程如下:
分别表示其第个孩子在时刻的隐藏状态和存储单元。转换方程如下:

为每个孩子 引入独立的参数矩阵,使得模型比 Child-Sum Tree-LSTM 能够学习更多有关单元子级状态的细粒度表示。
这两种类型的Tree-LSTMs 可以很容易地适应图。[47] 中的结构化 LSTM 是 N-ary Tree-LSTM 在图中应用的一个例子。但是,它是一个简化版本,因为图中的每个节点最多具有 2 个传入边(来自其父节点和同级节点的前一个)。[34] 在关系抽取任务的基础上提出了图 LSTM 的另一种变体。图和树的主要区别在于图的边有它们的标签。[34] 利用不同的权重矩阵表示不同的标签:
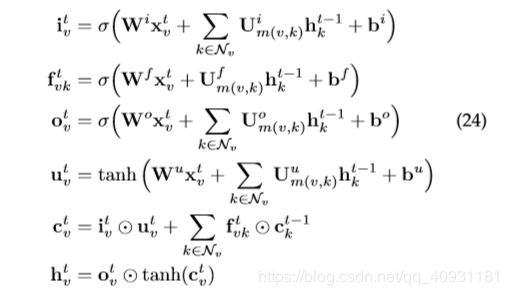
其中![]() 代表节点 和 之间的边标签。
代表节点 和 之间的边标签。
[48]提出了改进文本编码的Sentence LSTM。它将文本转换为图形,并利用图LSTM学习表示。S-LSTM 在许多 NLP 问题中表现出强大的表示能力。[49] 提出了一种基于图 LSTM 网络来解决语义对象解析任务。该方法采用置信区间自适应地选择初始节点,确定节点更新顺序。它遵循将现有的 LSTM 推广到图结构数据的相同思想,但是具有特定的更新序列,而我们上面提到的方法对节点顺序不可知。
Attention
注意机制已成功地应用于许多基于序列的任务中,如机器翻译 [50]-[52]、机器阅读 [53] 等。[54] 提出了一种图注意网络 (GAT),它将注意机制融入到传播步骤中。它通过关注相邻节点,遵循自我关注策略计算每个节点的隐藏状态。[54] 提出了单图注意层,并通过堆叠该层构建任意图注意网络。该层计算注意机制中节点对 的系数:
的系数:
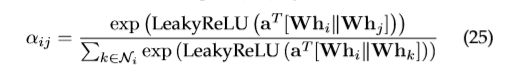
其中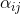 是节点
是节点  对
对  的注意力系数,
的注意力系数, 表示图中节点 的邻域。对于一层的节点输入集是
表示图中节点 的邻域。对于一层的节点输入集是![]() ,其中 是节点数, 是每个节点的特征数,该层产生一组新的节点特征(可能具有不同的基数
,其中 是节点数, 是每个节点的特征数,该层产生一组新的节点特征(可能具有不同的基数![]() ),
),![]() 作为其输入。
作为其输入。![]() 是应用于每个节点的共享线性变换的权重矩阵,
是应用于每个节点的共享线性变换的权重矩阵,![]() 是单层前馈神经网络的权向量。它由一个 SoftMax 函数进行归一化,并应用非线性LeakyReLU(负输入斜率
是单层前馈神经网络的权向量。它由一个 SoftMax 函数进行归一化,并应用非线性LeakyReLU(负输入斜率![]() ),
),
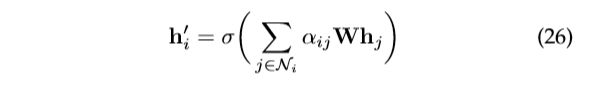
此外,该层利用与[52]类似的multi-head attention 来稳定学习过程。它应用 K 独立注意机制来计算隐藏状态,然后连接它们的特征(或计算平均值),从而产生以下两种输出表示:

其中 ![]() 是由第 k 个注意机制计算的标准化注意系数。
是由第 k 个注意机制计算的标准化注意系数。
[54]中的注意力结构具有以下几个特点:(1)节点邻域对的计算是可并行的,因此操作是有效的;(2)通过对邻域指定任意权重,可以应用于不同程度的图节点;(3)很容易应用于归纳学习问题。
Skip connection
许多应用展开或堆叠图形神经网络层,目的是随着更多的层(即k层)使每个节点聚集来自k-hops 之外的邻域的更多信息而获得更好的结果。然而,在许多实验中已经观察到,更深的模型不能提高性能,更深的模型甚至可以表现得更差[2]。这主要是因为更多的层也可以传播来自指数级增加的扩展邻域成员的噪声信息。
解决这个问题的一个简单方法,即残差网络[55],可以从计算机视觉社区中找到。但是,即使有残差连接,具有更多层的GCN在许多数据集上的性能也不如2层 GCN[2]。[56]提出了一条 Higehway GCN,该,该模型使用类似于公路网络的分层门[57]。一个层的输出与它的输入和 gate weight 相加:
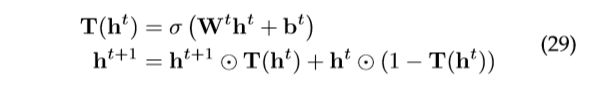
通过增加 Highway gate,性能在4层达到峰值,具体问题在[56]中讨论。[58]研究邻域聚合方案的性质和由此产生的限制。提出了一种学习自适应、结构感知表示的跳跃知识网络。跳跃知识网络从最后一层的每个节点的所有中间表示(即“跳跃”到最后一层)中进行选择,使模型根据需要适应每个节点的有效邻域大小。[58]在实验中使用了三种方法,即concatenation、max-pooling和LSTM-attention来聚合信息。跳跃知识网络在社会、生物信息学和引文网络的实验中表现良好。它还可以与图形卷积网络、图形存储和图形注意网络等模型相结合,以提高它们的性能。
