基于NVIDIA GPUs的深度学习训练新优化
基于NVIDIA GPUs的深度学习训练新优化
New Optimizations To Accelerate Deep Learning Training on NVIDIA GPUs
不同行业采用人工智能的速度取决于最大化数据科学家的生产力。NVIDIA每月都会发布优化的NGC容器,为深度学习框架和库提高性能,帮助科学家最大限度地发挥潜力。英伟达持续投资于全数据科学堆栈,包括GPU架构、系统和软件堆栈。这一整体方法为深度学习模型训练提供了最佳性能,正如NVIDIA赢得了提交给MLPerf的所有六个基准,MLPerf是第一个全行业的人工智能基准所证明的那样。NVIDIA在最近几年引入了几代新的GPU架构,最终在Volta和Turing GPU上实现了Tensor核心架构,其中包括对混合精度计算的本地支持。NVIDIA在MXNet和PyTorch框架上完成了这些记录,展示了平台的多功能性。流行的深度学习框架中的自动混合精度通过向应用程序中添加一行或两行代码,在张量核心上提供3倍的更快的训练性能。在“自动混合精度”页上了解更多信息。
事实证明,NeurIPS 2018大会是深入学习科学家了解NVIDIA优化容器最近的一些重大性能改进的好时机,这些改进可以加速各种深度学习模型。让看看对NVIDIA GPU Cloud(NGC)deep learning framework容器和关键库的最新18.11版本的改进。新版本建立在早期的增强之上,可以在Volta Tensor Core GPU中阅读到,实现了新的AI性能里程碑。
Optimized Frameworks
MXNet
这一最新版本提高了大规模训练深度学习模型的性能,其中GPU训练性能在大批量范围内优化是至关重要的。如研究所示,在最终达到的训练精度开始下降之前,所有处理器的总训练批大小都存在限制。因此,当扩展到大量GPU时,一旦达到总的批大小限制,添加更多的GPU将减少每个GPU处理的批大小。因此,对18.11 NGC容器中的MXNet框架进行了一些改进,以优化各种训练批大小的性能,尤其是较小的,而不仅仅是较大的批大小:
随着批处理大小的减小,每次训练迭代与CPU同步的开销也随之增加。以前,MXNet框架在每次操作后都会将GPU与CPU同步。当使用每个GPU的小批量训练时,这种重复同步的开销会对性能产生不利影响。改进了MXNet,在与CPU同步之前将多个连续的GPU操作积极地组合在一起,减少了这一开销。
引入了新的融合运算符,如BatchNorm ReLU和BatchNorm Add ReLU,消除了不必要的GPU内存往返。这通过在执行批处理规范化的同一内核中执行简单的操作(例如elementwise Add或ReLU)来提高性能,而不需要额外的内存传输。这些特别适用于大多数现代卷积网络架构的图像任务。
以前,SGD优化器更新步骤是调用单独的内核来更新每个层的参数。新的18.11容器将多个层的SGD更新聚合到单个GPU内核中,以减少开销。当使用Horovod运行MXNet进行多GPU和多节点训练时,MXNet运行时会自动应用此优化。
NVIDIA通过对MXNet进行这些改进,实现了世界上最快的解决方案时间,ResNet50 v1.5的MLPerf为6.3分钟。
当使用18.11 MXNet容器在单个Tesla V100 GPU上使用Tensor Core混合精度训练批大小为32的ResNet-50时,这些优化使吞吐量达到1060个图像/秒,而使用18.09 MXNet容器时,吞吐量为660个图像/秒。
可以在这里找到最新的性能结果。
与Amazon和MXNet开发社区密切合作,集成了流行的Horovod通信库,以提高在大量gpu上运行时的性能。Horovod库使用NVIDIA集合通信库(NCCL),包含了处理分布式参数的allreduce方法。这就消除了本机MXNet分布式kvstore方法的性能瓶颈。
目前正在合并对上游MXNet和Horovod存储库的改进,以便用户社区能够从这些改进中受益。
TensorFlow
