从能做什么到如何去做,一文带你快速掌握Python编程基础与实战
摘要:Python语言的教程虽然随处可见,但是忙于日常业务/学习的你或许:一直想要“找个时间学一点”,但是又不知道该从何下手?本文将从Python能做什么,如何学习Python以及Python的基础知识为你的Python之路点上一盏明灯。
本节课程视频地址:https://yq.aliyun.com/video/play/1359 讲义与代码下载地址:https://yq.aliyun.com/download/2466
本文内容根据演讲视频以及PPT整理而成。
本文的分享主要围绕以下几个方面:- Python能做什么?(常见应用场景介绍)
- 如何学习Python?
- Python语法基础实战
- Python面向对象编程实战
- 练熟基础:2048小游戏项目的实现与实战

一种编程语言往往可以应用于多方面,有些方面比较常用,有些方面极为常用。上图中标红的部分是Python极为常用的领域。首先,利用Python可以进行简单脚本编程,比如使用Python编写2048小游戏或12306的自动抢票软件。其次,可以使用Python进行系统编程,开发系统应用。第三点,Python一个较为常用的功能就是开发网络爬虫。网络爬虫的用途是进行数据采集,也就是将互联网中的数据采集过来。网络爬虫的难点其实并不在于爬虫本身,由于网站方为了避免被爬取回采取各种各样的反爬虫措施,而如果想要继续从网站爬取数据就需要解决这些反爬虫措施,所以网络爬虫的难点在于反爬的攻克和处理。第四点,Python极常用于WEB开发,可以借助Python开发WEB站点,比如个人博客、在线教育网站以及论坛等。第五点,在运维方面,Python可以用于自动化运维,可以通过写Python脚本实现对于服务器集群进行自动化管理。第六点,Python可以用于网络编程,比如Socket编程等。第七点,Python极常用的一个方向就是数据挖掘、机器学习等大数据与人工智能领域方向的程序开发,比如在人工智能领域,使用Python就可以很容易地实现算法模型,并且借助Python可以很容易地处理相应的数据。
作为系列文章的首篇,本文将为大家分享Python的基础知识。而学习Python基础的第一步就是认识Python可以干什么,通过上面的内容,大家可以了解到Python语言可以做很多事情,或者可以说Python基本上是一门全能的语言。Python在各个领域都很优秀,而最重要的一点就是Python比较易学。综上所述,Python是一门非常棒的语言。
二、如何学习Python?
首先与大家分享一些方法论,究竟应该如何学习Python?其实学习任何一门知识,方法都是类似的,有些同学习惯直接看书或看视频,这些方法都不错,但是在学习的过程中需要掌握一些技巧,这样学习起来会事半功倍。
成体系地学,不搞“题海战术”
首先,要学就要成体系地学,不搞“题海战术”。遇到新知识就去查,然后就知道了,反复这样就是所谓的“题海战术”,这样做的好处就是用到了就会去寻找,但是缺点就是脑海里面的知识体系会非常乱,而且越学越乱,因为太多东西在脑海中不成体系地堆积导致非常难以利用,所以需要成体系地学习。所谓成体系地学习,就比如在学习基础时可以先掌握数据类型、控制结构、函数以及模块等,将这些知识形成体系。构建知识体系就像写书一样,在写书的过程中不可能想到哪里就写到哪里,而应该有一个大致的框架。成体系地学习的好处就是无论怎样学习都不会乱。而且最开始的体系不一定是非常完备的,比如在刚开始学习编程语言的时候可能并不知道迭代器和生成器,但这并不会影响知识体系的建立,而在后续学到迭代器和生成器的时候,再将这一部分的知识加入到知识体系中就可以了。但是这样的前提就是在脑海中一定要有一个非常清晰的体系结构,学到的新知识都可以归入到体系中,如果遇到了知识体系中没有的内容就可以对应地进行补充,这样就形成了非常清晰的体系结构,这样的学习方法收益会比较大。
不仅要“摹”,还要“临”
其次,不仅要“摹”,还要“临”。“临摹”是练习书法的手段,所谓“临”就是看着字帖中的字,凭着印象在纸上书写并且尽量复现字帖中的字;所谓“摹”就是在字帖上面蒙上一层薄白纸,然后在上面跟着字帖直接描。在“临”与“摹”中,显然后者更为简单。其实,学习任何一门知识都一样,不仅要“摹”,还要“临”。在学习Python等编程语言时,一些同学可能学习时看看视频就过去了,这样显然是不可取的,好一点的同学会在看过视频之后,跟着视频把代码敲一遍,但是这样只是进行了“摹”,应该在此基础之上加上“临”的步骤,也就是关上视频、合上书本之后,凭借记忆对代码进行复现,去想自己的代码需要实现哪些功能,这样才能将知识真正地吸收。这样练习久了之后就会发现自己的能力提升得非常快。
通所有不如精一物,精一物方可通所有
