Kafka Java API
系统环境
Linux Ubuntu 16.04
jdk-7u75-linux-x64
kafka_2.10-0.8.2.2
zookeeper-3.4.5-cdh5.4.5
eclipse-java-juno-SR2-linux-gtk-x86_64
相关知识
1.Kafka提供了Producer类作为Java producer的api,该类有sync和async两种发送方式。默认是sync方式,即producer的调用类在消息真正发送到队列中去以后才返回。
(1)Kafka提供的java api中的Producer,底层只是维护该topic到每个broker的连接,并不是一个传统意义上的连接池。在使用sync方式时,我们应该自己实现一个连接池,里面包含若干Producer对象,以实现最大化写入效率。
(2)在写入的数据频率不高或要求获得写入结果时,应使用sync方式,否则会因async的等待时间引入额外的延迟。
(3)在写入的数据频率很高时,应使用async方式,以batch的形式写入,获得最大效率。
async方式与sync方式的不同在于,在初始化scala的producer时,会创建一个ProducerSendThread对象。然后,在调用send时,它并不是直接调用eventHandler.handle方法,而是把消息放入一个长度由queue.buffering.max.messages参数定义的队列(默认10000),当队列满足以下两种条件时,会由ProducerSendThread触发eventHandler.handle方法,把队列中的消息作为一个batch发送
①时间超过queue.buffering.max.ms定义的值,默认5000ms
②队列中当前消息个数超过batch.num.messages定义的值,默认200
2.Kafka的Consumer有两种Consumer的高层API、简单API–SimpleConsumer
(1)Consumer的高层API
主要是Consumer和ConsumerConnector,这里的Consumer是ConsumerConnector的静态工厂类
class Consumer {
public static kafka.javaapi.consumer.ConsumerConnector
createJavaConsumerConnector(config: ConsumerConfig);
}
具体的消息的消费都是在ConsumerConnector中
创建一个消息处理的流,包含所有的topic,并根据指定的Decoder
public Map>>createMessageStreams(Map topicCountMap, Decoder keyDecoder, Decoder valueDecoder);
创建一个消息处理的流,包含所有的topic,使用默认的Decoder
public Map>> createMessageStreams(Map topicCountMap);
获取指定消息的topic,并根据指定的Decoder
public List>>createMessageStreamsByFilter(TopicFilter topicFilter, int numStreams, Decoder keyDecoder, Decoder valueDecoder);
获取指定消息的topic,使用默认的Decoder
public List> createMessageStreamsByFilter(TopicFilter topicFilter);
提交偏移量到这个消费者连接的topic
public void commitOffsets();
关闭消费者
public void shutdown();
高层的API中比较常用的就是public List> createMessageStreamsByFilter(TopicFilter topicFilter);和public void commitOffsets();
(2)Consumer的简单API–SimpleConsumer
批量获取消息
public FetchResponse fetch(request: kafka.javaapi.FetchRequest);
获取topic的元信息
public kafka.javaapi.TopicMetadataResponse send(request:kafka.javaapi.TopicMetadataRequest);
获取目前可用的偏移量
public kafka.javaapi.OffsetResponse getOffsetsBefore(request: OffsetRequest);
关闭连接
public void close();
对于大部分应用来说,高层API就已经足够使用了,但是若是想做更进一步的控制的话,可以使用简单的API,例如消费者重启的情况下,希望得到最新的offset,就该使用SimpleConsumer。
任务内容
本实验是使用简单Java API来模拟Kafka的producer和consumer,其中producer是通过一个while循环生成内容,然后将内容传递给Kafka,consumer从Kafka中读取内容,并在Console界面中输出。
任务步骤
1.在/data目录下创建/kafka3文件夹。
mkdir /data/kafka3
2.在Linux中切换到/data/kafka3目录下,用wget命令从http://192.168.1.100:60000/allfiles/kafka3/kafkalib.tar.gz网址上下载文本文件kafkalib.tar.gz。
cd /data/kafka3
wget http://192.168.1.100:60000/allfiles/kafka3/kafkalib.tar.gz