TensorFlow NGC容器包含最新版本的TensorFlow1.12。这为实验性XLA编译器实现的GPU性能提供了重大改进。谷歌在最近的博客中概述了XLA,包括如何启用说明。XLA通过将多个操作融合到一个GPU内核中,消除了对多个内存传输的需要,显著提高了性能,从而显著提高了速度。XLA编译器在这个时候是实验性的,在Google博客文章中概述了一些注意事项。然而,谷歌的内部模型与gpu相比,性能有望提高3倍。
此外,18.11 NGC Tensorflow容器集成了最新的TensorRT 5.0.2,使数据科学家能够轻松地部署训练模型和优化的推理性能。TensorRT解决了推理性能的具体挑战。高效地执行具有低延迟的小批量,直到批量大小为1。TensorRT 5.0.2支持低精度数据类型,如16位浮点或8位整数。
另一方面,NVIDIA为分析器提供了对CUDA应用程序性能的强大洞察。然而,虽然这些概要文件提供了大量关于应用程序低级性能的数据,但是对于TensorFlow用户来说,往往很难解释。这是因为概要文件不会将其输出与TensorFlow用户构建的原始图关联起来。增强了TensorFlow的图形执行器(使用NVIDIA profiler NVTX扩展)以将标记发送到用CUDA profiler(如nvprof)收集的配置文件中,简化了性能分析。
这些标记显示了每个图操作符所花费的时间范围,并且可以被高级用户用来轻松地识别计算内核及其相关的TensorFlow层。以前,概要文件只显示内核启动和主机/设备内存操作(运行时API行)。现在,TensorFlow将标记添加到概要文件中,并使用与TensorFlow图相关的有意义的名称,如图1所示。这允许用户将GPU执行概要文件事件映射到其模型图中的特定节点。
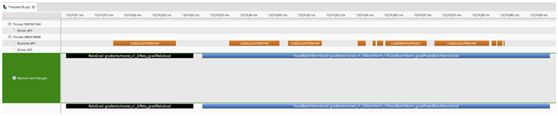
Figure 1. Screenshot of profiler showing annotated ranges for GPU operations
PyTorch
英伟达与Pythorch开发社区密切合作,不断提高在Volta Tensor Core GPU上训练深度学习模型的性能。Apex是Pythorch的一组轻量扩展,由NVIDIA维护以加速训练。目前正在对这些扩展进行评估,以便直接合并到主PyTorch存储库中。然而,PyTorch NGC容器是由Apex实用程序预先构建的,因此数据科学家和研究人员可以很容易地开始使用。在这个博客中了解更多关于Apex功能的信息。除了Apex最初附带的自动混合精度实用程序和分布式训练包装器之外,最近还添加了一些面向性能的实用程序。
首先,添加了一个新的Adam优化器的融合实现。现有的默认PyTorch实现需要多个进出GPU设备内存的冗余通道。这些冗余的传递会产生很大的开销,特别是在以数据并行方式跨多个gpu扩展训练时。Apex中的融合Adam优化器消除了这些冗余通道,提高了性能。例如,使用fused Apex实现的NVIDIA优化版变压器网络比PyTorch中的现有实现提供了5%到7%之间的端到端训练加速。对于谷歌神经机器翻译(GNMT)的优化版本,所观察到的端到端加速比从6%到高达45%(对于小批量大小)。
接下来,添加了层规范化的优化实现。对于相同的转换网络,Apex的层规范化在训练性能上提供了4%的端到端加速。
最后,扩展了分布式数据并行包装器,用于多GPU和多节点训练。这包括显著的引擎盖下性能调整,以及新的面向用户的选项,以提高性能和准确性。一个例子是“delay_allreduce”选项。此选项缓冲所有要在GPU上累积的层的所有渐变,然后在完成反向传递后将链接在一起。
虽然此选项忽略了将已计算梯度的通信与其模型层的梯度计算重叠的机会,但可以在使用持久内核实现(包括批处理规范化和某些cuDNN rnn)的情况下提高性能。“delay_allreduce”选项以及其面向用户的选项的详细信息可以在Apex文档中找到。
这些PyTorch优化使NVIDIA能够在MLPerf上提供多个速度记录,可以在这里阅读。
Performance Libraries
cuDNN
cuDNN 7.4.1的最新版本包含了NHWC数据布局、持久RNN数据梯度计算、跨步卷积激活梯度计算的显著性能改进,以及在CUDNNGETConvertion<*>(一组API)中改进的启发式。