第三个学习方法就是通所有不如精一物,精一物方可通所有。大家在学习的时候可能会遇到很多的框架,但是其实并不需要掌握所有的框架,比如对于爬虫而言,既可以学习Scrapy,也可以学习urllib,还可以学习其他的框架。其实并不用掌握所有的框架,学习时可以深入地掌握其中一两个框架,之后就会发现所有的框架都是万变不离其宗的。精通一两个框架之后,其他的框架也会很容易掌握。学习编程语言也是一样的,当你精通了PHP或者Java,Python也能很快学会,但是如果同时学习Java、Python和PHP,最终可能导致每一门语言都不精通。其实学习过程的曲线在刚开始的基础阶段上升会非常慢,但是只要上手之后,进度就会非常快,所以大家在学习基础的时候一定不要着急。
走心学,忌浮躁
第四个学习方法就是走心学,忌浮躁。学习的时候一定要投入心思,不要着急,尽量地将知识掌握和精通。更加具体的学习方法,大家可以关注云栖社区上的这个聚能聊:https://yq.aliyun.com/roundtable/65789。
在Python语法的基础实战这部分将与大家分享数据类型、控制结构、函数与模块、文件操作与数据库操作以及异常处理等内容。
Python基础知识入门
在Python中输出直接使用print()函数,如果在Python文件中重复四次print("Hello Python"),那么输出时就是四次“Hello Python”。如果想让某一行代码不起作用,可以使用注释。在Python中有两种比较常见的注释方案,第一种是单行注释,在行首加“#”,这样就会注释掉这一行代码;第二种是多行注释,多行注释一般使用“'''”或“"""”(三引号)实现,直接将需要注释的代码段的首部和尾部加上三个引号即可。
数据类型
在学习任何一门编程语言时,都需要了解这门编程语言有哪些数据类型。在Python中,常见的数据类型有数、字符串、列表、元祖、集合以及字典等。
数:就是数学上的数字,比如“a=7”就是将数字7赋值给a,这里的等号是赋值的意思。想要查看对应的数据是什么类型可以使用type()函数查看,比如7就是int整形,7.0就是float浮点型。
字符串:一系列字符所组成的序列叫做字符串。字符串一般使用引号将其引起来,这里使用单引号和双引号均可。比如:
a1='abc'
a2="abc"
a3='''ab
c'''上述代码所表达的内容是相同的,区别在于使用单引号和双引号所引起来的内容不能直接换行,而使用三引号就可以。
列表:存储多个元素的容器,列表中的元素可以被重新赋值,也就是说列表中的元素是可以变化的。建立列表可以通过“[]”实现,在其中可以放置数据。比如:a=[]表示a是一个空列表。再比如a=[a1,a3],列表中每个元素之间使用逗号隔开,a这个列表中包含了a1和a3两个元素。取其中的元素可以通过下标实现,比如a[1]就可以取出a1的值。而列表中的元素可以被重新定义,比如使用a[1]="hello" 就可以对原本a[1]的位置进行赋值,这就说明了列表中的元素是可以变化的。
元组:存储多个元素的容器,但是元组中的元素不可以被重新赋值。比如c=(7,"cd",9),c存储了一组数据,如果想要对c中任意位置赋值成为其他的数据,都是不可以的,因为元组内的数据是不能被更改的。所以,元组一般在对数据安全要求较高时使用,这也是元组与列表的区别。
字典:字典相当于关联数组,所谓关联数组就是里面需要存储一对信息的数组。列表和元组存储的元素都是一个,而字典存储的元素都是一对信息如d={"name":"weiwei","sex":"boy","job":"teacher"}这样的{键:值, 键:值, ...}。在取值的时候直接使用字典名["对应键名"]即可,比如对于上诉d这个字典,使用d["name"]就可以取到"weiwei"这个值。
集合:集合也是用于存储一组数据的,只不过集合的特性是不允许出现重复的元素,这一点大家早在高中就已经学习了。所以,集合的一个非常简单的应用就是去重,之所以说这个方法简单,是因为去重还有很多的实现方法,比如布隆过滤器等都是非常好的去重方式。在Python中直接通过set就可以直接建立集合,比如e=set("abcdefgabc"),而集合是通过“{}”存储的,只不过大括号里面直接存储元素。而当输出e时就会发现,原本重复的内容就只保留一个。此外,集合还可以用于差集的运算,比如e=set("abcgjkhsgkjha"),f=set("jikhsdghsdueigdsfzau")直接使用g=e-f就可以获得e与f的差集。
运算符
以上的这些数据类型归根结底都是数据。数据是静态的,而通过运算符进行运算就可以让这些数据动起来。Python里面的运算符有哪些呢?首先就是大家非常熟悉的“+-*/%”,这些运算都满足数学规律。除了“+-*/%”之外,还有字符串连接符“+”,如果想要将两个字符串连接起来只需要用“+”即可。
缩进问题
