8、Flume 日志采集工具
一、Flume 基本概念
Flume 是流式日志采集工具,Flume 提供对数据进行简单处理并且写到各种数据接受方(可定制)的能力,Flume 提供从本地文件(spooldirectorysource)、实时日志(taildir、exec)、REST 消息、Thrift、Avro、Syslog、Kafka 等数据源上收集数据的能力。
Flume 适用场景:应用系统产生的日志采集,采集后的数据供上层应用分析。 Flume 不适用场景:大量数据的实时数据采集(要求低延迟、高吞吐率)。
与其他开源日志收集工具 scribe 比较而言,几乎不用用户开发,scribe 需要用户另外开发 client,而 Flume 每一种数据源均有相应的 source 去读取或者接收数据。

适用环境:
提供从固定目录下采集日志信息到目的地(HDFS,Hbase,Kafka)能力。提供实时采集日志信息(taildir)到目的地的能力。
Flume 支持级联(多个 Flume 对接起来),合并数据的能力。 Flume 支持按照用户定制采集数据的能力。
二、Flume 架构
(1) Flume 的外部结构:

如上图所示,数据发生器(如:facebook,twitter)产生的数据被被单个的运行在数据发生器所在服务器上的 agent 所收集,之后数据收容器从各个 agent 上汇集数据并将采集到的数据存入到 HDFS 或者 HBase 中
(2) Flume 事件
事件作为 Flume 内部数据传输的最基本单元.它是由一个转载数据的字节数组(该数据组是从数据源接入点传入,并传输给传输器,也就是 HDFS/HBase)和一个可选头部构成.
典型的 Flume 事件如下面结构所示:

我们在将 event 在私人定制插件时比如:flume-hbase-sink 插件是,获取的就是 event 然后对其解析,并依据情况做过滤等,然后在传输给 HBase 或者 HDFS.
(3) FlumeAgent

我们在了解了 Flume 的外部结构之后,知道了 Flume 内部有一个或者多个Agent,然而对于每一个 Agent 来说,它就是一共独立的守护进程(JVM),它从客户端哪儿接收收集,或者从其他的 Agent 哪儿接收,然后迅速的将获取的数据传给下一个目的节点 sink,或者 agent.如下图所示 flume 的基本模型Agent 主要由三部分构成:Source、Channel 和 Sink

Source:数据源,即是产生日志信息的源头,Flume 会将原始数据建模抽象成自己处理的数据对象:event。
ChannelPocessor:通道处理器,主要作用是将 source 发过来的数据放入通道(channel)中。
Interceptor:拦截器,主要作用是将采集到的数据根据用户的配置进行过滤、修饰。ChannelSelector:通道选择器,主要作用是根据用户配置将数据放到不同的通道(channel)中。
Channel:通道,主要作用是临时缓存数据。
SinkRunner:Sink 运行器,主要作用是通过它来驱动 SinkProcessor,Sink Processor 驱动 sink 来从 channel 中取数据。
SinkProcessor:sink 处理器,它主要是根据配置使用不同的策略驱动 sink 从 channel 中取数据,目前策略有:负载均衡、故障转移、直通。Sink:主要作用是从 channel 中取出数据并将数据放到不同的目的地。event:一个数据单元,带有一个可选的消息头,Flume 传输的数据的基本单位是event,如果是文本文件,通常是一行记录,这也是事务的基本单位。
Event 从 Source,流向 Channel,再到 Sink,event 本身为一个 byte 数组,并可携带 headers 信息。 event 代表着一个数据流的最小完整单元,从外部数据源来,流向最终目的。
在这里有必要先介绍一下 flume 中 event 的相关概念:flume 的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume 在删除自己缓存的数据。在整个数据的传输的过程中,流动的是 event,即事务保证是在 event 级别进行的。那么什么是 event 呢?—–event 将传输的数据进行封装,是 flume 传输数据的基本单位,如果是文本文件,通常是一行记录,event 也是事务的基本单位。 event 从 source,流向 channel,再到 sink,本身为一个字节数组,并可携带headers(头信息)信息。event 代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
(1)Source
Source 负责接收 events 或通过特殊机制产生 events,并将 events 批量放到一个或多个 Channels。有驱动和轮询 2 种类型的 Source。
①驱动型 source:是外部主动发送数据给 Flume,驱动 Flume 接受数据。
②轮询 source:是 Flume 周期性主动去获取数据。
Source 必须至少和一个 channel 关联。

