《复联4》影评抓取+词云+情感分析
复联4上映了!这次比美国还早了两天。很多人都去看了首映,各大媒体都被它刷屏。小编也是漫威迷,看了很多相关文章,觉得挺感兴趣的(文末有链接)因此也想搞搞事情,回顾一下从入门到放弃再到拾起的python,顺便蹭蹭热度。本文是比较简单入门级的操作,深入的以后有机会再写~
1.文本准备
使用beautifulsoup抓取豆瓣《复仇者联盟4》的影评(前20页)
目标url: https://movie.douban.com/subject/26100958/
代码如下:
import urllib.request
from bs4 import BeautifulSoup
def getHtml(url):
"""获取url页面"""
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
req = urllib.request.Request(url,headers=headers)
req = urllib.request.urlopen(req)
content = req.read().decode('utf-8')
return content
def getComment(url):
"""解析HTML页面"""
html = getHtml(url)
soupComment = BeautifulSoup(html, 'html.parser')
comments = soupComment.findAll('span', 'short')
onePageComments = []
for comment in comments:
# print(comment.getText()+'\n')
onePageComments.append(comment.getText()+'\n')
return onePageComments
if __name__ == '__main__':
f = open('复联4.txt', 'w', encoding='utf-8')
for page in range(10): # 豆瓣爬取多页评论需要验证。
url = 'https://movie.douban.com/subject/26100958/comments?status' + str(20*page) + '&limit=20&sort=new_score&status=P'
print('第%s页的评论:' % (page+1))
print(url + '\n')
for i in getComment(url):
f.write(i)
print(i)
print('\n')
with open('复联4.txt',encoding='utf-8') as f:
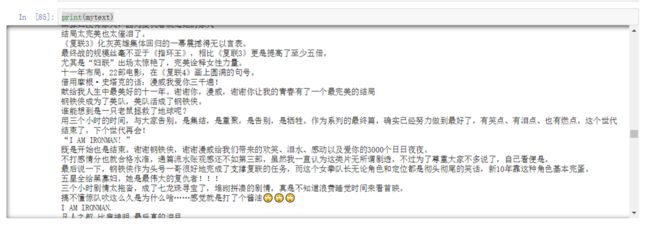
mytext = f.read()
print(mytext)
效果图:
2.制作词云
from wordcloud import WordCloud
wordcloud = WordCloud(font_path="simsun.ttf").generate(mytext) #注意中文词云需要换字体
%pylab inline
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off") #关闭坐标轴
效果图:

哈哈果然,这句致敬钢铁侠的“love you three thousands times”是最多人评论的~~小编也最爱钢铁侠,他最后把灭霸的手套抢过来的时候真是哭惨辽,预料之中但是还是好难过,他本可以不去执行任务,但为了更多家庭得到幸福,他选择了重出江湖,因为责任和使命。他一直有一颗温暖的心,抢过手套后那句“i am iron man”真是帅爆了。
3.自定义词云图片
import matplotlib.pyplot as plt #数学绘图库
from PIL import Image
import numpy as np #科学数值计算包,可用来存储和处理大型矩阵
import jieba #分词库
from wordcloud import WordCloud, ImageColorGenerator #词云库
#1、读入txt文本数据
text = open('复联4.txt',encoding='utf-8').read()
# 2、结巴分词:cut_all参数可选, True为全模式,False为精确模式,默认精确模式
cut_text= jieba.cut(text,cut_all=False)
result= "/".join(cut_text)#必须给个符号分隔开分词结果,否则不能绘制词云
#3、初始化自定义背景图片
image = Image.open('钢铁侠2.jpg')
graph = np.array(image)
#4、产生词云图
#自定义背景图:生成词云图由自定义背景图像素大小决定
wc = WordCloud(font_path="simsun.ttf",background_color='white',max_font_size=100,mask=graph)
