神经网络常用激活函数
神经网络常用激活函数
激活函数:激活函数在神经元中很重要,通常为了增强网络的表示能力和学习能力,激活函数需要具备的性质如下:
\qquad (1)连续可导(但也允许少数点上不可导)的非线性函数,其中,可导的激活函数可以直接利用数值优化的方法来学习网络参数。
\qquad (2)激活函数及其导函数要尽可能的简单,这样有利于提高网络的计算效率。
\qquad (3)激活函数的导函数值域要在一个合适的区间内,不能太大或者太小,否则会影响训练的效率和稳定性。
一、Sigmoid型函数
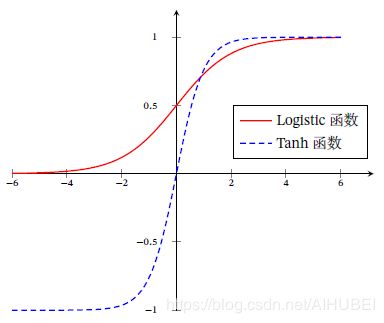
\qquad 实际上Sigmoid型函数指的是一类形状为 S 形 曲 线 S形曲线 S形曲线的函数,常用的Sigmoid型函数有Logistic函数以及双曲正切Tanh函数。Logistic函数的定义如下:
δ ( x ) = 1 1 + e x p ( − x ) (式1) \delta(x)=\cfrac{1}{1+exp(-x)}\tag{式1} δ(x)=1+exp(−x)1(式1)
这个Logistic函数可以看作是一个“挤压”函数,很明显它可以将输入的任意实数“挤压”或者“映射”到范围 ( 0 , 1 ) (0,1) (0,1)内。当输入 x x x为零,函数值为 1 2 \cfrac{1}{2} 21;当输入 x → + ∞ x\rightarrow{+\infty} x→+∞,函数值为 1 1 1;当输入 x → − ∞ x\rightarrow{-\infty} x→−∞,函数值为 0 0 0。
同时,Sigmoid函数的导数为:
δ ′ ( x ) = δ ( x ) ( 1 − δ ( x ) ) (式2) \delta^{'}{(x)}=\delta(x)(1-\delta(x))\tag{式2} δ′(x)=δ(x)(1−δ(x))(式2)
所以,对于函数 δ ( x ) \delta(x) δ(x),当 x → + ∞ x\rightarrow{+\infty} x→+∞时, δ ′ ( x ) → 0 \delta^{'}{(x)}\rightarrow{0} δ′(x)→0(右饱和),同时,当 x → − ∞ x\rightarrow{-\infty} x→−∞时, δ ′ ( x ) → 0 \delta^{'}{(x)}\rightarrow{0} δ′(x)→0(左饱和),同时满足左右饱和,因此logistic函数为饱和函数。
二、双曲正切函数
\qquad Tanh函数:双曲正切函数其实也是一种SIgmoid型的函数,定义如下:
t a n h ( x ) = e x p ( x ) − e x p ( − x ) e x p ( x ) + e x p ( − x ) (式3) tanh(x)=\cfrac{exp(x)-exp(-x)}{exp(x)+exp{(-x)}} \tag{式3} tanh(x)=exp(x)+exp(−x)exp(x)−exp(−x)(式3)
Tanh函数可以看作为放大且经过平移的Logistic函数,值域为 ( − 1 , 1 ) (-1,1) (−1,1)。因为 δ ( x ) \delta(x) δ(x)函数通过非线性组合可以得到下式:
t a n h ( x ) = 2 δ ( 2 x ) − 1 (式4) tanh(x)=2\delta{(2x)}-1\tag{式4} tanh(x)=2δ(2x)−1(式4)
如下如所示:Tanh函数的输出为零中心化的,但是Logistic函数的输出恒大于 0 0 0。带来的问题是:非零中心化的输出会导致当前位置后一层的神经元的输入发生偏置偏移,同时也会造成梯度下降的收敛速度变慢。
三、Hard-Logistic函数和Hard-Tanh函数
Logistic 函数和Tanh 函数都是Sigmoid 型函数,具有饱和性,但是计算开销较大. 因为这两个函数都是在中间(0 附近)近似线性,两端饱和. 因此,这两个函
数可以通过分段函数来近似.
