GAN的评价(一):An empirical study on evaluation metrics of generative adversarial networks
这篇paper的作者评价了各自度量GAN优劣性的指标,并给出了实际工程方面的经验。
现有GAN评价指标存在哪些问题?
- 评价指标本身好坏,缺乏一个评价体系
- 现有许多评价指标虽然和人的主观比较一致。可是与人的主观一致并不一定就代表GAN是好的。
现有的一些评价指标,比如Inception score和MMD等,虽然可以在一定程度上评价GAN。但是这些评价指标的适用场景却依然是一个疑问。换句话说,什么场景下,Inception score评价有效,什么时候Inception score会误导却未知。此外,如果一个GAN过拟合了,那么生成的样本会非常真实,人类主观评价得分会非常高,可是这并不是一个好的GAN。
这里也就引出了作者的目的了,那就是如何评价GAN的这些评价指标!
作者做了哪些工作?
作者通过进行大量实验,比较了现在example-based的评价方法。尝试回答了一下问题:
- 现有指标哪个会更加合理,科学?
- 现有指标的优缺点,应该首选哪些指标?
实际实验发现,MMD和1-NN two-sample test是最为合适的评价指标,这两个指标可以较好的区分:真实样本和生成的样本,mode dropping, mode collapsing。且计算高效。
什么是mode collapsing?
某个模式(mode)出现大量重复样本,例如:

上图左侧的蓝色五角星表示真实样本空间,黄色的是生成的。生成样本缺乏多样性,存在大量重复。比如上图右侧中,红框里面人物反复出现。
什么是mode dropping?
这个相对于好理解一下,顾名思义,某些模式(mode)没有,同样也缺乏多样性。例如下图中的人物,除了肤色变化,人物没有任何变化。

GAN的常见评价指标
符号对照
:生成数据分布,表示真实数据分布
:数学期望
:输入样本,表示为生成样本的采样,表示为真实样本的采样。
:样本标签
:分类网络,通常选择Inception network
现有的example-based(顾名思义,基于样本层面做评价。)方法,均是对生成样本与真实样本提取特征,然后在特征空间做距离度量。具体框架如下:
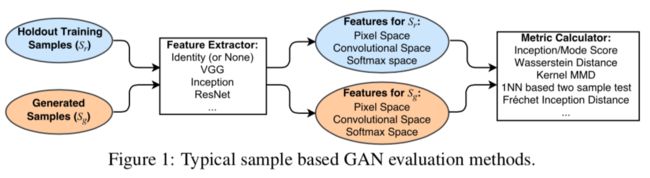
下面分别对常见的评价指标进行一一介绍:
Inception Score:
对于一个在ImageNet训练良好的GAN,其生成的样本丢给Inception网络进行测试的时候,得到的判别概率应该具有如下特性:
- 对于同一个类别的图片,其输出的概率分布应该趋向于一个脉冲分布。可以保证生成样本的准确性。
- 对于所有类别,其输出的概率分布应该趋向于一个均匀分布,这样才不会出现mode dropping等,可以保证生成样本的多样性。
因此,可以设计如下指标:
根据前面分析,如果是一个训练良好的GAN,趋近于脉冲分布,趋近于均匀分布。二者KL散度会很大。Inception Score自然就高。实际实验表明,Inception Score和人的主观判别趋向一致。IS的计算没有用到真实数据,具体值取决于模型M的选择
特点:可以一定程度上衡量生成样本的多样性和准确性,但是无法检测过拟合。Mode Score也是如此。不推荐在和ImageNet数据集差别比较大的数据上使用。
Mode Score:
Mode Score作为Inception Score的改进版本,添加了关于生成样本和真实样本预测的概率分布相似性度量一项。具体公式如下:
Kernel MMD (Maximum Mean Discrepancy)
计算公式如下:
对于Kernel MMD值的计算,首先需要选择一个核函数,这个核函数把样本映射到再生希尔伯特空间(Reproducing Kernel Hilbert Space, RKHS) ,RKHS相比于欧几里得空间有许多优点,对于函数内积的计算是完备的。将上述公式展开即可得到下面的计算公式:
MMD值越小,两个分布越接近。
特点:可以一定程度上衡量模型生成图像的优劣性,计算代价小。推荐使用。
Wasserstein distance
Wasserstein distance在最优传输问题中通常也叫做推土机距离。这个距离的介绍在WGAN中有详细讨论。公式如下:
Wasserstein distance可以衡量两个分布之间的相似性。距离越小,分布越相似。
特点:如果特征空间选择合适,会有一定的效果。但是计算复杂度为太高
Fréchet Inception Distance (FID)
FID距离计算真实样本,生成样本在特征空间之间的距离。首先利用Inception网络来提取特征,然后使用高斯模型对特征空间进行建模。根据高斯模型的均值和协方差来进行距离计算。具体公式如下:
分别代表协方差和均值。
特点:尽管只计算了特征空间的前两阶矩,但是鲁棒,且计算高效。
1-Nearest Neighbor classifier
使用留一法,结合1-NN分类器(别的也行)计算真实图片,生成图像的精度。如果二者接近,则精度接近50%,否则接近0%。对于GAN的评价问题,作者分别用正样本的分类精度,生成样本的分类精度去衡量生成样本的真实性,多样性。
- 对于真实样本,进行1-NN分类的时候,如果生成的样本越真实。则真实样本空间将被生成的样本包围。那么的精度会很低。
- 对于生成的样本,进行1-NN分类的时候,如果生成的样本多样性不足。由于生成的样本聚在几个mode,则很容易就和区分,导致精度会很高。
特点:理想的度量指标,且可以检测过拟合。
其他评价方法
AIS,KDE方法也可以用于评价GAN,但这些方法不是model agnostic metrics。也就是说,这些评价指标的计算无法只利用:生成的样本,真实样本来计算。
实验
实验部分进行了详细对比。此处不表。
值得注意的是,上述指标对于特征空间的选择尤其重要,特征空间选择不当,可能得出相反的结果。