wc.generate(result)
#5、绘制文字的颜色以背景图颜色为参考
image_color = ImageColorGenerator(graph)#从背景图片生成颜色值
wc.recolor(color_func=image_color)
wc.to_file(r"D:\好好学习天天向上\python\词云\demo-python-wordcloud-master\wordcloud.png") #按照背景图大小保存绘制好的词云图,比下面程序显示更清晰
# 6、显示图片
plt.figure("词云图") #指定所绘图名称
plt.imshow(wc) # 以图片的形式显示词云
plt.axis("off") # 关闭图像坐标系
plt.show()
原始图和词云图:

4.情感分析
SnowNLP是python中用来处理文本内容的,可以用来分词、标注、文本情感分析等,情感分析是简单的将文本分为两类,积极和消极,返回值为情绪的概率,越接近1为积极,接近0为消极。代码如下:
import numpy as np
from snownlp import SnowNLP
import matplotlib.pyplot as plt
f = open('复联4.txt', 'r', encoding='UTF-8')
list = f.readlines()
sentimentslist = []
for i in list:
s = SnowNLP(i)
# print s.sentiments
sentimentslist.append(s.sentiments)
plt.hist(sentimentslist, bins=np.arange(0, 1, 0.01), facecolor='g')
plt.xlabel('Sentiments Probability')
plt.ylabel('Quantity')
plt.title('Analysis of Sentiments')
plt.show()
效果图:
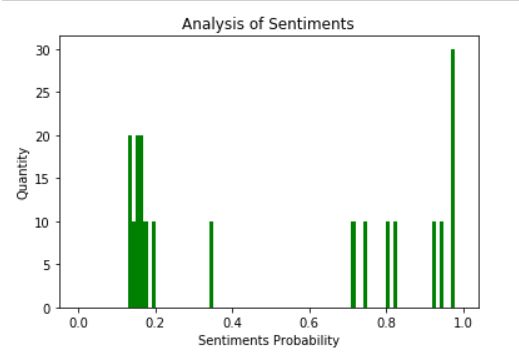
由图可直观地看出,这部电影抓取部分的影片喜忧参半,积极情绪、消极情绪呈了“u”型分布,小编猜测消极情绪大多是因为对漫威十年电影的感慨,对钢铁侠
美队、黑寡妇等人物的不舍,积极情绪应该大多是那句“爱你三千遍”拉高平均值的吧。只是猜测,具体问题具体分析~
小结:
anaconda环境安装
1.以前傻默认安在c盘,内存不足的时候误删了一些东西,导致anaconda不能正常使用,于是只能重新安装了。。没有安装的盆友,可以戳官网链接,安装路径记得更改呀~
词云:
1.安装(Windows):
需要在anaconda prompt进入anaconda安装包所在文件夹,如我的是 D:\Anaconda344\Scripts
再输入:
pip install wordcloud
Windows系统这样输入一般会报错,
解决办法:要去官网下载Ctrl+F搜索“wordcloud”找到对应版的.whl文件,版本要选对噢~
如:我的版本 64位window+python3.6,选择的是
wordcloud-1.3.3-cp36-cp36m-win_amd64.whl
因此正确做法,
下载对应的轮子(.whl文件),然后进入anaconda安装包所在文件夹,再输入:
pip install wordcloud-1.3.3-cp36-cp36m-win_amd64.whl
2.进入jupyter
(D:\Anaconda344) D:\好好学习天天向上\python\词云\demo-python-wordcloud-master>jupyter notebook
3.注意分析文本文件放在同一目录下,可以避免文件路径问题的麻烦.
4.中文词云制作需要jieba分词,作文本处理,进入对应安装包文件夹后,输入安装jieba的命令
pip install jieba
5…词云绘制工具wordcloud默认使用的字体是英文的,不包含中文编码,所以才会方框一片。
解决的办法,就是把下载的simsun.ttf,作为指定输出字体。
from wordcloud import WordCloud
wordcloud = WordCloud(font_path="simsun.ttf").generate(mytext) #注意中文词云需要换字体
%pylab inline
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
- 用matplotlib绘图有坐标轴,一下命令关闭坐标轴。
plt.axis("off") #关闭坐标轴
情感分析
环境安装命令:
pip install snownlp
pip install -U textblob
python -m textblob.download_corpora
你可能感兴趣:
- 英文词云参考教程
- 漫威开放api
- GitHub 上这几个漫威项目
- 从数据上看:谁才是漫威的绝对C位