[关系图谱] 二.Gephi导入共线矩阵构建作者关系图谱
本文主要讲解Gephi绘制作者间的关系图谱,该软件可以广泛应用于社交网络、知识图谱分析,推荐读者使用。这是非常基础的一篇文章,重点讲解Gephi使用方法,希望对大家有所帮助。
推荐前文:
[python数据挖掘课程] 十七.社交网络Networkx库分析人物关系(初识篇)
[关系图谱] 一.Gephi通过共线矩阵构建知网作者关系图谱
PS:2019年1~2月作者参加了CSDN2018年博客评选,希望您能投出宝贵的一票。我是59号,Eastmount,杨秀璋。投票地址:https://bss.csdn.net/m/topic/blog_star2018/index

一.网络数据抓取
本文采用Python+Selenium抓取中国知网水族文献990篇,然后构建水族文献作者间的共现矩阵。其中爬虫核心代码如下,这里不再详细叙述。
# -*- coding: utf-8 -*-
import requests
import json
import time
import re
from datetime import datetime
import pandas as pd
from bs4 import BeautifulSoup
import sys,urllib,urllib2
import numpy as np
import random
import csv
import codecs
c = open("best-07-qikan.csv","wb") #创建文件
c.write(codecs.BOM_UTF8) #防止乱码
writer = csv.writer(c) #写入对象
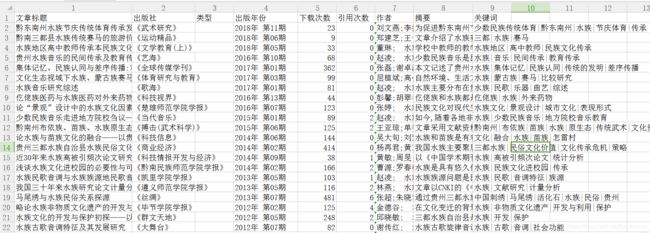
writer.writerow(['文章标题','出版社','类型','出版年份','下载次数','引用次数','作者','摘要','关键词'])
myheaders = {
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cache-Control":"max-age=0",
"Connection":"keep-alive",
"Cookie":'SID=201099; UM_distinctid=162000d85ad3b9-0d8861d0e80845-454f032b-144000-162000d85ae62; CNZZDATA1356416=cnzz_eid%3D1081444310-1520419105-http%253A%252F%252Fepub.cnki.net%252F%26ntime%3D1520419105; CNZZDATA3636877=cnzz_eid%3D1821403385-1520416905-http%253A%252F%252Fepub.cnki.net%252F%26ntime%3D1520416905; ASP.NET_SessionId=wvqxbf45i04xma55s30jse55',
"Host":"www.cnki.net",
"Referer":"http://search.cnki.net/search.aspx?q=python",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Mobile Safari/537.36"
}
#CNKI 3.0 列表信息抓取 搜索'水族 民族'关键词
keyword = u'水族 民族'
keyword = keyword.encode('utf-8')
i = 0
while i<2: #100
#学术期刊 CJFDTOTAL
start_url = 'http://search.cnki.net/Search.aspx?q={}&rank=relevant&cluster=zyk&val=CJFDTOTAL&p={}'.format(keyword,i*15)
print(start_url)
html = requests.get(start_url).text
#print html
#解析
soup = BeautifulSoup(html, "html.parser")
#定位论文摘要
wz_tab = soup.find_all("div",class_="wz_tab")
for j in range(0,len(wz_tab)):
print('******')
print("i={},j={}".format(i,j))
tab = wz_tab[j]
#文章标题
title = tab.h3.a.get_text().strip()
filename = re.search("filename=(.*?)&",tab.h3.a.attrs['href']).group(1)
dbname = re.search("dbname=(.*?)$",tab.h3.a.attrs['href']).group(1)
#摘要信息
abstract = tab.find(attrs={"class":"text"}).get_text()
print abstract
#print tab
print title
print filename
print dbname
#获取其他信息
other = tab.find(attrs={"class":"year-count"})
if other.span:
other_list = other.span.get_text().split(u'\xa0\xa0')
if len(other_list) == 3:
# 出版社
library = other_list[0]
# 等级
x_class = other_list[1]
# 出版年份
year = other_list[2]
elif len(other_list) == 2:
# 出版社
library = other_list[0]
# 等级
x_class = None
# 出版年份
year = other_list[1]
else:
library= None
x_class = None
year = None
print library
print x_class
print year
Num_list = other.find("span",class_="count").get_text().split('|')
# 下载
if re.search('[0-9]',Num_list[0]):
#print Num_list[0]
test = re.findall(r'\d+\.?\d*',Num_list[0], re.M)
#print test
load_num = int(test[0])
#print load_num, type(load_num)
else:
load_num = 0
#被引用次数
if re.search('[0-9]',Num_list[1]):
from_num = int(re.findall(r'\d+\.?\d*',Num_list[1], re.M)[0])
else:
from_num = 0
print load_num
print from_num
###################################
# 抓取摘要
time.sleep(1)
#http://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CJFQ&dbname=CJFD2011&filename=GZMZ201106003&v=MTM5MTBkdUZDcmhWYnZJSWpmR2RMRzRIOURNcVk5Rlo0UjhlWDFMdXhZUzdEaDFUM3FUcldNMUZyQ1VSTEtmYis=