2.2.3 Training Methods
原有的图卷积神经网络在训练和优化方法上存在一些缺陷。具体来说,GCN需要完整的拉普拉斯图,这对于大型图来说是计算消耗。此外,一个节点在L层的嵌入是通过在L-1层的所有相邻节点的嵌入来递归计算的。因此,单个节点的接受域相对于层数呈指数增长,因此计算单个节点的梯度花费很大。最后,GCN被单独训练为固定图,缺乏归纳学习的能力。
GraphSAGE[1]是对原始GCN的综合改进。为了解决上面提到的问题,GraphSAGE用可学习的聚合函数代替了全图拉普拉斯函数,这是执行消息传递和推广到未知节点的关键。如等式18所示,它们首先聚合邻域嵌入,与目标节点的嵌入连接,然后传播到下一层。通过学习聚合和传播函数,GraphSAGE可以为看不见的节点生成嵌入。此外,GraphSAGE使用邻域采样来缓解接受域扩展。
FastGCN[59]进一步改进了采样算法。FastGCN不是对每个节点的相邻节点进行采样,而是直接对每个层的接收字段进行采样。FastGCN采用重要性抽样,重要性系数计算如下:
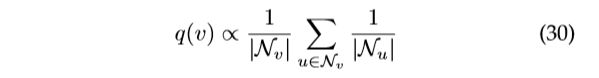
与上述固定采样方法相比,[60]引入了一个参数化和可训练的采样器,以在前一层进行分层采样。此外,这种自适应采样器可以同时确定最佳采样重要性和减少方差。[61]利用节点的历史激活作为控制变量,提出了一种基于控制变量的GCN随机逼近算法。[61] 这种方法限制了1-hop 邻域外的接收域,但使用历史隐藏状态作为一个可承受的近似值。[62]重点关注GCN的局限性,其中包括GCN需要许多额外的标记数据来进行验证,并且还受到卷积过滤器的本地化性质的影响。为了解决这些局限性,作者提出了 Co-Training GCN和 Self-Training GCN两种方法来扩大训练数据集。前一种方法确定训练数据的最近邻域,而后一种方法则采用类似于增强的方法。
2.3 General Frameworks
除了图神经网络的不同变体之外,还提出了几个通用框架,旨在将不同的模型集成到一个框架中。[25]提出了消息传递神经网络(MPNN),它结合了各种图形神经网络和图形卷积网络方法。[26]提出了非局部神经网络(NLNN)。它包括几种“self-attention”式的方法,[52],[54],[63]。[27]提出了图网络,该网络结合了MPNN和NLNN方法以及许多其他变体,如交互网络[4]、[64],Neural Physics Engine[65],CommNet[66],structure2vec[7]、[67],GGNN[45],Relation Network[68]、[69],Deep Sets[70]和 Point Net[71]。
2.3.1 Message Passing Neural Networks
[25]提出了一个监督图学习的通用框架,称为消息传递神经网络(MPNNS)。MPNN框架抽象了几种最流行的图结构数据模型之间的共性,例如谱方法[35][2],图卷积[38]和非谱方法[33]、门控图神经网络[45]、交互网络[4]、分子图卷积[72]、深张量神经网络[73]等。该模型分为两个阶段:消息传递阶段和读出阶段。消息传递阶段(即传播步骤)运行 个时间步骤,并根据消息函数 ![]() 和顶点更新函数
和顶点更新函数![]() 进行定义。利用消息函数
进行定义。利用消息函数 ![]() ,隐藏状态
,隐藏状态 ![]() 的更新函数如下:
的更新函数如下:

其中,![]() 表示从节点 到 的边的特征。消息读出阶段使用读出函数
表示从节点 到 的边的特征。消息读出阶段使用读出函数  计算全图的特征向量,
计算全图的特征向量,
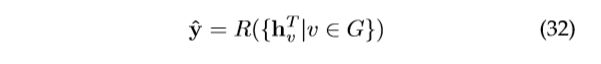
其中 表示总时间步数。消息函数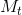 、顶点更新函数
、顶点更新函数![]() 和读取函数 可以有不同的设置。因此,MPNN框架可以通过不同的功能设置归纳出几个不同的模型。这里我们给出了一个推广GGNN的例子,其他模型的功能设置可以在[25]中找到。GGNN的函数设置为:
和读取函数 可以有不同的设置。因此,MPNN框架可以通过不同的功能设置归纳出几个不同的模型。这里我们给出了一个推广GGNN的例子,其他模型的功能设置可以在[25]中找到。GGNN的函数设置为:
