参数估计、假设检验与回归
参数估计、假设检验统计总体架构

拟合(fitting)
| 概念 |
已知某函数的若干离散函数值{f1,f2,…,fn},通过调整该函数中若干待定系数f(λ1, λ2,…,λn),使得该函数与已知点集的差别(最小二乘意义)最小。如果待定函数是线性,就叫线性拟合或者线性回归,否则叫作非线性拟合或非线性回归。 |
参数估计
| 概念 |
在已知系统模型结构时,用系统的输入和输出数据计算系统模型参数的过程。 |
点估计
| 方法 |
最小二乘法和极大似然法(见Logistic regression 及MLR) |
最小二乘法(least-squaresmodel)
| 概念 |
使误差的平方和 ∑[p(Xi)-Yi]^2 最小 |
| Equation |
最小二乘矩阵形式: 计算 |
| 分类 |
普通最小二乘(OLS)、偏最小二乘、有条件(CLS)、正则化、加权 |
极大似然估计方法(Maximum Likelihood Estimate,MLE)
| 概念 |
在已知总体X概率分布时,对总体进行n次观测,得到一个样本,选取概率最大的 |
| Equation |
选取 |
| 例 |
例:设总体X服从参数为p的0-1分布,(X1, X2, …, Xn) 是来自X一个样本,求p的极大似然估计。 解:X的概率分布为
似然函数
其中x1, x2, ..., xn 在集合{0,1} 中取值。
对数似然函数:
|
| 注意 |
极大似然估计只是一种粗略的数学期望,要知道它的误差大小还要做区间估计。 |
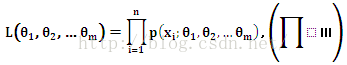
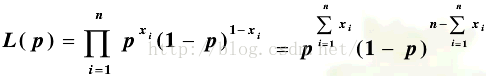

区间估计(interval estimation)
| 概念 |
根据样本确定待估参数 的置信区间 |
| 方法 |
常见的分布统计量(参见参考文献中的“统计学区间估计公式汇总表”)、Bootstrap方法 |
| 区分 |
区间估计:正向求解,目的是对未知参数的一个取值变化范围(区间)的检验; 假设检验:逆向求解,目的是对已经给出的有关未知参数的一个结论作检验,看这个说法是不是应该被拒绝 |
置信区间(confidence interval)
| 概念 |
显著性水平(符号:α) 如5%,小于给定标准的概率区间称为拒绝区间,大于这个标准则为接受区间(置信区间 confidence interval)。
置信水平(符号:1-α) 反之。 |
| 例 |
|
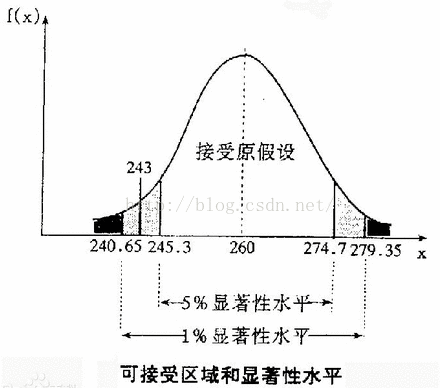
假设检验(Hypothesis Testing) / 显著性检验(Significance Test)
| 概念 |
根据一定假设条件由样本推断总体的一种方法,计算求出特定统计量(如t,F,卡方等),根据预先给定的显著性水平进行检验,作出拒绝或接受假设H0的判断。 |
| 分类 |
参数检验(parameter test)、非参数检验(Nonparametric tests) |
| 方法 |
参数:F检验、t检验 非参数:拟合优度检验、Shapiro-Wilk W检验、D'Agostion's D检验、秩和检验 |
| Terms |
Sample |
| 原假设、备择假设 |
原H(),备H1() |
| 检验统计量 |
Ex,H: Ex = 8,H1: Ex > 8 |
| 临界值c |
X > c,拒绝H;X < c,保留H |
| 拒绝域W、接受域A |
假设H被拒绝的样本值集合为拒绝域 |
| 显著性水平a |
“H为真但被错误拒绝”的概率,如0.05 |
| 参数检验、非参数检验 |
参数检验:总体分布已知,对参数假设检验 |
| 单边、双边检验 |
拒绝域W={x>=c}单边,W={x<=c1或x>=c2}双边 |
| 判断 |
拒绝H0,则模型为真 |
F检验(方差分析、方差齐性检验、似然比检验 Analysis of Variance, ANOVA, Fisher)
| 概念 |