\qquad (1)由 δ ′ ( x ) = δ ( x ) ( 1 − δ ( x ) ) \delta^{'}{(x)}=\delta(x)(1-\delta(x)) δ′(x)=δ(x)(1−δ(x)),得到Logistic函数在 0 0 0附近的一阶泰勒展开式为:
g z ( x ) ≈ δ ( 0 ) + δ ′ ( 0 ) ( x − 0 ) (式5) g_{z}(x)\approx\delta(0)+\delta^{'}{(0)}(x-0)\tag{式5} gz(x)≈δ(0)+δ′(0)(x−0)(式5)
= 0.25 x + 0.5 (式6) =0.25x+0.5\tag{式6} =0.25x+0.5(式6)
因此,Logistic函数可以近似为如下的hard-logistic分段函数:
h a r d − L o g i s t i c ( x ) = { 1 g z ( x ) ≥ 1 g z 0 < g z ( x ) < 1 0 g z ( x ) ≤ 0 (式7) hard-Logistic(x)= \begin{cases} 1\qquad{g_{z}(x)}\ge1\\ g_z\qquad{0
类似,Tanh函数在 0 0 0附近的一阶泰勒展开式为:
g t ( x ) ≈ t a n h ( 0 ) + t a n h ′ ( 0 ) x (式8) g_t{(x)}\approx{tanh(0)}+tanh^{'}(0)x\tag{式8} gt(x)≈tanh(0)+tanh′(0)x(式8)
= x (式9) =x\tag{式9} =x(式9)
因此,Tanh函数也可以用分段韩式hard-tanh(x)来表示为:
h a r d − t a n h ( x ) = m a x ( m i n ( g t ( x ) , 1 ) , − 1 ) = m a x ( m i n ( x , 1 ) , − 1 ) (式10) hard-tanh(x)= max(min(g_t(x),1),-1)= max(min(x,1),-1)\tag{式10} hard−tanh(x)=max(min(gt(x),1),−1)=max(min(x,1),−1)(式10)
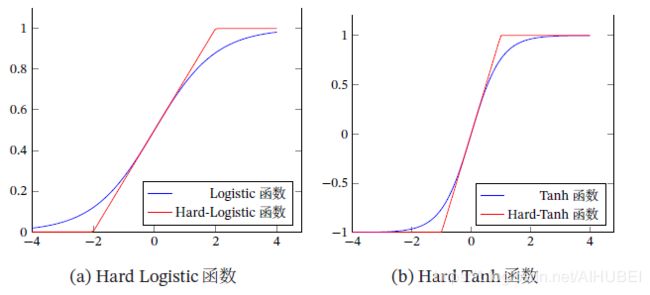
hard-Logistic函数和hard-tanh函数图像表示如下:
四、ReLU函数
\qquad ReLU函数也叫做Rectifier函数,为目前深度神经网络中经常使用的激活函数,表达式如下:
R e L U ( x ) = { x x ≥ 0 0 x < 0 (式11) ReLU(x)= \begin{cases} x\qquad{x}\ge0\\ 0\qquad{x}<0 \end{cases} \tag{式11} ReLU(x)={xx≥00x<0(式11)
= m a x ( x , 0 ) (式12) =max(x,0)\tag{式12} =max(x,0)(式12)
优点如下:使用ReLU的神经元,只需要进行加、乘和比较的操作,计算上更加高效。Sigmoid型函数会导致一个非稀疏的神经网络,但ReLU函数却具有很好的稀疏性,大约 50 % 50\% 50%的神经元会处于激活状态。
在优化方面,相比于Sigmoid型函数的两端饱和性,ReLU函数为左饱和函数,而且在 x > 0 x>0 x>0时候的导数为 1 1 1,好处是在一定程度上缓解了神经网络的梯度消失问题,加速梯度下降的收敛速度。
缺点:ReLU函数的输出为非零中心化的,会给后一层的神经网络带来偏置偏移,从而影响梯度下降的效率。而且会发生死亡ReLU问题。
死亡ReLU问题
如果参数在一次不恰当的更新之后,第一个隐藏层中的某个ReLU神经元在所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度就永远会是 0 0 0,在以后的训练过程中永远不能被激活,这就是死亡ReLU问题,而且这种现象也会发生在其他的隐藏层。
4.1 带泄露的ReLU
带泄露的ReLU(Leaky ReLU),在输入 x < 0 x<0 x<0时,保持一个很小的梯度 λ \lambda λ,这样的好处是:当神经元非激活时,也能有一个非零的梯度以用来更新参数,从而避免永远不能被激活的为题,代泄露的ReLU定义如下:
L e a k y R e L U ( x ) = { x i f x > 0 r x i f x ≤ 0 (式13) LeakyReLU(x)= \begin{cases} x\qquad{if\quad{x>0}}\\ rx\qquad{if\quad{x\le0}} \end{cases} \tag{式13} LeakyReLU(x)={xifx>0rxifx≤0(式13)
= m a x ( 0 , x ) + r m i n ( 0 , x ) (式14) =max(0,x)+rmin(0,x)\tag{式14} =max(0,x)+rmin(0,x)(式14)
在这里, r r r为一个很小的常数,比如说 0.01 0.01 0.01,当 r < 1 r<1 r<1时,带泄露的ReLU也可以写为:
L e a k y R e L U ( x ) = m a x ( x , r x ) (式15) LeakyReLU(x)=max(x,rx)\tag{式15} LeakyReLU(x)=max(x,rx)(式15)
4.2 带参数的ReLU
带参数的ReLU(Parametric ReLU,PReLU)实际上式引入了一个可以学习的参数,不同的神经元可以由不同的参数,对于第 i i i个神经元,PReLU定义如下:
P R e L U i ( x ) = { x i f x > 0 r i x i f x ≤ 0 (式16) PReLU_i(x)= \begin{cases} x\qquad{if\quad{x>0}}\\ r_ix\qquad{if{\quad{x\le0}}} \end{cases}\tag{式16} PReLUi(x)={xifx>0rixifx≤0(式16)
= m a x ( 0 , x ) + r i m i n ( 0 , x ) (式17) =max(0,x)+r_imin(0,x)\tag{式17} =max(0,x)+rimin(0,x)(式17)
其中, r i r_i ri为 x ≤ 0 x\le0 x≤0时候的斜率,PReLU为非饱和函数,如果 r i = 0 r_i=0 ri=0,就退化为ReLU。如果, r i r_i ri是一个很小的常数,则PReLU可以看作是带泄露的ReLU。同时,PReLU可以允许不同神经元具有不同的参数,也可以一组神经元共享一个参数。
4.3 ELU函数
ELU(指数线性单元)是一个近似的零中心化的非线性函数函数,定义如下:
E L U ( x ) = { x i f x > 0 r ( e x p ( x ) − 1 ) i f x ≤ 0 (式18) ELU(x)= \begin{cases} x\qquad{if\quad{x>0}}\\ r(exp(x)-1)\qquad{if\quad{x\le0}} \end{cases}\tag{式18} ELU(x)={xifx>0r(exp(x)−1)ifx≤0(式18)
= m a x ( x , 0 ) + m i n ( 0 , r ( e x p ( x ) − 1 ) ) (式19) =max(x,0)+min(0,r(exp(x)-1))\tag{式19} =max(x,0)+min(0,r(exp(x)−1))(式19)
其中, r ≥ 0 r\ge{0} r≥0为一个超参数,决定 x ≤ 0 x\le{0} x≤0时候的饱和曲线,同时调整输出均值在 0 0 0附近。
4.4 Softplus函数
Softplus函数可以看作为Rectifier函数的平滑版本,定义为:
S o f t p l u s ( x ) = l o g ( 1 + e x p ( x ) ) (式20) Softplus(x)=log(1+exp(x))\tag{式20} Softplus(x)=log(1+exp(x))(式20)
很巧,SoftPlus函数的倒是正好是Logistic函数,Softplus函数虽然也具有单侧抑制,宽兴奋边界的特性,却没有稀疏激活性。
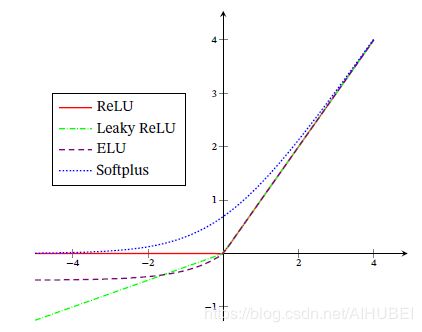
ReLU函数,LeakeyReLU函数,ELU以及Softplus函数的图像分别如下:
五、Swish函数
Swish函数作为一种自门控激活函数,定义如下:
s w i s h ( x ) = x δ ( β x ) (式21) swish(x)=x\delta(\beta{x})\tag{式21} swish(x)=xδ(βx)(式21)