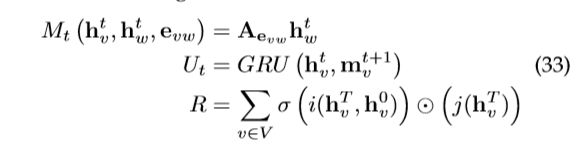
其中,![]() 是邻接矩阵,每个边标签
是邻接矩阵,每个边标签 对应一个。GRU是在[43]中引入的门循环单元。 和 是函数 中的神经网络。
对应一个。GRU是在[43]中引入的门循环单元。 和 是函数 中的神经网络。
2.3.2 Non-local Netural Networks
[26]提出了非局部神经网络(NLNN)来捕捉深度神经网络的长期依赖性。非局部运算是计算机视觉中经典非局部平均运算[74]的推广。非局部运算将某一位置的响应计算为所有位置特征的加权和。这组位置可以在空间、时间或时空中。因此,神经网络可以被视为不同“self-attention”风格方法的统一,[52],[54],[63]。我们将首先介绍非局部运算的一般定义,然后介绍一些具体的实例。
在非局部平均运算[74]之后,一般的非局部运算定义为:

其中 是输出位置的索引, 是枚举所有可能位置的索引。![]() 计算代表 和 之间关系的标量。
计算代表 和 之间关系的标量。![]() 表示输入
表示输入![]() 的转换,系数
的转换,系数![]() 用于归一化结果。
用于归一化结果。
有几个实例具有不同的 和 设置。为了简单起见,[26]使用线性变换作为函数 。这意味着 ![]() ,其中
,其中![]() 是一个可学习的权重矩阵。接下来,我们在下面列出函数 的选择。
是一个可学习的权重矩阵。接下来,我们在下面列出函数 的选择。
Gaussian 高斯函数是根据非局部平均值[74]和同侧滤波器[75]的自然选择,![]() 是点积相似度,
是点积相似度,![]() 。
。
Embedded Gaussian 通过计算嵌入空间中的相似性,可以直接扩展高斯函数,这意味着:
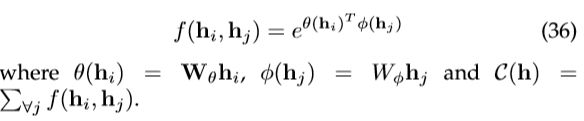
可以发现,在[52]中提出的 self-attention 是嵌入高斯版本的一种特殊情况。对于给定的,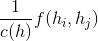 成为沿尺寸 的Softmax计算,因此
成为沿尺寸 的Softmax计算,因此![]() ,这与[52]中的self-attention形式相匹配。
,这与[52]中的self-attention形式相匹配。
Dot product 函数 也可以实现为点积相似度:

Concatenation

[26]将上述非局部运算包装成非局部块,如下所示:
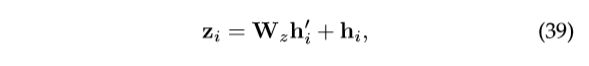
式(34)中给出了![]() ,“
,“![]() ”表示剩余连接[55]。因此,非局部块可以插入到任何预先训练的模型中,这使得块更加适用。
”表示剩余连接[55]。因此,非局部块可以插入到任何预先训练的模型中,这使得块更加适用。
2.3.3 Graph Networks
[27]提出了图网络(GN)框架,该框架概括和扩展了各种图神经网络、MPNN和NLNN方法[18]、[25]、[26]。我们首先介绍[27]中的图定义,然后描述GN块、核心GN计算单元及其计算步骤,最后介绍其基本设计原则。
Graph definition
在[27]中,图被定义为3元组![]() (这里我们用 代替
(这里我们用 代替 表示符号的一致性)。
表示符号的一致性)。 是全局属性,
是全局属性,![]() 是节点集(基数
是节点集(基数![]() ),其中每个
),其中每个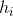 都是节点的属性。
都是节点的属性。![]() 为边集(基数
为边集(基数![]() ),其中每个
),其中每个![]() 为边的属性,
为边的属性,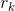 为接收节点的索引,
为接收节点的索引,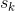 为发送节点的索引。
为发送节点的索引。
GN block
一个GN块包括三个更新函数  ,以及三个聚合函数
,以及三个聚合函数  , 函数必须对其输入的排列保持不变,并且应采用可变参数。
, 函数必须对其输入的排列保持不变,并且应采用可变参数。
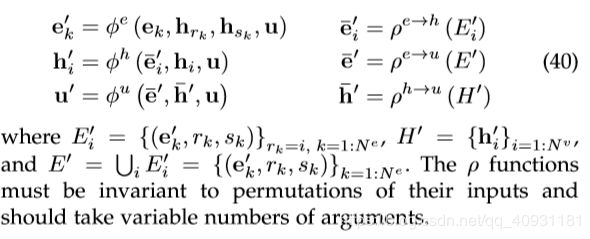
Computation steps
(1)![]() 用参数
用参数![]() 应用于每条边,并返回
应用于每条边,并返回![]() 。每个节点 的每条边输出结果集为
。每个节点 的每条边输出结果集为![]() 。
。![]() 是所有边沿输出的集合.