检验两个样本的方差是否有显著性差异(通俗点,判断两方差是否足够接近)。这是选择何种T检验的前提。 当自变量只有一个时,方差分析与t检验的结果等价。 R-squared是查看方程拟合程度的;F检验是检验方程整体显著性的;T检验是检验解释变量的显著性的。 |
| 公式 |
F统计量的构造即为 两个服从卡方分布的统计量分别除以各自的自由度再相除。 F=(w/n)/(v/m) 其中 W,V为服从卡方分布的统计量,n,m为W,V的自由度 |
| 判断 |
原假设:H0——无差异;H1——有显著差异 F value的P值<显著性水平(如0.05),则方程显著 |
| 单因素 |
单因素方差分析(one way),有一个自变量 |
| 两因素 |
两因素方差分析(two way),有两个自变量,如教学方法(A1,A2,A3)学生年级(B1,B2),第一个自变量有3个水平,第二个有2个水平,3x2共六种组合 |
| 多因素 |
又可分为多重比较检验和对比检验 |
t检验(studentt检验)
| 概念 |
主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布资料。 两组以上比较,或含有多个自变量,需要用方差分析,方差分析被认为是T检验的推广。 |
| 判断 |
H0两个平均数之间没有显著差异(即自变量对因变量无显著影响,如:性别为x,身高为y,男平均身高=女平均身高),一旦显著,则接受H1,自变量参数有效。 |
| 分类 |
(1)单总体(单样本 / single sample) (2)双总体检验(two sample) (2.1)独立样本(dependent) (2.2)配对样本t检验(非独立t检验 / paired samples / indenpendent) |
z检验(u检验)
| 概念 |
z检验用于在总体标准差已知的情况下比较样本均值与总体均值,样本容量大于30平均值差异性检验。 |
| 判断 |
H0两个平均数之间没有显著差异 |
| 前提 |
总体参数标准差已知!(更多情况下,总体标准差未知时,但样本来自正态分布时,仍考虑采用t检验) |
非参数检验(Nonparametric tests)
| 优缺点 |
优点:在不假定总体分布的情况下,从数据本身,由于要求的信息少,适应性相对更广 缺点:对总体分布没有要求,方法上缺乏针对性 当然,如果我们事先对总体分布信息一无所知或难下定论,那么建立在数据本身基础上的非参数检验结果要比建立在一个可疑的总体分布上得到的参数检验结果要可靠得多。 |
拟合优度检验(test of goodness of fit)
| 概念 |
主要是运用判定系数(或称拟合优度)和回归标准差,检验模型对样本观测值的拟合程度。 |
| 方法 |
卡方检验 |
| 注意 |
当解释变量为多元时,要使用调整的拟合优度,以解决变量元素增加对拟合优度的影响。 |
决定系数 / 判定系数 / 拟合优度Coefficient of determination
| 概念 |
拟合优度越大,自变量对因变量的解释程度越高,相关的方程式参考价值越高. R2(R squared),相关系数(coefficient of correlation)的平方即为决定系数。 |
| Equation |
|

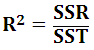
卡方检验(χ2检验、皮尔逊检验 Chi-square fitting test、Pearson)
| Equation |
A代表观察频数,E代表基于假设H0的期望频数,A与E的差为残差 确定显著性水平如α=0.05,查x2值表得到否定域的临界值 |
| 判断 |
如:临界值 > 统计量χ2,接受假设H0 |
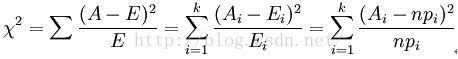
赤弛弘次信息量AIC
| 概念 |
Akaike information criterion,为日本统计学家赤池弘次创立,建立在熵的概念基础上,判断模型拟合数据的优良性。 |
| Equation |
AIC=2k-2ln(L) 其中:k是参数的数量,L是似然函数。 假设条件是模型的误差服从独立正态分布。 让n为观察数,RSS为剩余平方和,那么AIC变为: AIC=2k+nln(RSS/n) |
| 判断 |
