综合评价与决策方法(待补全)
文章目录
- 综合评价与决策方法
- 理想解法
- 定义及有关概念
- TOPSIS法的算法步骤
- 实例及解题步骤
- MATLAB伪代码
- 数据包络分析(DEA)
- 定义及有关概念
- C 2 R C^2R C2R模型
- C 2 R C^2R C2R的MATLAB伪代码
- 灰色关联分析法
- 定义及有关概念
- 具体步骤
- MATLAB伪代码
- 主成分分析法(Principal Component Analysis,PCA)
- 定义及有关概念
- 基本步骤
- MATLAB伪代码
- 层次分析法(Analytic Hierarchy Process)
- 定义及有关概念
- 基本步骤
- MATLAB伪代码
综合评价与决策方法
理想解法
定义及有关概念
多属性决策问题的理想解法,亦称TOPSIS法,即各指标的最优解和最劣解。
多属性决策方案集 D D D={ d 1 , d 2 , . . . , d m d_1,d_2,...,d_m d1,d2,...,dm}
衡量方案优劣的属性变量为 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn
属性值类型包括效益型,成本型,区间型等。效益型属性值越大越好,成本型属性值越小越好,区间型属性值在某个区间最佳。
方案集里的每一方案 d i d_i di的n个属性值构成向量为 [ a i 1 , a i 2 , . . . , a i n ] [a_{i1},a_{i2},...,a_{in}] [ai1,ai2,...,ain],是n维空间的一个点,可以唯一表征方案 d i d_i di
正理想解 C ∗ C^* C∗是方案集里不存在的虚拟最佳方案,它的每个属性值都是决策矩阵中该属性的最优值
负理想解 C 0 C^0 C0是方案集里不存在的虚拟最差方案,它的每个属性值都是决策矩阵中该属性的最差值
方案的优先序,在n维空间中,将方案 D D D中的备选方案 d i di di与正理想解和负理想解的距离进行比较,既靠近正理想解又远离负理想解的方案就是最优方案
TOPSIS法的算法步骤
-
用向量规划化的方法求规范决策矩阵。设多属性决策问题的决策矩阵 A = ( a i j ) m × n A=(a_{ij})_{m\times{n}} A=(aij)m×n,规范化决策矩阵 B = ( b i j ) m × n , B=(b_{ij})_{m\times n}, B=(bij)m×n,其中
b i j = a i j / ∑ i = 1 m a i j 2 , i = 1 , 2 , . . . , m ; j = 1 , 2 , . . . , n 。 b_{ij}=a_{ij}/\sqrt{\sum_{i=1}^{m}a^2_{ij}},i=1,2,...,m;j=1,2,...,n。 bij=aij/i=1∑maij2,i=1,2,...,m;j=1,2,...,n。 -
构造加权规范阵 C = ( c i j ) m × n 。 C=(c_{ij})_m\times n。 C=(cij)m×n。设由决策人给定各属性的权重向量为 ω = [ ω 1 , ω 2 , . . . , ω n ] T , \omega=[\omega_1,\omega_2,...,\omega_n]^T, ω=[ω1,ω2,...,ωn]T,则
c i j = ω j ⋅ b i j , i = 1 , 2 , . . . , m ; j = 1 , 2 , . . . , n 。 c_{ij}=\omega_j\cdot b_{ij},i=1,2,...,m;j=1,2,...,n。 cij=ωj⋅bij,i=1,2,...,m;j=1,2,...,n。 -
确定正理想解和负理想解。设正理想解 C ∗ C^* C∗的第j个属性值为 c j ∗ c^*_j cj∗,负理想解 C 0 C^0 C0的第j个属性值为 c j 0 c^0_j cj0,