是所有边沿输出的集合.
(2)![]() 应用于
应用于![]() ,并将投影到顶点 的边的边更新聚合到
,并将投影到顶点 的边的边更新聚合到![]() 中,这将在下一步的节点更新中使用。
中,这将在下一步的节点更新中使用。
(3)![]() 被应用于每个节点 ,以计算更新的节点属性
被应用于每个节点 ,以计算更新的节点属性![]() 。得到的每节点输出的集合是,
。得到的每节点输出的集合是,![]() 。
。
(4)![]() 应用于
应用于![]() ,并将所有边更新聚合到
,并将所有边更新聚合到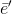 中,然后在下一步的全局更新中使用。
中,然后在下一步的全局更新中使用。
(5)![]() 应用于
应用于![]() ,并将所有节点更新聚合到
,并将所有节点更新聚合到![]() 中,然后在下一步的全局更新中使用。
中,然后在下一步的全局更新中使用。
(6)![]() 在每个图中应用一次,并计算全局属性
在每个图中应用一次,并计算全局属性![]() 的更新。
的更新。
请注意,该命令并未严格执行。例如,可以从全局更新到每个节点,再到每个边。 和 函数不一定是神经网络,尽管在本文中我们只关注神经网络的实现。
和 函数不一定是神经网络,尽管在本文中我们只关注神经网络的实现。
Design Principles
图网络的设计基于三个基本原则:灵活的表示、可配置的块内结构和可组合的多块架构。
· Flexible representations GN框架支持属性的灵活表示以及不同的图结构。全局、节点和边属性可以使用任意表示形式,但实值向量和张量最常见。可以根据任务的具体要求简单地定制GN块的输出。例如,[27]列出了几个聚焦于边缘的[76]、[77]、聚焦于节点的[3]、[4]、[65]、[78]和聚焦于图的[4]、[25]、[69] 的图网络。就图结构而言,在图结构方面,框架可以应用于图结构是显式的结构场景,关系结构应该被推断或假定的非结构场景。
· Configurable within-block structure GN模块内的功能及其输入可以有不同的设置,因此GN框架可以在模块内结构配置中提供灵活性。例如,[77]和[3]使用完整的GN块。它们的 实现使用神经网络, 函数使用元素求和。基于不同的结构和功能设置,各种模型(如MPNN、NLNN和其他变量)可以通过GN框架来表达。更多细节可以在[27]中找到。
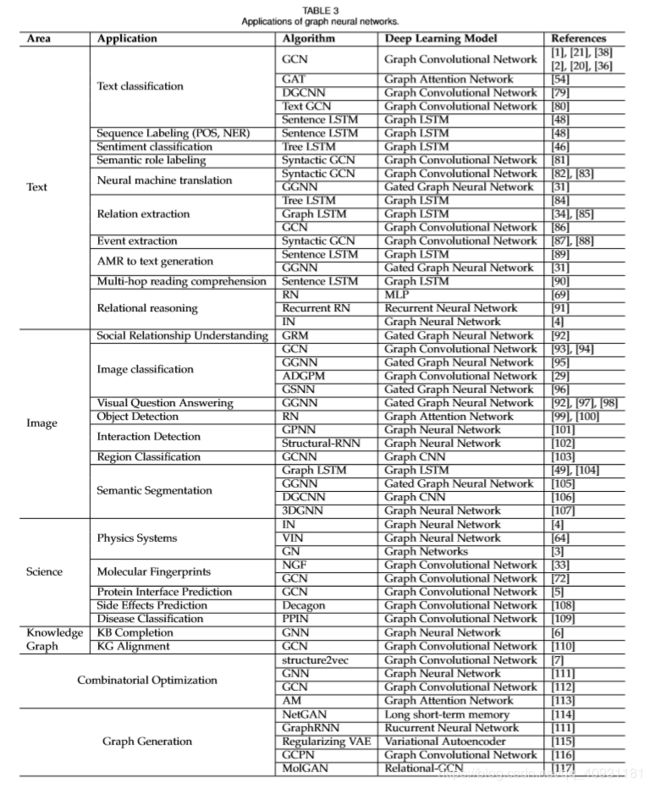
· Composable multi-block architectures GN块可以被组合以构建复杂的体系结构。任意数量的GN块可以用共享或非共享参数按顺序组成。[27]利用GN块来构建 encode-peocess-decode 体系结构和循环的基于GN的体系结构。这些架构如图3所示。构建基于GN的体系结构的其他技术也是有用的,例如跳过连接、LSTM或GRU风格的门控方案等。
3 APPLICATIONS
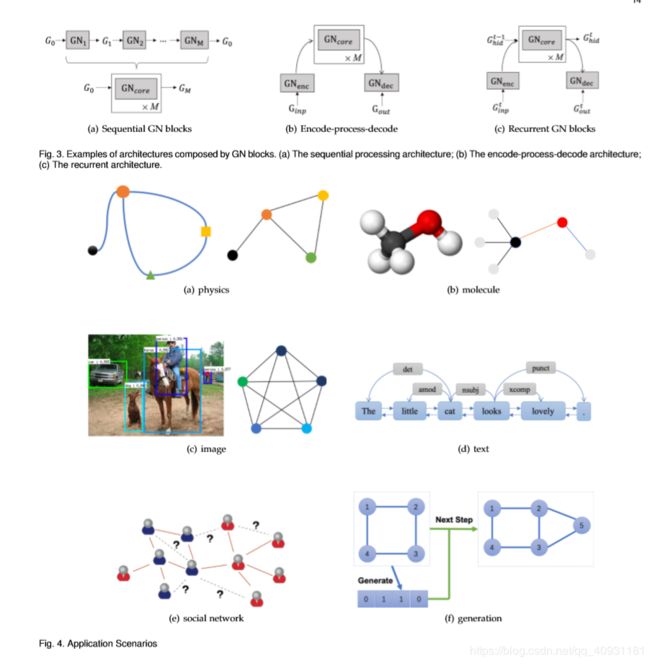
图神经网络已经在许多问题领域中得到了探索,包括有监督的、半监督的、无监督的和强化的学习环境。在本节中,我们简单地将应用程序分为三个场景:(1)数据具有显式关系结构的结构场景,如物理系统、分子结构和知识图;(2)关系结构不显式的非结构场景,包括图像、文本等;(3)其他应用场景,如生成模型和组合优化问题。请注意,我们只列出几个具有代表性的应用程序,而不提供详尽的列表。应用程序摘要见表3。
3.1 Structural Scenarios
在接下来的小节中,我们将介绍GNN在结构场景中的应用,其中数据自然地在图结构中表示。例如,GNN被广泛用于社交网络预测[1],[2],交通预测[56],[118],推荐系统[119],[120]和图表表示[121]。具体来说,我们将讨论如何用对象关系图模拟现实世界的物理系统,如何预测分子的化学性质和蛋白质的生物相互作用性质,以及在知识图中推理知识库外实体的方法。
3.1.1 Physics