3.下载完成后将压缩包解压到当前目录。
tar zxvf kafkalib.tar.gz

4.打开Eclipse,新建一个Java项目,命名为kafka3。

5.右键点击项目名,新建一个package,名为my.kafka。
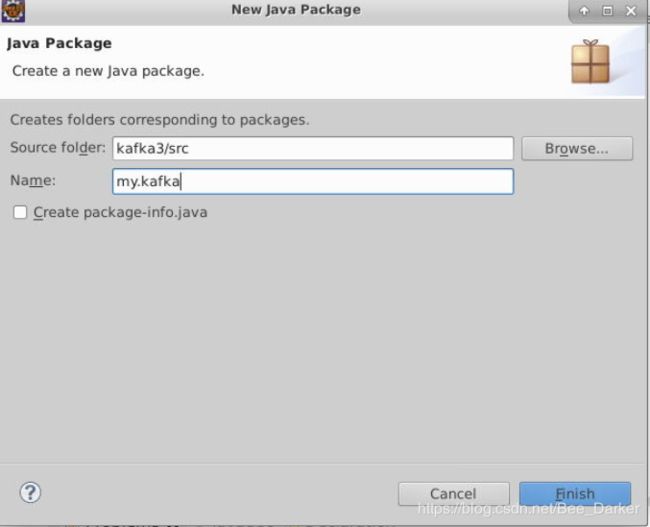
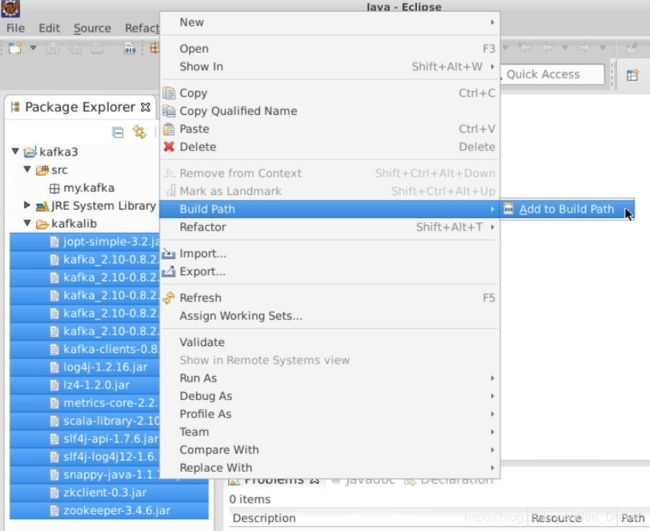
6.添加项目依赖的jar包。
右键项目,新建一个文件夹,命名为kafkalib,用于存放项目所需的jar包。

将/data/kafka3目录下kafkalib文件夹中的所有jar包,拷贝到Eclipse中kafka3项目下的kafkalib文件夹中,选中kafkalib文件夹中所有jar包,并添加到Build Path中。
7.启动ZooKeeper。切换到/apps/zookeeper/bin目录下,执行ZooKeeper的启动脚本。
cd /apps/zookeeper/bin
./zkServer.sh start

查看ZooKeeper的运行状态。
./zkServer.sh status

8.切换目录到/apps/kafka目录下,启动kafka的server。
cd /apps/kafka
bin/kafka-server-start.sh config/server.properties &
9.另起一窗口,切换到/apps/kafka下,在kafka中创建topic,命名为testkafkaapi。
cd /apps/kafka
bin/kafka-topics.sh \
--create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--topic testkafkaapi \
--partitions 1
查看topic
bin/kafka-topics.sh --list --zookeeper localhost:2181

