大规模codis集群的治理与实践
作者介绍:唐聪,后台开发,目前主要负责部门内公共组件建设、超级会员等产品基础系统开发等。
一、背景和概况
在2015年末,为了解决各类业务大量的排行榜的需求,我们基于redis实现了一个通用的排行榜服务,良好解决了各类业务的痛点,但是随着业务发展到2016年中,其中一个业务就申请了数百万排行榜,并随着增长趋势,破千万指日可待,同时各业务也希望能直接使用redis丰富数据结构来解决更多问题(如存储关关系链、地理位置等)。
当时面临的问题与挑战如下:
排行榜服务无法支撑千万级排行榜数(排行榜到redis实例映射关系存储在zookeeper,zookeeper容量瓶颈)
单机容量无法满足关系链等业务需求
排行榜和关系链大部分大于1M,同时存在超大key(>512M),需支持超大key迁移
SNG的Grocery存储组件,支持redis协议,但又存在单key value大小1M的限制
高可用,需要支持redis主备自动切换
SNG数据运维组未提供redis集群版接入服务,在零运维的支持下如何高效治理众多业务集群?
面对以上挑战,经过多维度的方案选型对比,最终选择了基于codis(3.x版本),结合内部需求和运营环境进行了定制化改造,截止到目前,初步实现了一个支持单机/分布式存储、平滑扩缩容、超大key迁移、高可用、业务自动化接入调度部署、多维度监控、配置管理、容量管理、运营统计的redis服务平台,在CMEM、Grocery不能满足业务需求的场景下,接入了SNG增值产品部等五大部门近30+业务集群(图一),350+实例, 2T+容量。
下文将从方案选型、整体架构、自动化接入、数据迁移、高可用、运营实践等方面详细介绍我们在生产环境中的实践情况。