c j ∗ = { m a x c i j , j 为 效 益 型 属 性 m i n c i j , j 为 成 本 型 属 性 , j = 1 , 2 , . . . , n , c j 0 = { m i n c i j , j 为 效 益 型 属 性 m a x c i j , j 为 成 本 型 属 性 , j = 1 , 2 , . . . , n 。 c^*_j=\begin{cases}max &c_{ij},j为效益型属性\\ min &c_{ij},j为成本型属性\\ \end{cases} ,j=1,2,...,n,\\ c^0_j=\begin{cases}min&c_{ij},j为效益型属性\\ max&c_{ij},j为成本型属性 \end{cases} ,j=1,2,...,n。 cj∗={maxmincij,j为效益型属性cij,j为成本型属性,j=1,2,...,n,cj0={minmaxcij,j为效益型属性cij,j为成本型属性,j=1,2,...,n。 -
计算各方案到正负理想解的距离。
s i ∗ = ∑ j = 1 n ( c i j − c j ∗ ) 2 , i = 1 , 2 , . . . , m ; s i 0 = ∑ j = 1 n ( c i j − c j 0 ) 2 , i = 1 , 2 , . . . , m 。 s^*_i=\sqrt{\sum_{j=1}^n(c_{ij}-c_j^*)^2},i=1,2,...,m;\\ s^0_i=\sqrt{\sum_{j=1}^n(c_{ij}-c_j^0)^2},i=1,2,...,m。 si∗=j=1∑n(cij−cj∗)2,i=1,2,...,m;si0=j=1∑n(cij−cj0)2,i=1,2,...,m。 -
计算个方案的排序指标值(即综合评价指数),即
f i ∗ = s i 0 s i 0 + s i ∗ , i = 1 , 2 , . . . , m 。 f^*_i=\frac{s^0_i}{s^0_i+s^*_i},i=1,2,...,m。 fi∗=si0+si∗si0,i=1,2,...,m。 -
按 f i ∗ f^*_i fi∗由大到小排列方案的优劣次序
实例及解题步骤
一.属性值的规范化
规范化的目标:①使不同类型的属性值可以直接从数值大小判断优劣,方案越优,属性值越大。②非量纲化,即排除量纲的选用对决策或评估结果的影响③归一化,即将表中的数值变换到[0,1]区间上。
- 线性变换。设 a j m a x a_j^{max} ajmax是决策矩阵第j列最大值, a j m i n a_j^{min} ajmin是决策矩阵第j列最小值。则
b i j = { a i j / a j m a x , x i 为 效 益 型 属 性 , 1 − a i j / a j m a x , x i 为 效 益 型 属 性 。 b_{ij}=\begin{cases} a_{ij}/a_j^{max},x_i为效益型属性,\\ 1-a_{ij}/a_j^{max},x_i为效益型属性。 \end{cases} bij={aij/ajmax,xi为效益型属性,1−aij/ajmax,xi为效益型属性。
-
标准0-1变换。
b i j = { a i j − a j m i n a j m a x − a j m i n , x i 为 效 益 型 属 性 , a j m a x − a i j a j m a x − a j m i n , x i 为 效 益 型 属 性 。 b_{ij}=\begin{cases} \frac{a_{ij}-a_j^{min}}{a_j^{max}-a_j^{min}},x_i为效益型属性,\\ \frac{a_j^{max}-a_{ij}}{a_j^{max}-a_j^{min}},x_i为效益型属性。 \end{cases} bij=⎩⎨⎧ajmax−ajminaij−ajmin,xi为效益型属性,ajmax−ajminajmax−aij,xi为效益型属性。 -
区间型属性的变换。设定最优属性区间为[ a j 0 , a j ∗ a^0_j,a_j^* aj0,aj∗], a j ′ a_j^{'} aj′为违法容忍下限, a j ′ ′ a^{''}_j aj′′为无法容忍上限,则
b i j = { 1 − a j 0 − a i j a j 0 − a j ′ , a j ′ ⩽ a i j < a j 0 1 , a j 0 ⩽ a i j ⩽ a j ∗ 1 − a i j − a j ∗ a j ′ ′ − a j ∗ , a j ∗ < a i j ⩽ a j ′ ′ 0 , 其 他 b_{ij}=\begin{cases} 1-\frac{a^0_j-a_{ij}}{a_j^0-a_j^{'}},a^{'}_j\leqslant a_{ij}< a^0_j\\ 1,a^{0}_j\leqslant a_{ij}\leqslant a^*_j\\ 1-\frac{a_{ij}-a^*_j}{a_j^{''}-a_j^{*}},a^*_j< a_{ij}\leqslant a_j^{''}\\ 0,其他 \end{cases} bij=⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧1−aj0−aj′aj0−aij,aj′⩽aij<aj01,aj0⩽aij⩽aj∗1−aj′′−aj∗aij−aj∗,aj∗<aij⩽aj′′0,其他 -