url = "http://www.cnki.net/kcms/detail/detail.aspx?dbcode=CMFD&dbName={}&FileName={}&v=&uid=".format(dbname,filename)
print url
#html = requests.get(url).text
html = requests.get(url,headers = myheaders,timeout = 500)
print html.status_code
#抓取作者
bs4Obj = BeautifulSoup(html.text)
if bs4Obj.find("a",class_="KnowledgeNetLink"):
test = bs4Obj.find_all("a", class_="KnowledgeNetLink")
Author = ""
for n in test:
Author = Author + n.get_text().rstrip() + " "
else:
Author = None
#摘要
if bs4Obj.find("span",{"id":"ChDivSummary"}):
summury = bs4Obj.find("span",{"id":"ChDivSummary"}).get_text().rstrip()
else:
summury = None
# 关键词
if bs4Obj.find("span",{"id":"ChDivKeyWord"}):
keywords = bs4Obj.find("span",{"id":"ChDivKeyWord"})
#print keywords
keywords_list = '|'.join(list(map(lambda x:x.get_text(),keywords.find_all('a'))))
#print keywords_list
else:
keywords_list = None
print 'list no'
print '' #换行
templist = []
num1 = title.encode('utf-8') #否则写入文件报错
num2 = library.encode('utf-8')
if x_class is None:
num3 = ""
else:
num3 = x_class.encode('utf-8')
num4 = year.encode('utf-8')
num5 = str(load_num).encode('utf-8')
num6 = str(from_num).encode('utf-8')
num7 = Author.encode('utf-8')
if summury is None:
num8 = ""
else:
num8 = summury.encode('utf-8')
if keywords_list is None:
num9 = ""
else:
num9 = keywords_list.encode('utf-8')
templist.append(num1)
templist.append(num2)
templist.append(num3)
templist.append(num4)
templist.append(num5)
templist.append(num6)
templist.append(num7)
templist.append(num8)
templist.append(num9)
#print templist
writer.writerow(templist)
i = i + 1
c.close()
运行结果如下图所示:
二.共现矩阵
引文分析常见的包括两类,一种是共现关系,另一种是引用和被引用关系。本文主要讲解共现关系,假设现在存在三篇文章,如下所示:
文章标题 作者
大数据发展现状分析 A,B,C
Python网络爬虫 A,D,C
贵州省大数据战略 D,B
1.首先写代码抓取该领域文章的所有作者,即:A、B、C、D。
2.接着获取对应的共现矩阵,比如文章“大数据发展现状分析”,则认为A、B、C共现,在他们之间建立一条边。共现矩阵如下所示:
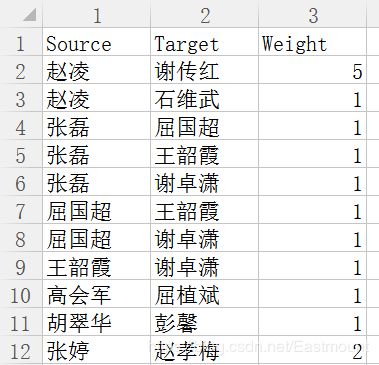
(1) [ − A B C D A 0 1 2 1 B 1 0 1 1 C 2 1 0 1 D 1 1 1 0 ] \left[ \begin{matrix} -& A & B & C & D \\ A & 0 & 1 & 2 & 1 \\ B & 1 & 0 & 1 & 1 \\ C & 2 & 1 & 0 & 1 \\ D & 1 & 1 & 1 & 0 \end{matrix} \right] \tag{1} ⎣⎢⎢⎢⎢⎡−ABCDA0121B1011C2101D1110⎦⎥⎥⎥⎥⎤(1)
3.通过共现矩阵分别获取两两关系及权重,再写入CSV或Excel文件中,如下所示。
(2) [ S o u r c e T a r g e t W e i g h t A B 1 A C 2 A D 1 B C 1 B D 1 C D 1 ] \left[ \begin{matrix} Source & Target & Weight \\ A & B & 1 \\ A & C & 2 \\ A & D & 1 \\ B & C & 1 \\ B & D & 1\\ C & D & 1 \end{matrix} \right] \tag{2} ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡SourceAAABBCTargetBCDCDDWeight121111⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤(2)
4.将该CSV文件导入Gephi中,并绘制相关的图形。因为该实例节点比较少,下面是Pyhton调用Networkx绘制的代码及图形。
# -*- coding: utf-8 -*-
import networkx as nx
import matplotlib.pyplot as plt
#定义有向图
DG = nx.Graph()
#添加五个节点(列表)
DG.add_nodes_from(['A', 'B', 'C', 'D'])
print DG.nodes()
#添加边(列表)
DG.add_edge('A', 'B', weight=1)
DG.add_edge('A', 'C', weight=2)
DG.add_edge('A', 'D', weight=1)
DG.add_edge('B', 'C', weight=1)
DG.add_edge('B', 'D', weight=1)
DG.add_edge('C', 'D', weight=1)
#DG.add_edges_from([('A', 'B'), ('A', 'C'), ('A', 'D'), ('B','C'),('B','D'),('C','D')])
print DG.edges()
#绘制图形 设置节点名显示\节点大小\节点颜色
colors = ['red', 'green', 'blue', 'yellow']
nx.draw(DG,with_labels=True, node_size=900, node_color = colors)
plt.show()
绘制图形如下所示:

由于我们的数据集比较多,故推荐大家使用Gephi软件绘制相关图形。
三.数据导入Gephi
1.数据集为“data.csv”文件,共包括1095条关系。
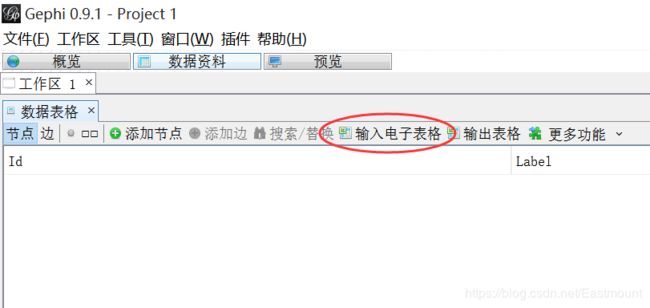
2.新建工程,并选择“数据资料”,输入电子表格。
3.然后导入数据如下图所示,设置为“边表格”,注意CSV表格数据一定设置为 Source(起始点)、Target(目标点)、Weight(权重),这个必须和Gephi格式一致,否则导入数据会提示错误。
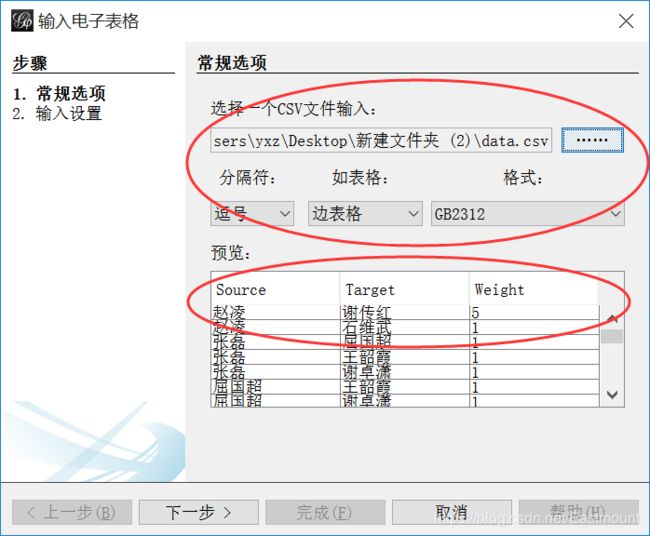
导入数据如下图所示,但此时导入的图形为 **“有向图” **,而且Gephi软件中没有设置为无向图的选项,那怎么办呢?
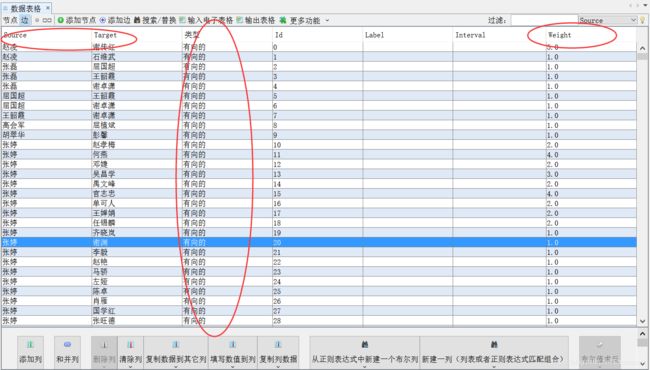
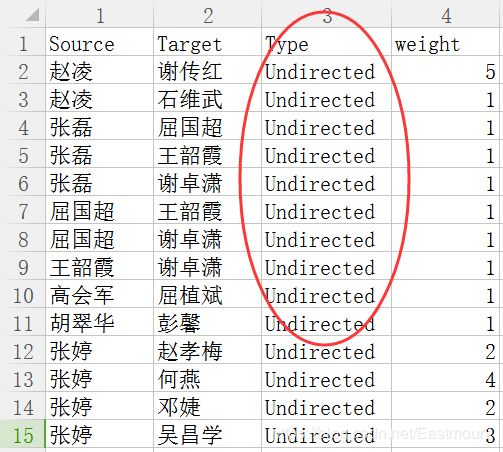
4.在 data.csv 文件中增加一列为 Type,其值均为Undirected,用Gephi重新导入一遍则可构建无向图。如果您需要设计的图为有向图,则忽略该步骤。
注意:如果您只按照“边表格”导入数据,则节点会因为没有 Label 值,最终呈现的图形会没有文字。如下图所示,所以接下来导入数据分为了两个步骤。