其中, δ ( ⋅ ) \delta(\cdot) δ(⋅)为Logistic函数, β \beta β为可以学习的参数或者一个固定的超参数, δ ( x ) ∈ ( 0 , 1 ) \delta(x)\in(0,1) δ(x)∈(0,1)可以看作为一种软性的门控机制。当 δ ( β x ) \delta{(\beta{x})} δ(βx)接近 1 1 1,激活函数输出近似为 x x x;当 δ ( β x ) \delta(\beta{x}) δ(βx)接近 0 0 0,激活函数的输出近似为 0 0 0。
Swish函数图像如下:
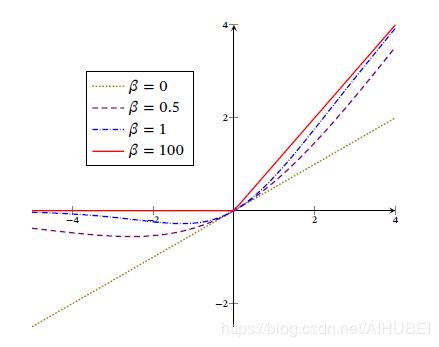
可见,Swish函数可以看作为线性函数和ReLU函数之间的非线性插值函数,其程度由参数 β \beta β控制。
六、高斯误差线性单元
高斯误差线性单元(GELU)和Swish函数比较类似,同样是一种通过门控机制来调整其输出值的激活函数,定义如下:
G E L U ( x ) = x P ( X ≤ x ) (式22) GELU(x)=xP(X\le{x})\tag{式22} GELU(x)=xP(X≤x)(式22)
其中, P ( X ≤ x ) P(X\le{x}) P(X≤x)是高斯分布 N ( μ , σ 2 ) \mathcal{N}(\mu,\sigma^2) N(μ,σ2)的累计分布函数,其中 μ , σ \mu,\sigma μ,σ是超参数,一般设置 μ = 0 , σ = 1 \mu=0,\sigma=1 μ=0,σ=1就可以了。由于高斯分布的累积分布函数为 S 型 S型 S型函数,故而可以使用Tanh函数或者Logistic函数来近似,
G E L U ( x ) ≈ 0.5 x ( 1 + t a n h 2 π ( x + 0.044715 x 3 ) ) (式23) GELU(x)\approx0.5x(1+tanh\sqrt{\cfrac{2}{\pi}}(x+0.044715x^3))\tag{式23} GELU(x)≈0.5x(1+tanhπ2(x+0.044715x3))(式23)
或者是
G E L U ( x ) ≈ x δ ( 1.702 x ) (式24) GELU(x)\approx{x}\delta(1.702x)\tag{式24} GELU(x)≈xδ(1.702x)(式24)
当使用Logistic函数来近似的时候,GELU相当于一种特殊的Swish函数。
七、Maxout单元
Maxout单元也是一种分段线性函数,Sigmoid型函数,ReLU等激活函数的输入是神经元的净输入 z z z,是一个标量。而Maxout单元的输入是上一层神经元的全部原始输出,是一个向量 x = [ x 1 ; x 2 ; ⋯ x D ] \boldsymbol{x}=[x_1;x_2;\cdots{x_{D}}] x=[x1;x2;⋯xD]。
每一个Maxout单元有 K K K个权重向量 w k ∈ R D \boldsymbol{w}_{k}\in{\mathbb{R}^{D}} wk∈RD和偏置 b k ( 1 ≤ k ≤ K ) b_k(1\le{k}\le{K}) bk(1≤k≤K),对于输入 x \boldsymbol{x} x,可以得到 K K K个净输入 z k , 1 ≤ k ≤ K z_{k},1\le{k}\le{K} zk,1≤k≤K.
z k = w k T x + b k (式25) z_{k}=\boldsymbol{w}_{k}^{T}\boldsymbol{x}+b_{k}\tag{式25} zk=wkTx+bk(式25)
其中, w k = [ w k , 1 , ⋯ , w k , D ] T \boldsymbol{w}_{k}=[w_{k,1},\cdots,w_{k,D}]^T wk=[wk,1,⋯,wk,D]T为第 k k k个权重向量。Maxout单元的非线性函数定义为:
m a x o u t ( x ) = max k ∈ [ 1 , K ] ( z k ) (式26) maxout(\boldsymbol{x})=\max\limits_{k\in[1,K]}(z_{k})\tag{式26} maxout(x)=k∈[1,K]max(zk)(式26)
八、常见激活函数及其导数
下图式常见激活函数及其导数:

到此,整理结束。