优先考虑模型应是AIC值最小的那一个 |
Reference
经典非参数假设检验方法全
统计学区间估计公式汇总表
http://wenku.baidu.com/link?url=Ui6nRPtMhetUXVhb5ExcEAUJXXibNuf_GwczmpuCSa5USi4UQy1N2gLVf5hqhHMy9Gzy0y-0fchRQ0CU6naC_sz7WhXNiMAin6HJkf9Q0gq
极大似然估计
http://wenku.baidu.com/view/b4d058d17f1922791688e8d1.html
回归总体架构
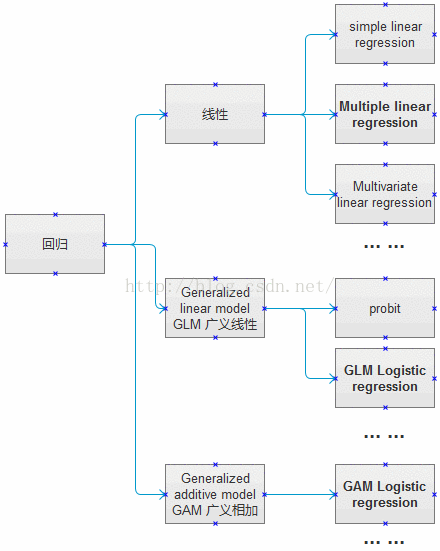
Simple Linear regression

多重共线性问题(Multicollinearity)
| 概念 |
回归模型中的解释变量之间由于存在高度相关关系而使模型估计失真 |
| 判断 |
1、特征值; 2、条件索引; 3、方差比例 |
| 解决 |
1、尝试增大样本量; 2、去除专业上认为不重要但带来强共线性的变量; 3、时间序列数据、线性模型:将原模型变换为差分模型; 4、进行主成分、因子分析,将多个共线性强的自变量综合成少量的新变量; 5、进行岭回归分析(Ridge Regression)、通径分析 |
逐步回归分析
| 概念 |
解决多重共线性问题,变量选择方法。 回归方程是显著的,方程中的自变量也是尽可能显著的,这才是最佳的回归模型。 |
| 原理 |
引入变量Xi或剔除变量Xi所进行的F检验,一般 F进>=F出 包括3种方法:(1)forward,不断引入;(2)backward,不断剔除;(3)both,向前向后,反复引入剔除。 |
回归系数regression coefficients
| 概念 |
表示自变量x 对因变量y 影响大小的参数,正回归系数表示y 随x 增大而增大,负回归系数表示y 随x增大而减小。用 表示,通常使用极大似然估计。 e.g. 回归方程式Y=a+bX 中的斜率b就称为回归系数。 从本质上说决定系数和回归系数没有关系。 |
广义线性模型Generalized linear model(GLM)
一般线性模型,其基本假定是y服从正态分布,而广义线性模型则y服从其它分布(如一般logistic模型中y服从二项分布)。
自变量x、因变量y主要可以分为:
(1) 连续变量,如面积、数值范围;
(2) 有序变量(等级变量),如-/+/++,0~10/10~20/20+;
(3) 分类变量,如广州/深圳/珠海,等级为二即二分类变量(0-1变量);
GLM 很难处理连续型解释变量的情况,解决方法,将连续型解释变量的可能取值进行分组,缺点不是所有的连续型解释变量都适合分组。这时可考虑GAM。
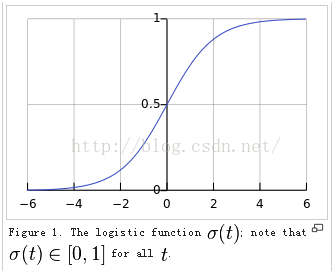
Logisticregression (or logit regression)
| 概念 |
属非线性回归,是研究二分类或多分类观察结果的多变量分析方法。 |
| 变量特点 |
应变量:1个,二项分布或多分类分布 自变量:2个及2个以上 |
| 回归系数估计方法 |
极大似然法 |
| 回归模型系数检验 |
似然比检验、Wald检验、比分检验 |
| 模型拟合效果评价 |
总符合率、Hosmer-lemeshow拟合优度统计量 |
| 分类 |
binominal(or binary): dependent variable can have only two possible types(e.g. "win" vs. "loss"). multinominal: more than two categories. ordinal: the multiple categories are ordered. vise versa, 无序。 条件、非条件logistic回归 |
| Equation |
logit变换
Odds
odds: probability that an outcome is a case divided by the probability that it is a noncase.