10.创建kafka的producer,用于生产数据。在kafka3项目my.kafka包下,创建Class,命名为MyProducer,编写MyProducer类的代码。
package my.kafka;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class MyProducer {
private final Producer<String, String> producer;
public final static String TOPIC = "testkafkaapi";
public MyProducer() {
Properties props = new Properties();
// 此处配置的是kafka的端口
props.put("metadata.broker.list", "localhost:9092");
// 配置value的序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
// 配置key的序列化类
props.put("key.serializer.class", "kafka.serializer.StringEncoder");
// request.required.acks
// 0, which means that the producer never waits for an acknowledgement
// from the broker (the same behavior as 0.7). This option provides the
// lowest latency but the weakest durability guarantees (some data will
// be lost when a server fails).
// 1, which means that the producer gets an acknowledgement after the
// leader replica has received the data. This option provides better
// durability as the client waits until the server acknowledges the
// request as successful (only messages that were written to the
// now-dead leader but not yet replicated will be lost).
// -1, which means that the producer gets an acknowledgement after all
// in-sync replicas have received the data. This option provides the
// best durability, we guarantee that no messages will be lost as long
// as at least one in sync replica remains.
props.put("request.required.acks", "-1");
producer = new Producer<String, String>(new ProducerConfig(props));
}
void produce() {
int messageNo = 1000;
final int COUNT = 10000;
while (messageNo < COUNT) {
String key = String.valueOf(messageNo);
String data = "hello,kafka message:" + key;
producer.send(new KeyedMessage<String, String>(TOPIC, key, data));
System.out.println(data);
messageNo++;
}
}
public static void main(String[] args) {
new MyProducer().produce();
}
}
producer端的代码:首先定义一个topic的名称,然后创建一个properties实例,用来设置produce的参数。接着创建一个producer的实例并将参数配置props作为参数上传进去。在produce方法中定义一个key与data,创建KeyedMessage实例,并将key,data和topic作为参数上传进去,然后把KeyedMessage实例上传给producer。在主函数中直接调用MyProduce的produce()方法,用来实现消息的上传。
11.创建kafka的consumer。用于消费数据。在kafka3项目,my.kafka包下,创建Class,命名为MyConsumer,编写MyConsumer类的代码。
package my.kafka;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.serializer.StringDecoder;
import kafka.utils.VerifiableProperties;
public class MyConsumer {
private final ConsumerConnector consumer;
private MyConsumer() {
Properties props = new Properties();
//zookeeper 配置
props.put("zookeeper.connect", "localhost:2181");
//group 代表一个消费组
props.put("group.id", "mygroup");
//zk连接超时
props.put("zookeeper.session.timeout.ms", "4000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");
//序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
ConsumerConfig config = new ConsumerConfig(props);
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(config);
}
void consume() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(MyProducer.TOPIC, new Integer(1));
StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties());
Map<String, List<KafkaStream<String, String>>> consumerMap = consumer.createMessageStreams(topicCountMap,keyDecoder,valueDecoder);
KafkaStream<String, String> stream = consumerMap.get(MyProducer.TOPIC).get(0);
ConsumerIterator<String, String> it = stream.iterator();
while (it.hasNext())
System.out.println(it.next().message());
}
public static void main(String[] args) {
new MyConsumer().consume();
}
}
在MyConsumer端分为两部分:MyConsumer()方法和consume()方法。在MyConsumer()方法中创建properties实例在里面配置consumer的性能,然后创建一个接收消息的consumer实例并将properties实例作为参数传递进去。在cousume()方法中调用consumer类的createMessageStreams()方法用来接受从kafka中传递来的消息,然后通过迭代遍历将消息输出到控制台上。
12.执行程序
在Eclipse的MyProducer类中右键并点击==>Run As==>Jave Application选项。
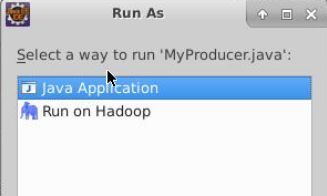
然后在MyConsumer类中:单击右键==>Run As==>Jave Application选项。

然后可以看到console界面的输出结果。
Consumer