图一 部分接入业务列表
二、方案选型
Redis因其丰富的数据结构、易用性越来越受到广大开发者欢迎,根据DB-Engines的最新统计,已经是稳居数据库产品的top10(见图一)。云计算服务产商AWS、AZURE、阿里云、腾讯云都提供了Redis产品,各云计算产商主流方案都是基于开源Redis内核做定制化优化,解决Redis不足之处,在提升Redis稳定性、性能的同时最大程度兼容开源Redis。单机主备版各厂商差异不大,都是基于原生Redis内核,但是集群版,AWS使用的原生的Redis自带的Cluster Mode模式(加强版),,阿里云基于Proxy、原生Redis内核实现,路由等元存储数据保存在RDS,架构类似Codis, 腾讯云集群版是基于内部Grocery。了解完云计算产商解决方案,再看业界开源、公司内部,上文提到我们面临问题之一就是单机容量瓶颈,因此需要一款集群版产品,目前业界开源的主流的Redis集群解决方案有Codis,Redis Cluster,Twemproxy,公司内部的有SNG Grocery、IEG的TRedis,从以下几个维度进行对比,详细结果如表一所示(2016年10月时数据):
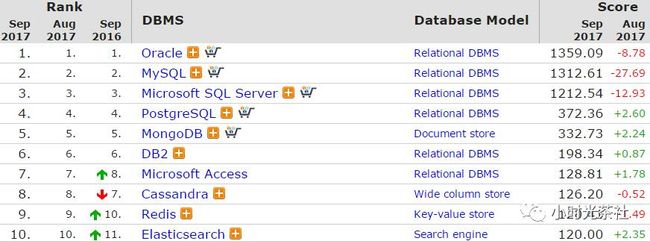
图二 数据库流行度排名
Feature |
Codis |
Redis Cluster |
TwemProxy |
Grocery Redis |
TRedis |
存储引擎 |
基于原生Redis扩展增加迁移相关指令 |
原生Redis |
原生Redis |
多阶哈希+LinkTable |
Rocksdb/LSM |
数据分布算法 |
哈希槽crc16(key) % 1024 |
哈希槽crc16(key) % 16384 |
ketama/modula/random |
一致性hash |
哈希槽 |
平滑扩缩容 |
支持 |
支持 |
不支持 |
支持 |
支持 |
Value大小限制 |
无 |
无 |
无 |
1M |
无 |
ZSET实现 |
Skiplist + Hash |
Skiplist + Hash |
Skiplist + Hash |
Skiplist + Hash |
Skiplist+Hash(内存),key-value(磁盘) |
开发语言(Proxy) |
Go |
采用无中心节点设计,无Proxy |
C |
C++ |
C/C++(基于TwemProxy) |
单线程/多线程/多进程(Proxy) |
多线程 |
无 |
单线程 |
多进程 |
单线程/多线程 |
超大key迁移(>512M) |
不支持 |
不支持 |
不支持 |
- |
- |
机型 |
内存型 |
内存型 |
内存型 |
内存型或SSD IO型 |
SSD IO型 |
Client |
任意 |
需要支持cluster语义 |
任意 |
提供SDK |
任意 |
Pipeline |
支持 |
不支持 |
支持 |
支持 |
支持 |
运维成本 |
低 |
高 |
高 |
无 |
无 |
定制开发成本 |
低 |
高 |
高 |
无 |
无 |
表一 Redis集群产品对比
云计算产商和业界开源、公司内部的解决方案从整体架构分类,分别是基于Proxy中心节点和无中心节点,在这点上我们更偏爱基于Proxy中心节点架构设计,运维成本更低、更加可控,从存储引擎分类,分别是基于原生Redis内核和第三方存储引擎(如Grocery的多阶HASH+LinkTable、TRedis的Rocksdb),在这点上我们更偏爱基于原生Redis内核,因为我们要解决业务场景就是Grocery和CMem无法满足的地方,我们业务大部分使用的数据结构是ZSET且Key一般超过1M,几十万级元素的ZSET Key是常态,Grocery的Value 1M大小限制无法满足我们的需求,同时我们需要ZSET的ZRank的时间复杂度是O(LogN),基于RocksDb的存储引擎时间复杂度是O(N),因此这也是无法接受的。随着业务发展,容量势必会发生变化,因此扩缩容是常态,而TwemProxy并不支持平滑扩缩容,因此也无法满足要求。最后,我们需要结合内部运营环境和需求做定制化改造,在零运维的支持下,通过技术手段,最大程度自动化治理、运营众多多业务集群,而Codis代码结构清晰,开发语言又是现在比较流行的Go,无论是运行性能、还是开发效率都较高效,因此我们最终选择了Codis.
三、整体架构
基于Codis定制开发而成的Redis服务平台整体架构如图二所示,其包含以下组件:
Proxy:实现了Redis协议,除少数命令不支持外,对外表现和原生Redis一样。解析请求时,计算key对应的哈希槽,将请求分发到对应的Redis,业务通过L5/CMLB进行寻址。
Redis: Redis在内存中实现了string/list/hash/set/zset等数据结构,对外提供数据读写服务、持久化等,默认一主一备部署。
Dashboard:提供管理集群的API和访问元数据存储的通用API(CURD操作,屏蔽后端元数据存储差异)。
Zk/Etcd/Mysql:第三方元数据存储,保存集群的proxy、redis、各哈希槽对应的redis 地址等信息。
HA:基于Redis Sentinel实现Redis主备高可用,部署在多个IDC,采用Quorum机制、状态机进行主备自动切换。
Scheduler:调度服务,负责对业务接入申请单进行自动调度部署、集群自动化扩容、各集群运营数据统计等。
运维管理系统: Web可视化管理集群,提供业务接入、集群管理、容量管理、配置管理等功能。
CDB:存储业务申请单、各节点容量等信息。
Agent:负责定时监控和采集Redis、Proxy、Dashboard运行统计信息,上报到米格监控系统和CDB。
HDFS:冷备集群,Redis冷备文件每天会定时上传到HDFS,提供给业务下载和在主备皆故障的情况下做数据恢复使用。

图三 整体架构
四、自动化接入
当面对成百上千乃至上万个Redis实例时,人工根据业务申请单去过滤无效节点、筛选符合业务要求的节点、再从候选节点中找出最优节点等执行一些列繁琐枯燥流程,这不仅会导致工作乏味、效率低,而且更会大大提升系统的不稳定性,引发运营事故。当繁琐、复杂的流程变成自动化后,工作就会变得充满乐趣,图三是业务接入调度流程,用户在运维管理系统提单接入后,调度器会定时从CDB中读取待调度的业务申请单,首先是筛选过滤流程,此流程包含一系列模块,在设计上是可以动态扩展,目前实现的筛选模块如下:
Health: 健康探测模块,过滤宕机、裁测下线的节点IP
Lable:标签模块,根据业务申请单匹配部署环境(测试、现网)、部署城市、业务模块、Redis存储类型(单机版、分布式存储版)
Instance: 检查当前节点上是否有空余的Redis实例(筛选Redis实例时)
Capacity: 检查当前节点CPU、Memory是否超过安全阀值
Role:检查当前节点角色是否满足要求(如Redis实例所属节点机器必须是Redis Node),角色分为三类Proxy Node,Redis Node,Dashboard Node
以上筛选模块,适用Proxy、Redis、Dashboard节点的筛选,在完成以上筛选模块后,返回的是符合要求的候选节点,对候选节点我们又需要对其评分,从中评出最优节点,目前实现的评分模块有最小内存调度、最大内存调度、最小CPU调度、随机调度等。