向量规范化。无论成本型还是效益型属性,向量规范化均用下式进行变换:
b i j = a i j / ∑ i = 1 m a i j 2 , i = 1 , 2 , . . . , m ; j = 1 , 2 , . . . , n 。 b_{ij}=a_{ij}/\sqrt{\sum_{i=1}^{m}a^2_{ij}},i=1,2,...,m;j=1,2,...,n。 bij=aij/i=1∑maij2,i=1,2,...,m;j=1,2,...,n。
变换后属性值的大小无法辨别属性值的优劣,常用于计算各方案与某种虚拟方案的欧几里得距离 -
标准化处理。消除变量的量纲效应
b i j = a i j − a ‾ j s j , i = 1 , 2 , . . . , m , j = 1 , 2 , . . . , n , b_{ij}=\frac{a_{ij}-\overline{a}_j}{s_j},i=1,2,...,m,j=1,2,...,n, bij=sjaij−aj,i=1,2,...,m,j=1,2,...,n,
式中: a ‾ j = 1 m ∑ i = 1 m a i j , s j = 1 m − 1 ∑ i = 1 m ( a i j − a ‾ j ) 2 , j = 1 , 2 , . . . , n 。 \overline{a}_j=\frac{1}{m}\sum_{i=1}^{m}a_{ij},s_j=\sqrt{\frac{1}{m-1}\sum_{i=1}^{m}(a_{ij}-\overline{a}_j)^2},j=1,2,...,n。 aj=m1∑i=1maij,sj=m−11∑i=1m(aij−aj)2,j=1,2,...,n。
二.设权重向量,求加权的向量规范化矩阵
c i j = ω j ⋅ b i j , i = 1 , 2 , . . . , m ; j = 1 , 2 , . . . , n 。 c_{ij}=\omega_j\cdot b_{ij},i=1,2,...,m;j=1,2,...,n。 cij=ωj⋅bij,i=1,2,...,m;j=1,2,...,n。
三.求正负理想解
四.求各方案到正负理想解的距离
五.计算排序指标值
MATLAB伪代码
clc,clear;
输入决策矩阵a;
[m,n]=size(a);
定义函数进行变换;
若有区间型属性,则定义qujian=[aj_0,aj_star],lb,ub;
对区间型属性进行变换;
for j=1:n
b(:,j)=a(:,j)/norm(a(:,j)); %向量规划化求规范化决策矩阵
end
输入权重w;
c=b.*repmat(w,m,1); %求加权矩阵
Cstar=max(c); %求正理想解,max可返回每列最大值
将成本型属性对应的Cstar元素用c对应列的最小值代替
C0=min(c); %求负理想解
将成本型属性对应的C0元素用c对应列的最大值代替
for i=1:m
Sstar(i)=norm(c(i,:)-Cstar); %求每一方案到正理想解的距离
s0(i)=norm(c(i,:)-c0); %求每一方案到负理想解的距离
end
Sstar,s0 %显示到正理想解和负理想解的距离
f=s0./(Sstar+s0);
[sf,ind]=sort(f,'descend');%sf为从大到小排序后的f,ind为排序后的序号即f(ind(1))=sf(1)
数据包络分析(DEA)
定义及有关概念
它是根据多项投入指标和多项产出指标,利用线性规划的方法,对具有可比性的同类型单位(也可称决策单元,DMU)进行相对有效性评价的一种数量分析方法。用于解决相对有效评价问题。
