词向量表示
分类
❖ 离散表示
- One-hot representation, Bag Of Words Unigram语言模型
- N-gram词向量表示和语言模型
- Co-currence矩阵的行(列)向量作为词向量
❖ 分布式连续表示
- Co-currence矩阵的SVD降维的低维词向量表示
- Word2Vec: Continuous Bag of Words Model
- Word2Vec: Skip-Gram Model
优缺点
离散表示的问题:
1> 无法衡量词向量之间的关系
2> 词表维度随着语料库增长膨胀
3> n-gram词序列随语料库膨胀更快
4> 数据稀疏问题
I. 离散表示
1. one-hot表示
1)设立语料库
John likes to watch movies. Mary likes too.
John also likes to watch football games.
2)根据语料库构建的词典
{“John”: 1, “likes”: 2, “to”: 3, “watch”: 4, “movies”: 5, “also”: 6, “football”: 7, “games”: 8, “Mary”: 9, “too”: 10}
3) 把上面词典中词按照One-hot表示
John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
likes: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
…
…
too : [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
注意:
❖ 词典包含10个单词,每个单词有唯一索引
❖ 在词典中的顺序和在句子中的顺序没有关联
2. 词袋模型(Bag of Words)
1)文档的向量表示可以直接将各词的词向量表示加和
John likes to watch movies. Mary likes too. => [1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
John also likes to watch football games. => [1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
2)计算词权重 TF-IDF
Bi-gram和N-gram
词袋模型的问题:未考虑词的顺序
3. Co-currence共现矩阵的行(列)向量作为词向量
共现矩阵的目的
Word - Document 的共现矩阵主要用于发现主题(topic),用于
主题模型,如LSA (Latent Semantic Analysis)
共现矩阵存在的问题
• 向量维数随着词典大小线性增长
• 存储整个词典的空间消耗非常大
• 一些模型如文本分类模型会面临稀疏性问题
• 模型会欠稳定
解决方案
构造低维稠密向量作为词的分布式表示 (25~1000维)!
II. 分布式连续表示
分布式表示可以降低表达的复杂度,节省空间。

Co-currence矩阵的SVD降维的低维词向量表示
为了解决上面提到的共现矩阵维度太高的问题,最直接的想法就是通过SVD对共现矩阵向量进行降维。但它同样存在很多问题:
- 计算量随语料库和词典增长膨胀太快,对X(n,n)维 的矩阵,计算量O(n^3)。 而对大型的语料库, n-400K,语料库大小1~60B
token - 因为词库字典被定死了,难以为词典中新加入的词分配词向量
- 与其他深度学习模型框架差异大
Word2Vec: Continuous Bag of Words Model

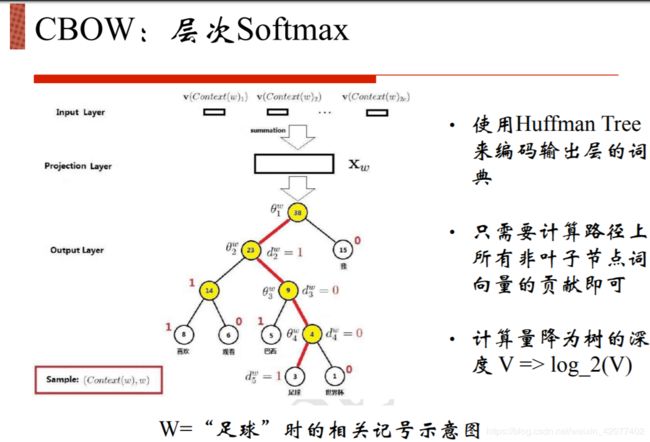

Word2Vec: Skip-Gram Model

word2vec的缺点
- 对每个local context window单独训练,没有利用包 含在global co-currence矩阵中的统计信息
- 对多义词无法很好的表示和处理,因为使用了唯一 的词向量
本文内容根据七月学堂课件内容整理而成