(2)Channel
Channel 位于 Source 和 Sink 之间,Channel 的作用类似队列,用于临时缓存进来的 events,当 Sink 成功地将 events 发送到下一跳的 channel 或最终目的, events 从 Channel 移除。
不同的 Channel 提供的持久化水平也是不一样的:
① MemoryChannel:不会持久化。
② FileChannel:基于 WAL(预写式日志 Write-AheadLog)实现。
③ JDBCChannel:基于嵌入式 Database 实现。
Channels 支持事务,提供较弱的顺序保证,可以连接任何数量的 Source 和 Sink。 Flume 的 channel 数据在传输到下个环节(通常是批量数据),如果出现异常,则回滚这一批数据,数据还存在 channel 中,等待下一次重新处理类型:
①memorychannel:消息存放在内存中,提供高吞吐,但不提供可靠性;可能丢失数据。
②filechannel:对数据持久化;但是配置较为麻烦,需要配置数据目录和 checkpoint 目录;不同的 filechannel 均需要配置一个 checkpoint 目录。
③jdbcchannel:内置的 derby 数据库,对 event 进行了持久化,提供高可靠性;可以取代同样具有持久特性的 filechannel。
(3)Sink
Sink 负责将 events 传输到下一跳或最终目的,成功完成后将 events 从 channel移除。Sink 必须作用于一个确切的 channel。

flume 之所以这么高效,是源于它自身的一个设计,这个设计就是 agent,agent本身是一个 java 进程,运行在日志收集节点—所谓日志收集节点就是服务器节点。 agent 里面包含 3 个核心的组件:source—->channel—–>sink,类似生产者、仓库、消费者的架构。source:source 组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spoolingdirectory、netcat、sequence generator、syslog、http、legacy、自定义。channel:source 组件把数据收集来以后,临时存放在 channel 中,即 channel组件在 agent 中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在 memory、jdbc、file 等等。sink:sink 组件是用于把数据发送到目的地的组件,目的地包括 hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。 flume 的运行机制 flume 的核心就是一个 agent,这个 agent 对外有两个进行交互的地方,一个是接受数据的输入——source,一个是数据的输出 sink,sink 负责将数据发送到外部指定的目的地。source 接收到数据之后,将数据发送给channel,chanel 作为一个数据缓冲区会临时存放这些数据,随后 sink 会将 channel 中的数据发送到指定的地方—-例如 HDFS 等,注意:只有在 sink 将 channel 中的数据成功发送出去之后,channel 才会将临时数据进行删除,这种机制保证了数据传输的可靠性与安全性。
三、Flume 高级特性
(1)Flume 支持采集日志文件
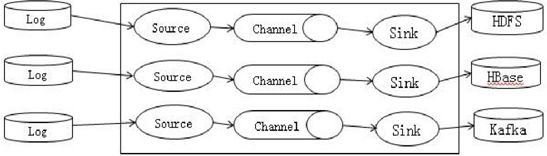
Flume 支持将集群外的日志文件采集并归档到 HDFS、HBase、Kafka 上,供上层应用对数据分析、清洗数据使用。
(2) Flume 支持多级级联和多路复制
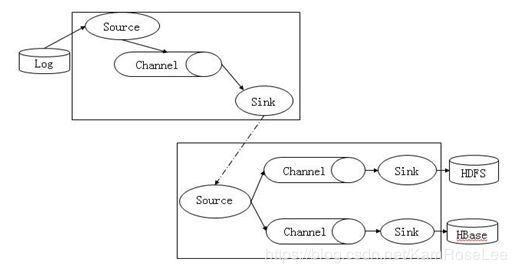
Flume 支持将多个 Flume 级联起来,同时级联节点内部支持数据复制。(3) Flume 级联消息压缩加密