设有 n n n个DMU,每个DMU都有 m m m种投入和 s s s种产出,设 x i j ( i = 1 , . . . , m ; j = 1 , . . . , n ) x_{ij}(i=1,...,m;j=1,...,n) xij(i=1,...,m;j=1,...,n)表示第 j j j个DMU的第 i i i种投入量, y r j ( r = 1 , . . . , s ; j = 1 , … , n ) y_{rj}(r=1,...,s;j=1,\dots,n) yrj(r=1,...,s;j=1,…,n)表示第 j j j个DMU的第 r r r种产出量,
决策单元 j j j的投入向量 X j = ( x 1 j , x 2 j , . . . , x m j ) T X_j=(x_{1j},x_{2j},...,x_{mj})^T Xj=(x1j,x2j,...,xmj)T
决策单元 j j j的产出向量 Y j = ( y 1 j , y 2 j , . . . , y s j ) T Y_j=(y_{1j},y_{2j},...,y_{sj})^T Yj=(y1j,y2j,...,ysj)T
决策单元 j j j的投入权值向量 ν = ( v 1 , v 2 , . . . , v m ) T \nu=(v_{1},v_{2},...,v_{m})^T ν=(v1,v2,...,vm)T
决策单元 j j j的产出权值向量 u = ( u 1 , u 2 , . . . , u s ) T u=(u_{1},u_{2},...,u_{s})^T u=(u1,u2,...,us)T
决策单元 j j j的效率评价指数 h j = u T Y j ν T X j , j = 1 , 2 , . . . , n 。 h_j=\frac{u^TY_j}{\nu^TX_j},j=1,2,...,n。 hj=νTXjuTYj,j=1,2,...,n。
C 2 R C^2R C2R模型
评价决策单元 j 0 j_0 j0效率的数学模型为
m a x u T Y j 0 ν T X j 0 , s . t . { u T Y j 0 ν T X j 0 ⩽ 1 , j = 1 , 2 , . . . , n , u ⩾ 0 , ν ⩾ 0 , u ≠ 0 , ν ≠ 0 。 max\frac{u^TY_{j0}}{\nu^TX_{j0}},\\ s.t.\begin{cases} \frac{u^TY_{j0}}{\nu^TX_{j0}}\leqslant1,j=1,2,...,n,\\ u \geqslant0,\nu \geqslant0,u \neq0,\nu \neq0。 \end{cases} maxνTXj0uTYj0,s.t.{νTXj0uTYj0⩽1,j=1,2,...,n,u⩾0,ν⩾0,u=0,ν=0。
通过Charnes-Cooper变换: ω = t ν , μ = t u , t = 1 ν T X j 0 , \omega=t\nu,\mu=tu,t=\frac{1}{\nu^TX_{j0}}, ω=tν,μ=tu,t=νTXj01,可以将上述模型转化为等价的线性规划问题
m a x V j 0 = μ T Y j 0 , s . t . { ω T X j − μ T Y j ⩾ 0 , j = 1 , 2 , . . . , n , ω T X j 0 = 1 , ω ⩾ 0 , μ ⩾ 0 。 − − − − ( 16 ) max V_{j0}=\mu^TY_{j0},\\ s.t.\begin{cases} \omega^TX_j-\mu^TY_j\geqslant0,j=1,2,...,n,\\ \omega^TX_{j0}=1,\\ \omega\geqslant0,\mu\geqslant0。 \end{cases}----(16) maxVj0=μTYj0,s.t.⎩⎪⎨⎪⎧ωTXj−μTYj⩾0,j=1,2,...,n,ωTXj0=1,ω⩾0,μ⩾0。−−−−(16)
写出上述模型的对偶形式:
m i n θ , s . t . { ∑ j = 1 n λ j X j ⩽ θ X j 0 , ∑ j = 1 n λ j Y j ⩾ Y j 0 , λ j ⩾ 0 , j = 1 , 2 , . . . , n 。 min\ \theta,\\ s.t.\begin{cases} \sum_{j=1}^{n}\lambda_jX_j\leqslant\theta X_{j0},\\ \sum_{j=1}^{n}\lambda_jY_j\geqslant Y_{j0},\\ \lambda_j\geqslant0,j=1,2,...,n。 \end{cases} min θ,s.t.⎩⎪⎨⎪⎧∑j=1nλjXj⩽θXj0,∑j=1nλjYj⩾Yj0,λj⩾0,j=1,2,...,n。