模拟现实世界的物理系统是理解人类智能的最基本的方面之一。通过将对象表示为节点,将关系表示为边,我们可以以简单有效的方式对对象、关系和物理进行基于GNN的推理。
[4] 提出了 Interaction Networks 来对各种物理系统进行预测和推断。该模型以对象和关系作为输入,说明它们相互作用的原因,并应用效果和物理动力学来预测新的状态。它们分别对关系中心模型和对象中心模型进行建模,使得跨不同系统进行概括变得更加容易。
Visual Interaction Networks [64]可以从像素做出预测。它从每个对象的两个连续输入帧中学习状态代码。然后,在通过交互网络块添加它们的交互效果之后,状态解码器将状态代码转换成下一步的状态。
[3]提出了一个基于图网络的模型,它可以进行状态预测或归纳推理。推理模型将部分观察到的信息作为输入,并为隐式系统分类构造一个隐藏图。
3.1.2 Chemistry and Biology
Molecular Fingerprints 计算分子指纹,即代表分子的特征向量,是计算机辅助药物设计的核心步骤。传统的分子指纹是手工制作和固定的。通过将GNN应用于分子图,我们可以获得更好的指纹。[33]提出了通过GCN和求和计算子结构特征向量以获得整体表示的神经图定义。聚合函数及节点更新表示为

Protein Interface Prediction [5]专注于蛋白质界面预测的任务,这是一个具有挑战性的问题,在药物发现和设计中有着重要的应用。所提出的基于GCN的方法分别学习配体和受体蛋白残基的表示,并将其合并用于成对分类。GNN也可以用于生物医学工程。通过蛋白质-蛋白质相互作用网络,[109]利用图形卷积和关系网络进行乳腺癌亚型分类。[108]还提出了一个基于GCN的多药副作用预测模型。他们的工作模拟了药物和蛋白质的相互作用网络,并分别处理不同类型的边。
3.1.3 Knowledge graph
[6]利用GNN解决知识库完成过程中的知识库外实体问题。[6]中的OOKB实体直接连接到现有实体,因此可以从现有实体聚合OOKB实体的嵌入。该方法在标准KBC设置和OOKB设置中均达到了令人满意的性能。[110]利用GCN解决跨语言知识图校正问题。该模型将不同语言的实体嵌入到统一的嵌入空间中,并根据嵌入相似性对其进行校正。
3.2 Non-structural Scenarios
在本节中,我们将讨论非结构场景中的应用,例如图像、文本、编程源代码[45]、[122]和多代理系统[63]、[66]、[76]。由于长度限制,我们将只详细介绍前两种情况。大致上,有两种方法可以将图神经网络应用于非结构场景:(1)结合来自其他领域的结构信息来提高性能,例如使用来自知识图的信息来减轻图像任务中的零样本问题;(2)推断或假设场景中的关系结构,然后应用该模型来解决图中定义的问题,例如[48]中将文本建模为图的方法。
3.2.1 Image
Image Classification
图像分类是计算机视觉领域中一项非常基本和重要的任务,备受关注,并拥有许多像 ImageNet [123] 这样著名的数据集。图像分类的最新进展得益于大数据和 GPU 计算的强大能力,这使得我们可以在不从图像中提取结构信息的情况下训练分类器。然而,在图像分类领域中,零样本和少样本学习越来越受欢迎,因为大多数模型在获得足够数据的情况下也能获得相似的性能。有一些利用图神经网络将结构信息纳入图像分类的工作。首先,知识图可以作为额外的信息来指导零样本识别分类 [29],[94]。[94] 构建一个知识图,其中每个节点对应一个对象类别,并以节点的词嵌入作为输入来预测不同类别的分类器。由于卷积结构的深度会产生过平滑效应,[94] 中使用的六层 GCN 在表示时将冲刷掉许多有用的信息。为了解决 GCN 在传播过程中的平滑问题,[29] 在图中采用了较大邻域的单层 GCN,该邻域中同时包含了单跳和多跳节点。并证明了用现有的分类器构建零样本分类器的有效性。除了知识图外,数据集中图像之间的相似性对于少样本的学习也是有益的[93]。[93] 对于少样本分类提出建立一个基于相似性的加权全连通图像网络,并在图中做消息传递。由于大多数知识图对于推理来说是偏大的,[96] 根据目标检测的结果选择相关实体构建子图,并将 GGNN 应用于提取的图进行预测。此外,[95] 建议构造一个新的知识图,其中实体是所有类别。并且,它们定义了三种类型的标签关系:super subordinate 超从属关系、正相关关系和负相关关系,并直接在图中传播标签的置信度。