可能某些同学对于Python的缩进比较反感,会觉得缩进很麻烦并且非常容易出错。但是实际上,缩进很美,当打开Python项目时就会发现层次感很强,会感受到代码的美感,哪些代码属于同一层级是一目了然的。缩进所需要掌握的规律就是最开始的代码顶格,第二点就是同一层级的代码在同一个缩进幅度上,下一个层级的代码在下一个缩进幅度上。当掌握了缩进规律之后,再去写Python代码就会很容易了。
控制结构所谓控制结构就是程序的执行结构,程序可以像流水账一样顺序执行下去,也可以跳跃、循环以及分支执行,这些多种的执行方式叫做控制结构。实际上,Python中最常用的控制结构只有三种就是:顺序结构、选择结构和循环结构,当然还有一些不常用的控制结构比如中断结构等。
顺序结构不必多讲,就是按照顺序写,程序也就按照顺序执行。在Python中,分支结构通常使用if语句实现,如果if的条件为真,则执行下面对应的代码,否则继续向下看是否有分支结构,如果有则继续执行,否则就执行这一部分内容;如果if的条件为假,就不执行下面对应的代码。如下示例代码:
a=1000
b=1
if(a>19 and a<30):
print(a)
if(b<9):
print(b)
elif(a>9 and a<=19):
print("a>9 and a<=19")
elif(a<9):
print("a<9")
else:
print("gsdajk")上述代码中第3行的if条件判定结果为真,程序会执行第4行至第6行代码。如果第3行的if判定为假,则继续向下面找寻分支。第7行和第9行都存在elif,其意思就是在不满足if的情况下如果满足elif的条件,就执行elif下面的代码,如果上述两行的elif条件都不满足,在第11行还有一个else,其意思就是在上述条件都不满足的情况下,执行else下面的代码。上述代码最终将会输出“gsdajk”。这里值得说明的一点就是如果实际情况不需要,可以没有elif以及else等语句,也就是可以单独使用if语句。
循环结构也是一个极为重要的结构。在Python中,循环结构有相应的方法去实现,常用的有两种:while和for语句。while语句的格式如下所示:
a=0
while(a<10):
print("hello")
a+=1首先写while的条件,所谓的条件就是while括号中的表达式。如果条件为真就意味着满足了while的条件,这样就会执行while下面的代码段,而在执行时不是仅执行一次就结束,而是只要while循环的条件一直满足,这段代码就会一直执行。上述代码中,a的初始值为0,循环结构中将会打印“hello”并使得a自增1,当a<10时循环结构就会一直执行,所以将会输出10次“hello”。当到执行到第10次之后,a就不满足小于10的条件了,于是就会跳出循环。
除了while循环之外,还有for循环。for循环的写法稍有不同,常用的格式是for i in x,x一般而言是一组数据。for循环遍历列表示例如下,该程序将会循环输出列表中的各个元素。
a=["aa","b","c","d"]
for i in a:
print(i)for i in range(0,10):
print("hello")a=["aa","b","c","d"]
for i in a:
if(i=="c"):
break
print(i)a=["aa","b","c","d"]
for i in a:
if(i=="c"):
continue
print(i)使用Python输出乘法口诀表
for i in range(1,10):
for j in range(1,i+1):
print(str(i)+"*"+str(j)+"="+str(i*j),end=" ")
print()如上述代码所示,乘法口诀表分为行和列的控制,最外层循环控制行数,所以外层循环是for i in range(1,10),就是从1一直遍历到10。而对于列的控制就需要内层循环,显然就是在i层下面再进行一层循环,如上述代码中的for j in range(1,i+1),因为当遍历到1的时候,结果是1*1,不需要继续写1*2,所以这里只需要遍历到i+1即可。具体的输出只需要进行简单的数学运算和字符串拼接即可,在print输出之后如果不通过end控制是会默认更换一行的,这样输出的结果不够美观,上述代码的写法可以使得同一行print输出的结果之间隔一个空格。而在完成了j的遍历之后需要另起一行,所以需要print()。运行结果如下图所示:

在理解了乘法口诀表的实现之后,大家应该思考如何将乘法口诀表逆序输出,形成倒三角形式。显然,只需要对代码做如下修改即可:
for i in range(9,0,-1):
for j in range(i,0,-1):
print(str(i)+"*"+str(j)+"="+str(i*j),end=" ")