对于 C 2 R C^2R C2R模型(16),有如下定义:
若线性规划问题(16)的最优化目标值 V j 0 = 1 V_{j0}=1 Vj0=1,则称决策单元 j 0 j_0 j0是弱DEA有效的。
若线性规划问题(16)存在最优解 ω ∗ > 0 , μ ∗ > 0 , \omega^*>0,\mu^*>0, ω∗>0,μ∗>0,并且其最优目标值 V j 0 = 1 V_{j0}=1 Vj0=1,则称决策单元 j 0 j_0 j0是DEA有效的。
注意:在此模型下w = x = [ ω T , μ T ] =x=[\omega^T,\mu^T] =x=[ωT,μT],即权重w为线性规划的向量, f = [ z e r o s ( 1 , m ) , − Y ( : , i ) ′ ] f=[zeros(1,m),-Y(:,i)'] f=[zeros(1,m),−Y(:,i)′](实测出现了f不论是行向量还是列向量都返回同样的w的情况)。
C 2 R C^2R C2R的MATLAB伪代码
输入投入向量X;
输入产出向量Y;
n=size(X',1);
m=size(X,1);
s=size(Y,1);
A=[-X' Y'];
b=zeros(n,1);
LB=zeros(m+s,1);
UB=[];
for i=1:n
f=[zeros(1,m),-Y(:,i)'];
Aeq=[X(:,i)' zeros(1,s)];
beq=1;
w(:,i)=linprog(f,A,b,Aeq,beq,LB,UB);
E(1,i)=Y(:,i)'*w(m+1:m+s,i);%求DMU的相对效率值
end
灰色关联分析法
定义及有关概念
灰色关联分析法,是根据因素之间发展趋势的相似或相异程度,作为衡量因素间关联程度的一种方法。
关联度是对于两个系统之间的因素,其随时间或不同对象而变化的关联性大小的量度。在系统发展过程中,若两个因素变化的趋势具有一致性,即同步变化程度较高,即可谓二者关联程度较高;反之,则较低。
==比较对象(评价对象)==可理解为DEA中的决策单元。
==参考数列(评价标准)==类似于TOPSIS中的理想解,指标标准化后参考数列就是由每个指标的最大值构成的向量。
具体步骤
-
确定参考数列和比较数列,设评价对象有 m m m个,指标有 n n n个。比较数列是输入矩阵的每一列,记为 x i x_i xi。参考数列记为 x 0 x_0 x0。
x i = { x i ( k ) ∣ k = 1 , 2 , . . . , n } , i = 1 , 2 , . . . , m 。 x 0 = { x 0 ( k ) ∣ k = 1 , 2 , . . . , n } x_i=\{x_i(k)|k=1,2,...,n\},i=1,2,...,m。x_0=\{x_0(k)|k=1,2,...,n\} xi={xi(k)∣k=1,2,...,n},i=1,2,...,m。x0={x0(k)∣k=1,2,...,n} -
对输入矩阵进行规范化处理。过程参考TOPSIS。
-
确定各指标值对应的权重。可用层次分析法等确定,记为w = [ w 1 , w 2 , . . . , w n ] =[w_1,w_2,...,w_n] =[w1,w2,...,wn]。
-
计算灰色关联系数:
ξ i ( k ) = m i n m i n ∣ x 0 ( t ) − x s ( t ) ∣ + ρ m a x m a x ∣ x 0 ( t ) − x s ( t ) ∣ ∣ x 0 ( k ) − x i ( k ) ∣ + ρ m a x m a x ∣ x 0 ( t ) − x s ( t ) ∣ \xi_i(k)=\frac{min\ min|x_0(t)-x_s(t)|+\rho max\ max|x_0(t)-x_s(t)|}{|x_0(k)-x_i(k)|+\rho max\ max|x_0(t)-x_s(t)|} ξi(k)=∣x0(k)−xi(k)∣+ρmax max∣x0(t)−xs(t)∣min min∣x0(t)−xs(t)∣+ρmax max∣x0(t)−xs(t)∣