Visual Reasoning
计算机视觉系统通常需要通过结合空间和语义信息来进行推理,所以为推理任务生成图表是很自然的。一个典型的视觉推理任务是视觉问答,[97]分别构造图像场景图和问题句法图。然后应用 GGNN 对嵌入进行训练,以预测最终答案。尽管对象之间存在空间连接,但 [124] 构建了以问题为条件的关系图。有了知识图,[92]、[98] 能进行更精细的关系探索和更可解释的推理过程。视觉推理的其他应用包括对象检测、交互检测和区域分类。在对象检测中 [99]、[100] ,GNN 用于计算 RoI 特征;在交互检测中 [101]、[102],GNN 是人与对象之间的消息传递工具;在区域分类中 [103] ,GNN 在连接区域和类的图上执行推理。
Semantic Segmentation
语义分割是实现图像理解的关键步骤。这里的任务是为图像中的每个像素分配一个唯一的标签(或类别),这可以被认为是一个密集的分类问题。然而,图像中的区域往往不是网格状的,需要非局部信息,这导致了传统 CNN 的失败。一些工作利用了图形结构化数据来处理它。[49] 提出了 Graph-LSTM,通过建立基于距离的超像素映射形式的图,并应用 LSTM 在全球范围内传播邻域信息,建立长期依赖关系和空间连接模型。后续工作从编码层次信息的角度对其进行了改进 [104]。此外,3D 语义分割(RGBD 语义分割)和点云分类利用了更多的几何信息,因此很难通过 2D CNN 建模。[107]构造了一个 K 近邻 (KNN) 图,并使用一个三维 GNN 作为传播模型。预测模型经过几步展开后,以每个节点的隐藏状态作为输入,预测其语义标签。因为总是有太多的点,[105]通过构建超级点图并为它们生成嵌入来解决大规模3D点云分割。为了分类超节点,[105]利用GGNN和图形卷积。[106]提出通过边来模拟点的相互作用,通过输入其终端节点的坐标来计算边表示向量,然后通过边聚合更新节点嵌入。
3.2.2 Text
图形神经网络可以应用于基于文本的多种任务。它既可以应用于句子级任务(如文本分类),也可以应用于单词级任务(如序列标记)。我们将在下面介绍几个主要的文本应用程序。
Text classification
文本分类是自然语言处理中一个重要的经典问题。经典的GCN模型[1]、[2]、[20]、[21]、[36]、[38]和GAT模型[54]被应用于解决该问题,但是它们仅使用文档之间的结构信息,并且不使用太多文本信息。[79] 提出了一种基于 graph-CNN 的深度学习模型,首先将文本转换为单词的图形,然后使用 [40] 中的图卷积运算将单词图卷积。[48] 提出了句子 LSTM 来编码文本。它将整个句子看作一个单一的状态,它由单个单词的子状态和一个整体句子级别的状态组成。它对分类任务使用全局语句级表示。这些方法可以将文档或句子看作一个单词节点图,也可以依赖文档引用关系来构造这个图。[80] 以文档和文字为节点构建语料库图(异构图),利用Text GCN 学习文档和文字的嵌入。情绪分类也可以看作是一个文本分类问题,[46] 提出了Tres-LSTM 方法。
Sequence labeling
由于 GNNs 中的每个节点都有自己的隐藏状态,如果将句子中的每个单词都看作一个节点,就可以利用隐藏状态来解决序列标注问题。[48] 使用Sentence LSTM 标记序列。它已经进行了 POS-tagging 和 NER 任务的实验,并获得了最先进的性能。语义角色标注是序列标注的另一项任务。[81] 提出了一个Syntactic GCN 来解决这个问题。Syntactic GCN 是 GCN [2]的一个特殊变体,它作用在有标记边的图上。它集成了edge-wise gates,让模型调节单个依赖边的贡献。利用句法依存树的Syntactic GCNs 作为句子编码器,学习句子中单词的潜在特征表示。[81] 还揭示了 GCNs 和 LSTMs 在任务中功能互补。
Neural machine translation