Flume 级联节点之间的数据传输支持压缩和加密,提升数据传输效率和安全性。(4) Flume 数据监控

Flume source 接受数据量、channel 缓存数据量、sink 写入数据量,通过Manager 图形化呈现监控指标。支持 Channel 缓存缓存、数据发送、接收失败告警。
(5) Flume 传输可靠性

Flume 在传输数据过程中,采用事务管理方式,保证传输过程中数据不会丢失,增强了数据传输的可靠性,同时缓存在 channel 中的数据如果采用 file channel, 进程或者节点重启数据不会丢失。
4.外文文献:
Apache Flume - Data Transfer In Hadoop
Big Data, as we know, is a collection of large datasets that cannot be processed using traditional computing techniques. Big Data, when analyzed, gives valuable results. Hadoop is an open-source framework that allows to store and process Big Data in a distributed environment across clusters of computers using simple programming models.
Streaming / Log Data
Generally, most of the data that is to be analyzed will be produced by various data sources like applications servers, social networking sites, cloud servers, and enterprise servers. This data will be in the form of log files and events.
Log file − In general, a log file is a file that lists events/actions
that occur in an operating system. For example, web servers list every request made to the server in the log files.
On harvesting such log data, we can get information about −
the application performance and locate various software and hardware failures.
the user behavior and derive better business insights.
The traditional method of transferring data into the HDFS system is to use the put command. Let us see how to use the put command.
HDFS put Command
The main challenge in handling the log data is in moving these logs produced by multiple servers to the Hadoop environment.
Hadoop File System Shell provides commands to insert data into Hadoop and read from it. You can insert data into Hadoop using the put command as shown below.
$ Hadoop fs –put /path of the required file /path in HDFS where to save the file
Problem with put Command
We can use the put command of Hadoop to transfer data from these sources
to HDFS. But, it suffers from the following drawbacks −
Using put command, we can transfer only one file at a time while the data generators generate data at a much higher rate. Since the analysis made on older data is less accurate, we need to have a solution to
transfer data in real time.
If we use put command, the data is needed to be packaged and should be ready for the upload. Since the webservers generate data continuously, it is a very difficult task.
What we need here is a solutions that can overcome the drawbacks of put command and transfer the "streaming data" from data generators to centralized stores (especially HDFS) with less delay.
Problem with HDFS
In HDFS, the file exists as a directory entry and the length of the file will be considered as zero till it is closed. For example, if a source is writing data into HDFS and the network was interrupted in the middle of the operation (without closing the file), then the data written in the file will be lost.
Therefore we need a reliable, configurable, and maintainable system to transfer the log data into HDFS.
Note − In POSIX file system, whenever we are accessing a file (say
performing write operation), other programs can still read this file (at least the saved portion of the file). This is because the file exists on the disc before it is closed.
Available Solutions
To send streaming data (log files, events etc..,) from various sources
to HDFS, we have the following tools available at our disposal −
Facebook’s Scribe
Scribe is an immensely popular tool that is used to aggregate and stream log data. It is designed to scale to a very large number of nodes and be robust to network and node failures.
Apache Kafka
Kafka has been developed by Apache Software Foundation. It is an open-source message broker. Using Kafka, we can handle feeds with high-throughput and low-latency.
Apache Flume
Apache Flume is a tool/service/data ingestion mechanism for collecting aggregating and transporting large amounts of streaming data such as log data, events (etc...) from various webserves to a centralized data store. It is a highly reliable, distributed, and configurable tool that is principally designed to transfer streaming data from various sources
to HDFS.
In this tutorial, we will discuss in detail how to use Flume with some examples.
从 Hadoop 的角度来讲,本身各个底层组建之间就支持相互之间的数据交互和资源共享,但是数据交互第一个会影响到组件的性能,另一个问题就是在传输的时候由于网络的问题可能会导致数据的丢失,所以针对于种种传统组件中的问题,我们提出了开发其他组件用于日志收集和数据共享,所以 Flume 被提出和开发。 Flume 的整体内容并不多,但是主要是为了保障数据进行共享传输和统一集中存储的传输安全性和数据的可靠性,通过 Flume 进行数据传输之后,其他组件就无需关注传输中的一些问题了,可以专心进行自身相关的工作。