为比较数列 x i x_i xi对参考数列 x 0 x_0 x0在第 k k k个指标上的关联系上,其中 ρ ∈ [ 0 , 1 ] \rho\in[0,1] ρ∈[0,1]为分辨系数。称 m i n m i n ∣ x 0 ( t ) − x s ( t ) ∣ , m a x m a x ∣ x 0 ( t ) − x s ( t ) ∣ min\ min|x_0(t)-x_s(t)|,max\ max|x_0(t)-x_s(t)| min min∣x0(t)−xs(t)∣,max max∣x0(t)−xs(t)∣分别为两级最小差及两级最大差。 -
计算灰色加权关联度:
r i = ∑ k = 1 n w i ξ i ( k ) , r_i=\sum_{k=1}^{n}w_i\xi_i(k), ri=k=1∑nwiξi(k),
式中 r i r_i ri为第 i i i个评价对象对理想对象的灰色加权关联度。 -
评价分析。根据灰色加权关联度的大小,对各评价对象进行排序。
MATLAB伪代码
输入参考数据矩阵;
for i=...%效益型指标标准化,此处采用标准0-1变换
a(i,:)=(a(i,:)-min(a(i,:)))/(max(a(i,:))-min(a(i,:)));
end
for i=...%成本型指标标准化,此处采用标准0-1变换
a(i,:)=(max(a(i,:))-a(i,:))/(max(a(i,:))-min(a(i,:)));
end
[m,n]=size(a);
cankao=max(a')';%求参考序列的值
t=repmat(cankao,[1,n])-a;%求参考序列与每一序列的差
mmin=min(min(t));%两级最小差
mmax=max(max(t));%两级最大差
给定分辨系数rho;
xishu=(mmin+rho*mmax)./(t+rho*mmax);
guanliandu=mean(xishu);%取等权重,计算关联度,mean函数求每一列的平均值
[gsort,ind]=sort(guanliandu,'descend');%按关联度从大到小排序
主成分分析法(Principal Component Analysis,PCA)
定义及有关概念
PCA是一种常用的数据分析方法,通过线性变换将原始数据变换为一组各维度线性无关的表示,常用于数据降为。它用几个不相关的综合变量来较全面的反应整个数据集,这些综合变量称为主成分,各主成分间线性无关。
基本步骤
假设样本数量为 n n n,指标数量为 m m m。
1.数据标准化。将各指标 a i j a_{ij} aij转换成标准化指标 a ~ i j \widetilde{a}_{ij} a ij,
a ~ i j = a i j − u j s j , i = 1 , 2 , . . . , n , j = 1 , 2 , . . . , m \tilde{a}_{ij}=\frac{a_{ij}-u_j}{s_j},i=1,2,...,n,j=1,2,...,m a~ij=sjaij−uj,i=1,2,...,n,j=1,2,...,m
式中: u j , s j u_j,s_j uj,sj为第 j j j个指标的样本均值个样本标准差。称 a ~ i j \tilde{a}_{ij} a~ij为对应的标准化指标变量。
2.计算相关系数矩阵 R = ( r i j ) 5 × 5 R=(r_{ij})_{5\times5} R=(rij)5×5,或者计算协方差矩阵,以计算系数阵为例。
r i j = ∑ k = 1 n a ~ k i ⋅ a k j ~ n − 1 , i , j = 1 , 2 , . . . , m r_{ij}=\frac{\sum_{k=1}^n\tilde a_{ki}\cdot\tilde{a_{kj}}}{n-1},i,j=1,2,...,m rij=n−1∑k=1na~ki⋅akj~,i,j=1,2,...,m
其中 r i j = r j i , r i i = 1 r_{ij}=r_{ji},r_{ii}=1 rij=rji,rii=1
3.计算特征值和特征向量,用特征值进行排序,用对应的特征向量生成 m m m个新的指标向量,假设根据特征值排好序的向量为 u j = [ u 1 j , u 2 j , . . . , u n j ] , j = 1 , 2 , . . . , m u_j=[u_{1j},u_{2j},...,u_{nj}],j=1,2,...,m uj=[u1j,u2j,...,unj],j=1,2,...,m。