print()函数与模块
函数相当于功能的封装。举例而言,某个程序段可能会被经常调用,如果不进行功能封装,那么每次调用这个功能时就需要重新实现一遍该段程序,这就会带来很多麻烦。而现在可以将这个经常被调用的程序段封装成一个函数,如果需要实现这个功能就可以直接调用这个封装好的函数。接下来就与大家分享与函数相关的内容。
作用域:作用域一般而言指的是变量的作用范围。
i=10
def func():
print(i)
func()def func():
i=10
print(i)
func()i=10
def func():
global i
print(i)
func()函数定义的格式:函数定义的格式就是如何将一串代码封装为成函数的方式。函数是通过def关键字定义的,函数定义格式如下:
def 函数名(参数):
函数体def abc():
print("abcde")
print("456")
abc()函数参数:如果函数没有参数,那么这个函数就是固定的,因为该函数内部的代码是固定的,所以无论怎样执行都是同样的结果。而如何使得函数能够实现具体问题具体分析呢?此时可以为其传入相应的参数,这样函数就可以根据所传入的参数进行相应的数据处理。参数就相当于函数与外界沟通的接口。参数分为形参和实参,一般而言在函数定义的时候使用参数就是形参,所谓形参就是“形式上的参数”;在函数调用的时候使用的就是实参,而所谓的实参就是“实际的参数”。如下的代码段中实现了两个数据比较大小的功能:
def func2(a,b):
if(a>b):
print(str(a)+"比"+str(b)+"大")
else:
print(str(b)+"比"+str(a)+"大或者"+str(b)+"与"+str(a)+"相等")模块:模块就相当于函数的再次封装。Python中有一些常用的模块,这些常用的模块存在于Python的安装目录之下,其中有一个名为“lib”的目录,该目录一般就用于放置模块,而且大家也可以自己写模块,这样的模块就叫做自定义模块。
在Python中想要使用模块需要掌握两个知识点:导入和使用。一般而言有几种方法导入模块,第一种方法就是使用import语句直接导入某个模块,第二种方法就是从某个模块中仅导入某个方法。如下代码所示,可以从time模块中导入sleep方法,也可以使用from time import *将time模块的所有方法都导入进来。
import random
from time import sleep
from time import *
a=["中奖","不中奖","不中奖"]
print(random.choice(a))random模块主要用于随机数的处理。上述代码使用random实现了一个抽奖功能,首先导入了random,然后建立一个列表,里面有“中奖”和“不中奖”选项,random.choice(a)将会随机在列表a中选择一个选项并输出对应的结果。time模块也有一些比较常用的功能,比如time.sleep(),其实现了延时功能。如果想要修改模块的源代码,只需要在lib目录下找到相应的模块进行修改即可。
此外,第三方的模块一般放置在lib目录下的site-packages中。
三、文件操作与数据库操作
文件操作
文件的打开:使用Python打开文件方法的格式就是open(文件地址,操作形式),open函数的参数中的操作形式有:w(写入)、r(读取)、b(二进制)、a(追加),其中的a表示可以实现追加写入,这样就不会丢失原来的内容,如果使用w就是全新写入,将会覆盖原本的内容。
fh=open("D:/我的教学/Python/20180120内训/第1天代码/文本1.txt","r",encoding="utf-8")
#文件读取
data=fh.read()
line=fh.readline()x=0
fh=open("D:/我的教学/Python/20180120内训/第1天代码/文本1.txt","r",encoding="gbk")
while True:
line2=fh.readline()
if(len(line2)==0):
break
print(line2)
x+=1
fh.close() 上述代码中使用readline()一行行地读取文件,这里通过设置while循环来读取文件全部内容,如果某一行的长度为0则说明文件已经读完,此时就可以break,而如果不为0则说明还有内容,就可以继续读取下一行。上述代码中还通过变量x统计共读取了多少次,在文件读取完后通过fh.close()关闭文件。结果输出后还可以通过x获取读取的总行数。

文件的写入(w/a+):在进行文件写入时,在open函数中的操作形式的参数应该为“w”或者“a”,参数中的文件地址则是输出地址。如下代码段所示:
data="一起学Python!"