Odds ratio
解释:The odds multiply by |

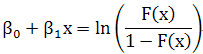
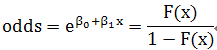
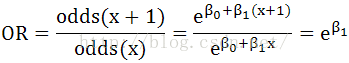
多元线性回归Multiple Linear Regression(MLR)
| 概念 |
two or more independent variables (IVs) and a single dependent variable (DV). |
| 变量特点 |
应变量:1个,正态分布 自变量:2个及2个以上 |
| 回归系数估计方法 |
最小二乘法 |
| 回归模型系数检验 |
方差分析(F检验)、t检验 |
| 模型拟合效果评价 |
决定系数R2、复相关系数R、校正决定系数 |
| Equation |
矩阵形式: R is the multiple correlation coefficient, R can only range from 0 to 1, with 0 indicating no relationship and 1 a perfect relationship. R2 values would indicate 10%, 30%, and 50% of the variance in the DV |
| 区分 |
Multiple linear regression A single output Y is influenced by a set of input X=(X1, ... ,Xr),即两个或两个以上的自变量,相对应的是一元线性回归。是简单直线模型的直接推广。
Multivariate linear regression A output Y=(Y1, ... ,Ys), each of them may be influenced by input X=(X1, ... ,Xr). The components of Y are also correlated with each other (and with the components of X). |
| Assumptions |
1. Sample size: 50 + 8(k) for testing an overall regression model (where k is the number of IVs) 2. Normality the variables are normally distributed 3. Linearity the bivariate relationships need to be linear 4. Homoscedasticity Are the bivariate distributions reasonably evenly spread about the line of best fit? 5. Multicollinearity Is there multicollinearity between the IVs? 6. Multivariate outliers(MVOs) 7. Normality of residuals Residuals are more likely to be normally distributed if each of the variables normally distributed |
广义相加模型Generalized additive model(GAM)
| 概念 |
回归模型中部分或全部的自变量采用平滑函数,降低线性设定带来的模型风险 |
| Equation |
fi(xi)为光滑函数,代替经典线性回归中的xi,对样本要求少,适用性广。 |
| 估计方法 |
最小二乘法 |
取值
| Y的分布 |
联系函数名称 |
f(Y) |
| 正态分布(normal) |
Identity |
Y |
| 二项分布(binomial) |
Logit |
Logit(Y) |
| Poisson分布 |
Log |
Log(Y) |
| γ 分布(gamma) |
inverse |
1/(Y-1) |
| 负二项分布(negative binomial) |
Log |
Log(Y) |
E.g.
logit变换
Reference
logistic回归与多元线性回归区别及若干问题讨论http://www.docin.com/p-578018693.html
http://www.empowerstats.com/manuals/empowerRCH/html/index.php?b=s5_gam&m=
数理统计
http://wenku.baidu.com/link?url=5GnKukkTKQjxFXnNsjKcVPqfWumtgWAMFEP4Xbgqr4phtX2FTQjFAaLq4tLyff-BOD1JXwDC-1HAimFdCk2-kQg9-72TXxkbayGq8i-tTzO