y 1 = u 11 x ~ 1 + u 21 x ~ 2 + . . . + u m 1 x ~ m y 2 = u 12 x ~ 1 + u 22 x ~ 2 + . . . + u m 2 x ~ m ⋮ y m = u 1 m x ~ 1 + u 2 m x ~ 2 + . . . + u m m x ~ m y_1=u_{11}\tilde x_{1}+u_{21}\tilde x_{2}+...+u_{m1}\tilde x_{m}\\ y_2=u_{12}\tilde x_{1}+u_{22}\tilde x_{2}+...+u_{m2}\tilde x_{m}\\ \vdots\\ y_m=u_{1m}\tilde x_{1}+u_{2m}\tilde x_{2}+...+u_{mm}\tilde x_{m} y1=u11x~1+u21x~2+...+um1x~my2=u12x~1+u22x~2+...+um2x~m⋮ym=u1mx~1+u2mx~2+...+ummx~m
4.选取 p ( p ≤ m ) p(p\leq m) p(p≤m)个主成分,计算综合评价值
- 计算某一特征值(主成分)和前 p p p个特征值(主成分)的信息贡献率,记为 b , α p b,\alpha_p b,αp。
b j = λ j ∑ k = 1 m λ k , j = 1 , 2 , . . . , m α p = ∑ k = 1 p λ k ∑ k = 1 m λ k b_j=\frac{\lambda_j}{\sum_{k=1}^m\lambda_k},j=1,2,...,m\\\alpha_p=\frac{\sum_{k=1}^p\lambda_k}{\sum_{k=1}^m\lambda_k} bj=∑k=1mλkλj,j=1,2,...,mαp=∑k=1mλk∑k=1pλk
- 计算综合得分
Z = ∑ i = 1 p b j y j Z=\sum_{i=1}^pb_jy_j Z=i=1∑pbjyj
MATLAB伪代码
clc,clear;
a=load('data.txt');
a=zscore(a);%数据标准化
r=corrcoef(a);
[x,y,b]=pcacov(r);%x是特征向量所构成的矩阵,y是特征值,b为各个主成分的贡献率
f=repmat(sign(sum(x)),size(x,1),1); %构造与x同维数的元素为±1的矩阵,sign函数返回-1或+1取决于自变量是否大于0
x=f.*x;
num=p;%num为选取的主成分的个数
score=a*x(:,[1:num])/100; %计算各个主成分的得分
z=score*b(1:num); %计算综合得分
[sz,ind]=sort(z,'descend'); %把得分按照从高到低的次序排列
sz=sz', ind=ind'
层次分析法(Analytic Hierarchy Process)
定义及有关概念
这种方法的特点就是在对复杂决策问题的本质、影响因素及其内在关系等进行深入研究的基础上,利用较少的定量信息使决策的思维过程数学化,从而为多目标、多准则或无结构特性的复杂决策问题提供简便的决策方法。是对难以完全定量的复杂系统做出决策的模型和方法。
若矩阵 A = ( a i j ) n × n A=(a_{ij})_{n\times n} A=(aij)n×n满足 a i j > 0 且 a j i = 1 a i j ( i , j = 1 , 2 , . . . , n ) a_{ij}>0且a_{ji}=\frac{1}{a_{ij}}(i,j=1,2,...,n) aij>0且aji=aij1(i,j=1,2,...,n)称之为正互反矩阵。
满足 a i j a j k = a i k , ∀ i , j , k = 1 , 2 , . . . , n a_{ij}a_{jk}=a_{ik},\forall i,j,k=1,2,...,n aijajk=aik,∀i,j,k=1,2,...,n的正互反矩阵称为一致矩阵。
基本步骤
1.建立层次结构模型
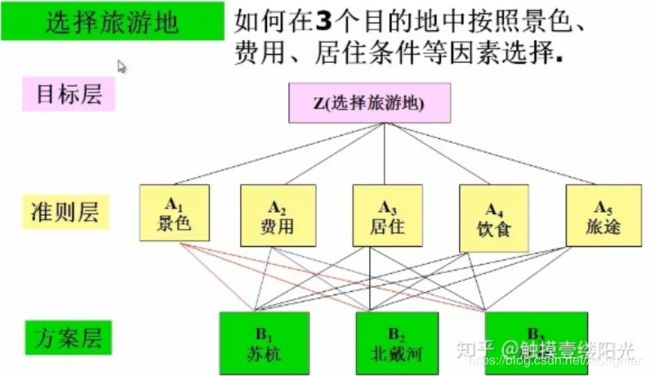
2.构造成对比较矩阵
比较矩阵的元素 a i j a_{ij} aij表示的是第 i i i个因素相对于第 j j j个因素的比较结果,这个值使用的是Santy的1-9标度方法给出

例如