提高Volta张量核性能的一个关键是减少训练模型时所需的张量换位次数,如前一篇博文所述。与张量核卷积的自然张量数据布局是NHWC布局。在cuDNN的最后几个版本中,还添加了高度优化的内核,这些内核对NHWC数据布局执行一系列内存绑定操作,如add tensor、op tensor、activation、average pooling和batch normalization。这些都在最新的cuDNN 7.4.1版本中提供。
这些新的实现使得更有效的内存访问成为可能,并且在许多典型的用例中可以达到接近峰值的内存带宽。此外,新的扩展批处理规范化API还支持可选的fused-element-wise-add激活,节省了多次往返全局内存,显著提高了性能。这些融合操作将加快训练具有批量规范化和跳过连接的网络。这包括大多数现代图像网络,用于分类、检测、分割等任务。
例如,与使用NCHW数据布局和不使用融合批规范化的情况相比,使用cuDNN的新NHWC和融合批规范化支持在DGX-1V上使用8台Tesla V100 GPU训练固态硬盘网络(使用ResNet-34主干网)时,性能提高了20%以上。
正如本博客前面所讨论的,大规模训练深层神经网络需要处理比每个GPU所能处理的最大批量更小的数据。这为优化提供了一个新的机会,特别是使用递归神经网络(RNNs)的模型。当批处理大小很小时,cuDNN库可以使用RNN实现,在某些情况下使用持久算法。 (这篇文章解释了RNN实现中持久算法的性能优势)虽然cuDNN在多个版本中支持持久RNN,但最近针对Tensor核心对进行了大量优化。图2中的图显示了一个性能改进的示例,对在TeslaV100上运行批处理大小为32的GNMTLanguage翻译模型所用的持久RNN进行了改进。如图所示,许多RNN调用的性能都有了显著的提高。
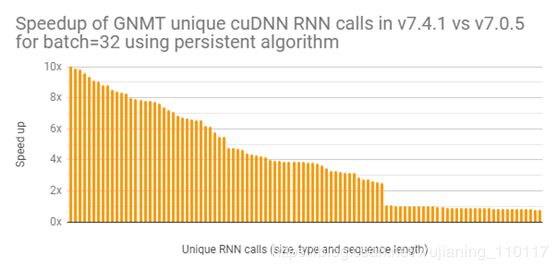
Figure 2. Speedup of GNMT unique cuDNN RNN calls in v7.4.1 vs. v7.0.5 for batch=32 using persistent algorithm
最新的cuDNN 7.4.1显著提高了计算激活梯度的性能。以前,单元增量的情况是由高度专业化和快速的内核处理的,而非单元增量的情况则退回到更通用但速度较慢的内核实现。最新的cuDNN解决了这一差距,并在非单位步幅情况下有很大的改进性能。通过这种增强,在诸如Deep Speech 2和Inception v3等网络中的相关激活梯度计算操作被改进了高达25倍。
DALI
视觉任务(如分类、目标检测、分割等)模型的训练和推理需要一个重要的、涉及的数据输入和扩充管道,当使用优化的代码大规模运行时,当多个gpu必须等待CPU时,该管道会很快成为整体性能的瓶颈准备数据。即使在使用多个CPU内核进行此处理时,CPU也很难为gpu提供足够快的数据。这会导致在等待CPU完成其任务时花费空闲GPU时间。将这些数据管道从CPU移动到GPU是有利的。DALI是一个开源的、与框架无关的GPU加速数据输入和扩充管道库,已经开发出来解决这个问题,将工作从CPU迁移到GPU。
让以流行的单点探测器(SSD)模型为例。数据输入管道有多个阶段,如图3所示。

Figure 3. DALI Data pipeline for SSD model
除了SSD Random(IoU-Intersection over Union-based)裁剪是SSD特定的之外,所有这些流水线阶段在计算机视觉任务中看起来都相当标准。DALI中新添加的操作符通过提供对COCO数据集(COCOReader)、基于IoU的裁剪(SSDRandomCrop)和边界框翻转(BbFlip)的访问,为整个工作流提供了一个基于GPU的快速管道。
Conclusion
研究人员可以利用讨论的最新性能增强,以最小的努力加速深度学习训练。访问NVIDIA GPU Cloud(NGC)下载经过充分优化的深度学习框架容器、经过预先训练的人工智能模型和模型脚本,让可以访问世界上性能最高的深度学习解决方案,从而启动人工智能研究。此外,在cuDNN和dali中还提供了单独的库和增强功能。