5.导入节点文件:Edges.csv,注意CSV文件中表头切记定位为 id、label。
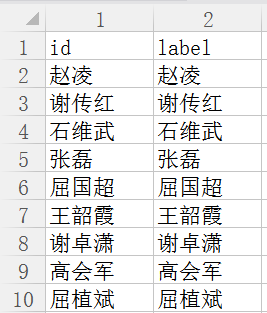

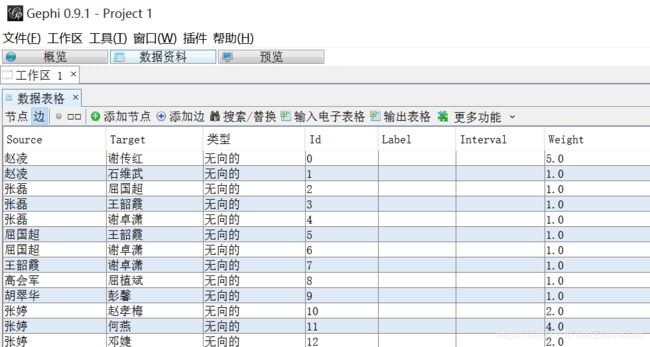
6.导入边文件:Edges.csv,注意CSV文件中表头切记为Source(起始点)、Target(目标点)、Weight(权重)、Tpye(无向边 Undirected)。

导入成功后如下图所示:

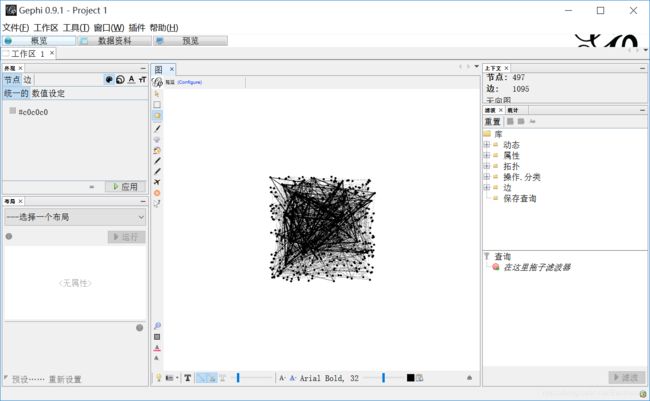
7.导入成功后点击“概览”显示如下所示,接着就是调整参数。
四.调整参数绘制关系图谱
设置外观如下图所示,主要包括颜色、大小、标签颜色、标签尺寸。
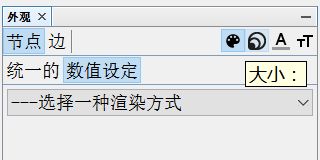
1.设置节点大小和颜色。
选中颜色,点击“数值设定”,选择渲染方式为“度”。
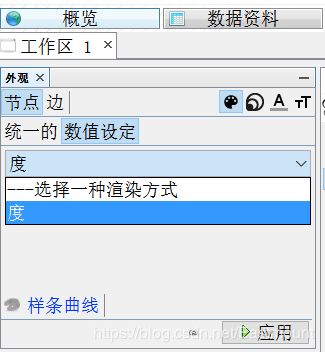
显示结果如下所示:

接着设置节点大小,数值设定为“度”,最小尺寸为20,最大尺寸为80。
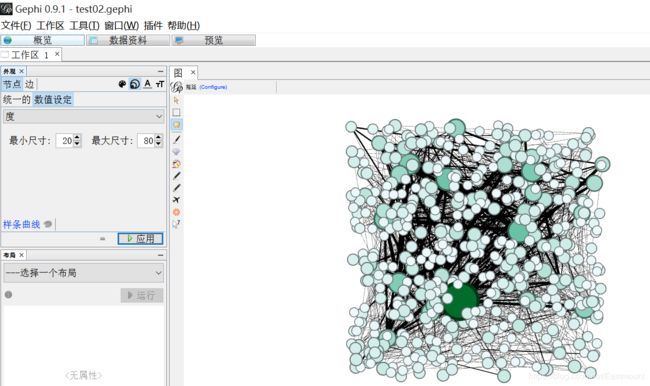
2.设置边大小和颜色。
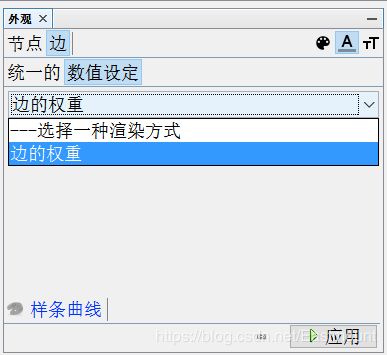
设置边颜色的数值设定为“边的权重”,如下图所示。
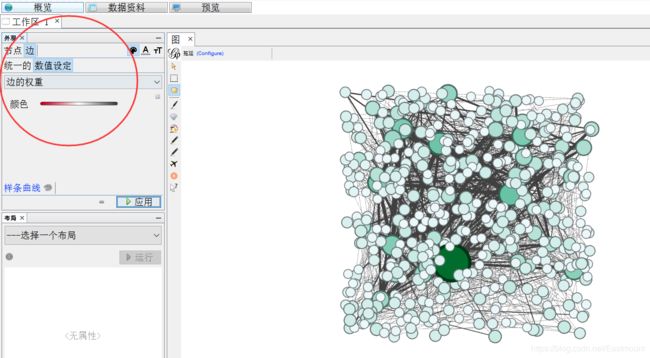
设置边的大小数值设定为“边的权重”。
3.在布局中选择“Fruchterman Reingold”。
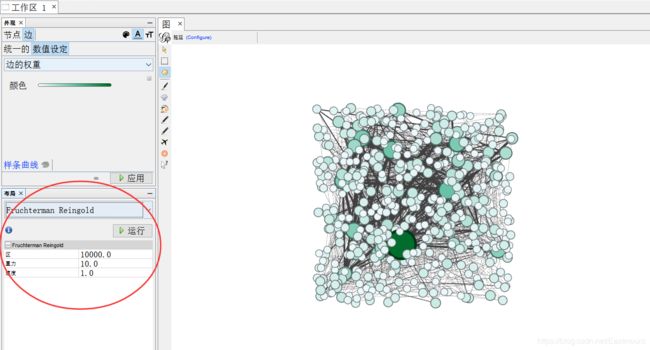
显示结果如下所示:

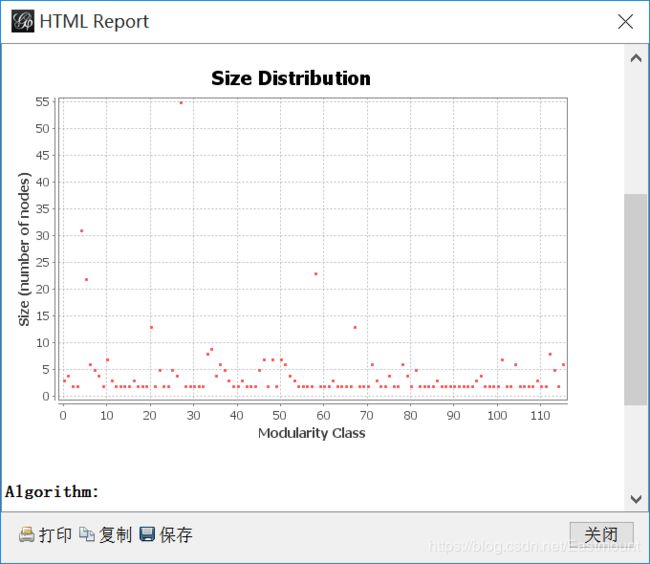
4.设置模块化。在右边统计中点击“运行”,设置模块性。

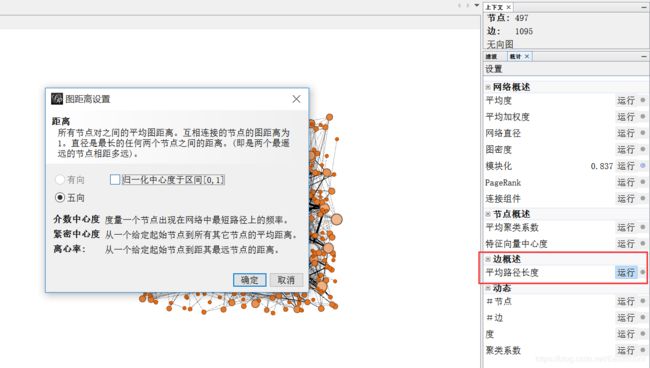
5.设置平均路径长度。在右边统计中点击“运行”,设置边概述。
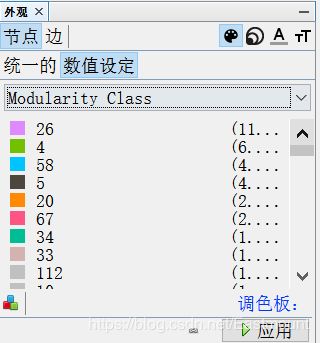
6.重新设置节点属性。
节点大小数值设定为“度”,最小值还是20,最大值还是80。
节点颜色数值设定为“Modularity Class”,表示模块化。
此时图形显示如下所示,非常好看,有关系的人物颜色也设置为了类似的颜色。

7.点击预览。
显示标签如下图所示:


希望基础文章对大家有所帮助,同学们可以尝试挖掘《红楼梦》或《人民的名义》,当两名觉得在一章或一集中同时出现,则认为共现,并构建类似的图片。
(By:Eastmount 2018-12-17 下午4点 http://blog.csdn.net/eastmount/ )