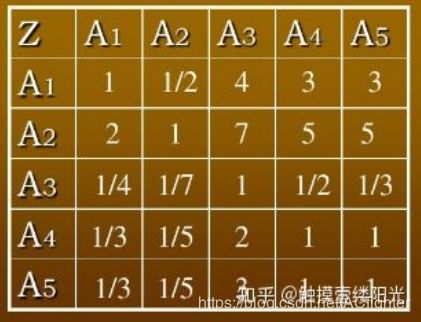
这个矩阵由建模者主观给出,通过求比较矩阵的最大特征值所对应的特征向量,就可以获得不同因素的权重,归一化一下(每个权重除以权重和作为自己的值,最终总和为1)就更便于使用了。
3.层次单排序和一致性检验
获得比较矩阵后可求其最大特征根 λ m a x \lambda_{max} λmax的特征向量,经归一化后记为 W W W,这一过程称为层次单排序。能否确认层次单排序,则需要进行一致性检验。定义一致性指标为: C I = λ − n n − 1 CI=\frac{\lambda-n}{n-1} CI=n−1λ−n,为衡量 C I CI CI的大小,引入随机一致性指标 R I = C I 1 + C I 2 + . . . + C I n n RI=\frac{CI_1+CI_2+...+CI_n}{n} RI=nCI1+CI2+...+CIn,但是似乎没有算的必要其取值可直接参照表格:
| 矩阵阶数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| R I RI RI | 0 | 0 | 0.58 | 0.90 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 | 1.49 |
引入检验系数 C R = C I R I CR=\frac{CI}{RI} CR=RICI,一般如果 C R < 0.1 CR<0.1 CR<0.1则认为通过一致性检验。
4.层次总排序及决策(方案层各方案对应准则进行互相比较)
注意,若给定数据中各个方案的准则层有可以量化的属性值,则此步骤可以不执行,运用单排序的权值进行TOPSIS就可以进行决策。
次级标题可能过与抽象,举个例子。现有三个候选人y1,y2,y3,要从中选一个总体上最适合的候选人,给定五个条件品德(x1),才能(x2),资历(x3),年龄(x4),群众关系(x5)。对此,对三个候选人y = y1,y2,y3分别比较。得到5个3$\times 3 的 矩 阵 3的矩阵 3的矩阵B_1,…,B_5$。
分别对 B 1 , . . . , B 5 B_1,...,B_5 B1,...,B5进行层次单排序和一致性检验可以获得5个3维向量 w 1 , . . . , w 5 w_1,...,w_5 w1,...,w5分别是三个候选人的某一项指标得分。总得分 s ( y i ) = ∑ j = 1 5 W ( j ) w j ( i ) s(y_i)=\sum_{j=1}^{5}W(j)w_j(i) s(yi)=∑j=15W(j)wj(i),最后只要进行排序就可以得到最佳方案,至此AHP结束。
MATLAB伪代码
clc,clear;
fid=fopen('shuju.txt','r');
n1=准则个数;n2=方案个数;
a=[];b=[];%初始化准则层比较矩阵a和方案层比较矩阵b
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%以下代码一定要一遍跑,或者写到m函数运行保存数据,读取
for i=1:n1
tmp=str2num(fgetl(fid));
a=[a;tmp];
end
for j=1:n2*n1
tmp=str2num(fgetl(fid));
b=[b;tmp];
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
ri=[0,0,0.58,0.90,1.12,1.24,1.32,1.41,1.45]; %一致性指标
[x,y]=eig(a);%求a的特征向量
lamda=max(diag(y));%求出最大特征值
num=find(diag(y)==lamda);
w0=x(:,num)/sum(x(:,num));%准则层权重
cr0=(lamda-n1)/(n1-1)/ri(n1)%小于0.1则采纳
for i=1:n1
t=b((i-1)*3+1:3*i,:);%中间矩阵即Bi
[x,y]=eig(t);
lamda=max(diag(y));
num=find(diag(y)==lamda);
w1(:,i)=x(:,num)/sum(x(:,num));%方案层权重
cr1(i)=(lamda-n2)/(n2-1)/ri(n2);
end
cr1%输出一致性比率
ts=w1*w0%输出各方案的分数
cr=cr1*w0%输出总体一致性比率