神经机器翻译任务通常被认为是一个序列到序列的任务。[52]引入了注意机制,取代了最常用的递归或卷积层。事实上,转换器假设语言实体之间有一个完全连通的图形结构。GNN的一个流行应用是将句法或语义信息整合到NMT任务中。[82]在句法感知的NMT任务中使用Syntactic GCN。[83]使用句法GCN整合了关于源句子predicate-argumen 结构的信息(即语义-角色表示),并比较了仅整合句法或语义信息,或者两种信息都整合到任务中的结果。[31]在语法感知的NMT中使用了GGNN。它通过将边转换成额外的节点,将句法依赖图转换成Levi 图的新结构,因此边标签可以表示为嵌入。
Relation extration
提取文本中实体之间的语义关系是一项重要且研究广泛的任务。一些系统将该任务视为两个独立任务的pipeline,命名为实体识别和关系提取。[84]提出了一个使用双向序列和树形结构的LSTM-RNNs的端到端关系提取模型。[86]提出了一种图卷积网络的扩展,它适合于关系提取,并对输入树应用剪枝策略。跨句子的N-ary关系抽取检测跨多个句子的N个实体之间的关系。[34]探索了一个基于图LSTMs的跨句N-ary关系抽取的通用框架。它将输入图分割成两个DAGs,而重要信息可能在分割过程中丢失。[85]提出了一个graph-state LSTM模型。它保持了原始的图形结构,并通过允许更多的并行化来加速计算。
Event extraction
事件抽取是一种重要的信息提取任务,用于识别文本中特定类型事件的实例。[87] 研究了一种基于依赖树的卷积神经网络(即Syntantic GCN)来进行事件检测。[88] 提出了一种Jointly Multiple Events Extraction (JMEE) 框架,通过引入句法快捷键弧来增强信息流,从而联合提取多个事件触发点和参数,并将其应用于基于注意的图卷积网络,建立图信息模型。
Others applications
GNN也可以应用于许多其他应用。有几个工作集中在AMR到文本生成任务上。在这一领域已经提出了基于Sentence-LSTM的方法[89]和基于GGNN的方法[31]。[46]使用Tree LSTM来模拟两个句子的语义相关性。[90]利用Sentence LSTM来解决multi-hop阅读理解问题。另一个重要方向是关系推理,关系网络[69],交互网络[4]和递归关系网络[91],被提出来解决基于文本的关系推理任务。上面引用的作品并不是详尽的列表,我们鼓励我们的读者找到更多他们感兴趣的图神经网络的研究和应用领域。
3.3 Other Scenarios
除了结构性和非结构性场景之外,还有一些其他场景,图神经网络在其中发挥了重要作用。在本小节中,我们将介绍生成图模型和GNNs的组合优化。
3.3.1 Generative Models
现实世界图形的生成模型因其重要的应用而引起了极大的关注,包括对社会交互作用建模、发现新的化学结构和构建知识图形。由于深度学习方法具有强大的学习图形隐式分布的能力,近年来神经图生成模型出现了激增。
NetGAN [114] 是最早建立神经元网络图生成模型的研究之一。它将图的生成问题转化为以特定图中的随机游动为输入的游动生成问题,并利用 GAN 体系结构训练出一个游动生成模型。虽然生成的图保留了原始图的重要拓扑属性,但节点数在生成过程中不能改变,这与原始图相同。GraphRNN[125]通过逐步生成每个节点的邻接向量生成图的邻接矩阵,这可以输出具有不同节点数量的所需网络。
MolGAN[117]不是顺序生成邻接矩阵,而是一次预测离散图结构(邻接矩阵),并利用置换不变鉴别器来解决邻接矩阵中的节点变化问题,它还为基于RL的优化应用了一个奖励网络,以获得所需的化学性质。此外,[115]提出了约束变分自动编码器,以确保生成图的语义有效性。此外,GCPN[116]通过强化学习纳入了特定领域的规则。[126]提出了一种顺序生成边和节点的模型,并利用图神经网络提取当前图的隐藏状态,该隐藏状态用于在序列生成过程中决定下一步的动作。
3.3.2 Combinatorial Optimization