fh2=open("D:/我的教学/Python/20180120内训/第1天代码/文本3.txt","w")
fh2.write(data)
fh2.close()在文件地址中,不能够使用“\”,而应该使用“\\”或者“/”。在打开文件之后使用write方法将数据写入之后,将文件关闭即可。如果操作形式为“w”,将会把原本的文件内容替换掉,也就是全新写入的意思,而如果使用“a+”就是在原本内容的基础上进行追加。
数据库操作
Python除了用于操作文件之外,还常用于操作数据库,本文以操作MySQL数据库为例讲解。在使用Python操作数据库之前需要先安装pymysql模块,在cmd命令行中输入“pip install pymysql”即可完成该模块的安装。
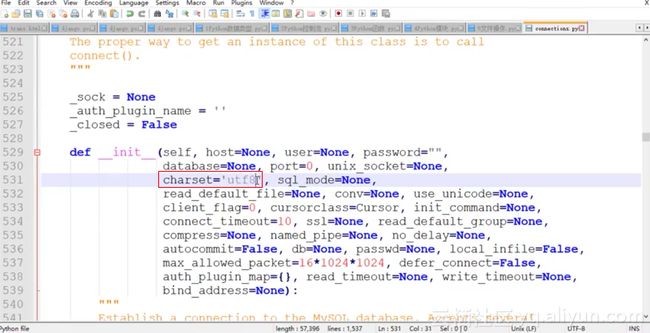
在安装完pymysql之后,还需要将其中的源代码进行一定的修改,因为使用其默认编码会出现错误。在site-packages下面找到pymysql,并找到connections.py文件,搜索“charset=”关键词就可以定位到需要进行修改的地方。
使用Python进行数据库的操作的前提是需要一个MySQL数据库,至于MySQL数据库的安装和配置不是本文所关心的对象,大家可以自行学习。在拥有了MySQL数据库之后首先应该进行数据库的连接。
import pymysql
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="root",db="mypydb")
#执行sql语句-无返回
conn.query("INSERT INTO mytb(title,keywd) VALUES('new title','23456')")
conn.commit()
#执行SQL语句-有返回
cs=conn.cursor()
cs.execute("select * from mytb")
for i in cs:
print("当前是第"+str(cs.rownumber)+"行")
print("标题是:"+i[0])
print("关键词是:"+i[1])
conn.close()异常处理
在Python中经常会出现这样或那样的错误,有些错误是不可避免的,甚至是未知的。对于未知的错误,当Python执行时遇到后就会自动终结。而如果希望在遇到错误之后程序能够继续运行则需要使用异常处理。异常处理的格式如下:
try:
程序
except Exception as 异常名称:
异常处理部分try:
for i in range(0,10):
print(i)
if(i==4):
print(jkj)
print("hello")
except Exception as err:
print(err)如上述代码段,当i循环到4的时候将会出现异常,因为jkj没有在程序中定义。如果没有异常处理,程序将会直接终结,而使用了异常处理之后,当发生异常也不会直接标红,而是将异常输出。

而如果不采用异常处理,当出现错误时将会直接标红,如下图所示:
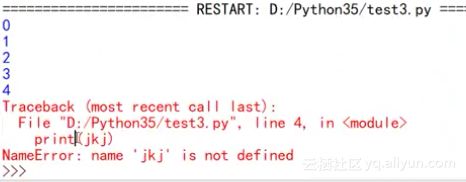
异常处理的目的是让程序在出现异常的情况下继续执行下去,所以需要将异常尽量细化,使异常处理与所需要监控的代码更加紧密。对于上述代码进行异常处理细化之后如下:
for i in range(0,10):
try:
print(i)
if(i==4):
print(jkj)
except Exception as err:
print(err)
print("hello")四、Python中面向对象编程实战
上述内容帮助大家了解了Python在语法层面的基础知识,接下来为大家分享Python中面向对象编程实战。面向对象编程一般区别于面向过程,其更适合于中大型的项目的开发。
认识类和对象