图的组合优化问题是一组 NP 难题,引起了各领域科学家的广泛关注。一些具体的问题,如旅行商问题 (TSP) 和最小生成树 (MST) 已经得到了各种启发式解。近年来,利用深度神经网络解决这类问题已成为一个研究热点,其中一些解决方法因图的结构而进一步利用了图神经网络。
[127]首先提出了一种深度学习的方法来解决TSP问题。他们的方法由两部分组成:用于参数化奖励的Pointer Network [128]和用于培训的政策梯度模块[129]。这项工作已被证明可与传统方法相媲美。然而,Pointer Network 是为像文本这样的顺序数据设计的,而顺序不变编码器更适合这种工作。[130]通过包含图神经网络改进了该方法。他们首先从structure2vec [67]中获得节点嵌入,这是GCN的变体,然后将它们输入到用于决策的Q-learning 模块中。这项工作取得了比以往算法更好的性能,证明了图神经网络的表示能力。[113]提出了一种基于注意力的编解码算法。这种方法可以看作是图注意网络,其readout阶段是基于注意力的解码器,而不是理论上对训练有效的强化学习模块。[111]专注于二次分配问题,即测量两个图的相似性。基于GNN的模型独立地学习每个图的节点嵌入,并使用注意机制匹配它们。这种方法提供了有趣的良好性能,即使在标准relaxation-based技术似乎受到影响的情况下。[112]直接使用GNNs作为分类器,可以对具有成对边的图进行密集预测。模型的其余部分帮助GNNs做不同的选择并有效地训练。
4 OPEN PROBLEMS
尽管GNNs在不同领域取得了巨大成功,但值得注意的是,GNN模型不足以为任何情况下的任何图形提供令人满意的解决方案。在这一部分,我们将陈述一些有待进一步研究的未决问题。
Shallow Structure
由于深层结构具有更多的参数,传统的深层神经网络可以堆叠数百层以获得更好的性能,从而大大提高了表达能力。然而,图神经网络总是浅层的,大多数不超过三层。[62] 中的实验表明,叠加多个 GCN 层将导致过度平滑,也就是说,所有顶点将收敛到相同的值。尽管一些研究人员已经设法解决了这个问题 [45],[62],但它仍然是 GNN 的最大限制。
Dynamic Graphs
另一个具有挑战性的问题是如何处理具有动态结构的图。静态图是稳定的,因此它们可以建模的可行性,而动态图引入变化的结构。当边缘和节点出现或消失时,GNN 不能自适应地变化。动态 GNN 正在被积极研究,我们认为它是一般 GNN 稳定性和适应性的一个里程碑。
Non-Structural Scenarios
尽管我们已经讨论了 GNN 在非结构场景中的应用,但是我们发现没有最佳的方法从原始数据生成图。在图像领域,一些工作利用 CNN 获取特征映射,然后将它们上采样形成超像素作为节点 [49],而另一些工作直接利用一些对象检测算法获取对象节点。在文本领域[103]中,一些工作使用语法树作为语法图,而另一些工作使用全连通图。因此,寻找最佳的图形生成方法将为 GNN 的贡献提供更广泛的领域。
Scalability
如何在像社交网络或推荐系统这样的网络规模条件下应用嵌入方法一直是几乎所有图形嵌入算法面临的致命问题,GNN 也不例外。由于许多核心步骤在大数据环境中都是计算消耗的,因此难以扩展 GNN。关于这种现象有几个例子:第一,图数据不是正则欧几里德,每个节点都有自己的邻域结构,所以批处理不能应用。那么,当节点数和边数达数百万时,计算图的拉普拉斯也是不可行的。此外,我们需要指出的是,缩放决定了算法是否能够应用到实际应用中。几项工作已经提出了解决这个问题的办法[120]。
5 CONCLUSION
近年来,图神经网络已经成为图域机器学习的有力工具。这一进步归功于表达能力、模型灵活性和训练算法的进步。在这个调查中,我们进行了图神经网络的全面审查。对于 GNN模型,我们介绍了它的变体,按照图类型、传播类型和训练类型进行分类。此外,我们还总结了几个通用框架,以统一表示不同的变体。在应用程序分类方面,我们将 GNN 应用程序分为结构化场景、非结构化场景和其他场景,然后对每个场景中的应用程序进行详细的回顾。最后,我们提出了四个有待解决的问题,指出了图神经网络的主要挑战和未来的研究方向,包括模型深度、可扩展性、处理动态图形和非结构性场景的能力。
论文地址