面向对象编程主要是通过“类”和“对象”实现的。举例而言,具体的某个人就是“对象”,小明是一个对象,小张也是一个对象,而将“对象”共有的特点抽象出来就能够形成“类”,比如小张和小明都是“人”,那么“人”就是一个“类”,所以“类”就是类型的意思。只不过面向对象的类是自定义的。“类”是抽象出来的,“对象”则是具体的。
如果想要建立一个类则可以使用class字段进行声明:
class 类名:
类里面的内容class cl1:
pass而将类实例化成为对象可以使用类名后面加括号并直接赋值给一个对象,如a=cl1(),那么a就是cl1这个类的一个对象。
构造函数
构造函数也叫作构造方法。所谓构造方法就是专门用于初始化的方法。这里还需要介绍self,一般在类中的方法必须加上self参数,其代表类本身。在Python中__init__(self,参数)就是构造方法,构造方法的名字是固定的,在括号里面加上self以及对应的参数即可。构造函数的实际意义就是初始化。class cl2:
def __init__(self):
print("I am cl2 self!")class cl3:
def __init__(self,name,job):
print("My name is "+name+" My job is "+job)属性和方法
属性就相当于是类中的变量,方法就相当于类中的函数,属性是静态的,方法是动态的。举例而言,对于“人”这个类,手、头这些都属于属性,而人会说话、写字这些都是方法。在Python里面,属性的使用方式一般是self.属性即可。
class cl4:
def __init__(self,name,job):
self.myname=name
self.myjob=jobclass cl5:
def myfunc1(self,name):
print("hello "+name)
class cl6:
def __init__(self,name):
self.myname=name
def myfunc1(self):
print("hello "+self.myname)继承
简单而言,继承就是将某个类中所有的属性和方法都拿过来直接使用,举例而言:某一个家庭有父亲、母亲、儿子和女儿,父亲可以说话,母亲可以写字,大儿子继承了父亲,女儿同时继承了父母,并且有新能力听东西,小儿子继承了父亲,但是优化(或减弱)了父亲的说话能力,这样的模型应该如何建立呢?被继承的这个类被称为基类或者父类,继承的类叫做子类。所以模型中的服务都是基类,儿子和女儿都是子类。
首先创建父亲类,他的功能是可以说话:
class father():
def speak(self):
print("I can speak!")class son(father):
pass母亲类具备写的能力:
class mother():
def write(self):
print("I can write")class daughter(father,mother):
def listen(self):
print("I can listen!")class son2(father):
def speak(self):
print("I can speak 2!")五、练熟基础:2048小游戏项目的实现与实战
上面为大家介绍的Python知识非常零散,但是也非常重要,既然想要掌握Python,就需要使用实际项目进行巩固和提升,当将项目实现之后,对应的能力也就自然掌握了。在视频分享中,韦玮老师与大家分享了Python编写的2048项目,详细的代码解析请参见视频分享(https://yq.aliyun.com/video/play/1359),项目代码下载点击这里(https://yq.aliyun.com/download/2466)。
本专题系列文章
从能做什么到如何去做,一文带你快速掌握Python编程基础与实战如何快速掌握Python数据采集与网络爬虫技术
Python数据挖掘与机器学习技术入门实战
Python数据挖掘与机器学习,快速掌握聚类算法和关联分析
手把手教你写网站:Python WEB开发技术实战
本文由云栖志愿小组贾子甲整理,编辑百见