图四 业务接入调度流程
通过运行以上一系列筛选和评分模块后,就可以准确、快速的获取到新集群的Dashboard、Proxy、Redis的部署节点地址,但是离自动化交付给业务使用还差一个重要环节(部署)。目前主要是通过以下三个方面来解决自动化部署,其一,Codis本身是基于配置文件部署的,每新增一个业务集群必须在配置文件指定集群名字,新建一个PKG包,维护成本非常高,我们通过监听指定网卡+核心配置项迁移到ZooKeeper,实现配置管理API化,同时部署包标准统一化。其二,在各节点上都会部署Agent,Agent会定时采集上报各节点信息入库到容量表,无需人工干预,容量管理自动化,未使用的实例形成一个小型资源buffer池。其三,部署是个多阶段的流程,需要分解成各状态,并保证每个状态都是可重入、幂等性的,当所有状态完成后,则调度结束,某状态失败时,下次调度检查到申请单非完成状态,会自动重试失败的流程,直至完成,拆分后的部署状态流程图如图四所示。
通过以上两个核心流程,自动化调度分配实例+自动化部署,我们可以将部署时间从最开始的15min+,优化到秒级,在大大提升工作效率的同时,提升了系统稳定性、避免了人为操作错误引起的运营事故。

图五 自动化部署流程
五、数据迁移
扩缩容是存储系统的常归化操作,理想中的数据迁移应该是尽量不影响线上业务正常读写访问、支持任意大小的Key、优异的迁移性能、保证迁移前后的数据一致性,但是Codis在2016年末的时候数据迁移功能差强人意。首先是迁移速度慢,其次是只支持同步迁移,较大的Key迁移会阻塞Redis主线程,影响线上业务正常读写,最后是不支持超大Key迁移(>512M)。虽然各种最佳实践不断强调需要避免大Key,的确大Key可能会是系统潜在的一个风险点(如大key删除、迁移、热点访问等),但是在不少业务场景下,业务层是无法高效、简单的完成分Key的,Redis本身也在不断的优化,降低大Key风险,比如4.0版本提供了异步删除Key功能,倘若存储层能快速完成大Key迁移,这不仅会大大简化业务端的复杂度,更会提升Redis稳定性、可用性,但是内存型存储系统在大Key迁移的上复杂度比非内存型存储系统多一个数量级,这也是为什么Redis到现在还未实现大Key迁移和异步迁移的功能。
大Key若能拆分成小Key分批次异步迁移、并在迁移过程中该Key可读、不可写,只要迁移速度够快,这对业务而言是可以接受的,在2016年末的时候我跟Codis核心作者spinlock交流了大key迁移的想法,令人惊喜膜拜的是,他在农历春节期间就快马加鞭实现了异步迁移原型,在这过程中我们协助其测试、反馈BUG和瓶颈、不断改进、优化迁移性能,最终异步迁移不仅支持任意大小Key迁移,而且迁移性能相比同步迁移要快5-6倍,我们也是第一个在线上大规模应用实践Redis异步迁移的,更令人可喜的是此异步迁移方案击败了Redis作者antirez之前计划的多线程方案,将正式合入Redis 4.2版本。
在介绍异步迁移方案实现前,先介绍下Codis是如何保证过程中数据一致性和为什么同步迁移慢。如何保证迁移过程中各Proxy读取到的数据一致性?Codis主要迁移流程如图五所示,其采用了多阶段状态机实现,类似分布式事务中的多阶段提交协议,其核心流程如下。
在运维管理系统上,提交迁移指令,Dashboard更新ZooKeeper上哈希槽状态为待迁移,即返回(时序图1,2,3步骤)。
Dashboard异步定时检查ZooKeeper上是否有待迁移状态的哈希槽,若有则首先进入准备中状态,Dashboard将此状态同时分发到所有Proxy,若有异常Proxy应答失败,则无法进入迁移,状态回退(时序图4,5,6,7步骤)。
若所有Proxy应答成功,则进入准备就绪状态,Dashboard将此状态同时分发到所有Proxy,Proxy收到此状态后,访问此哈希槽中的Key的业务请求将被阻塞等待,若有Proxy应答失败,则会立刻回退到上个状态(时序图8,9,10步骤)。
若所有Proxy应答成功,则进入迁移状态,Dashboard将此状态同时分发到所有Proxy,Proxy收到此状态后,不再阻塞对迁移哈希槽中的Key访问,若业务请求Key属于待迁移哈希,首先会从迁移源Redis中读取数据,写到目的端Redis中去,然后再获取/修改数据返回,这是其中一种迁移方式,被动迁移,Dashboard也会发起主动迁移,直至数据迁移结束(时序图11,12,13,14,15步骤)。
通过多阶段的状态提交和细粒度、ms级别的锁,Codis优雅的解决了迁移过程中的数据一致性。

图六 Codis迁移状态流程图
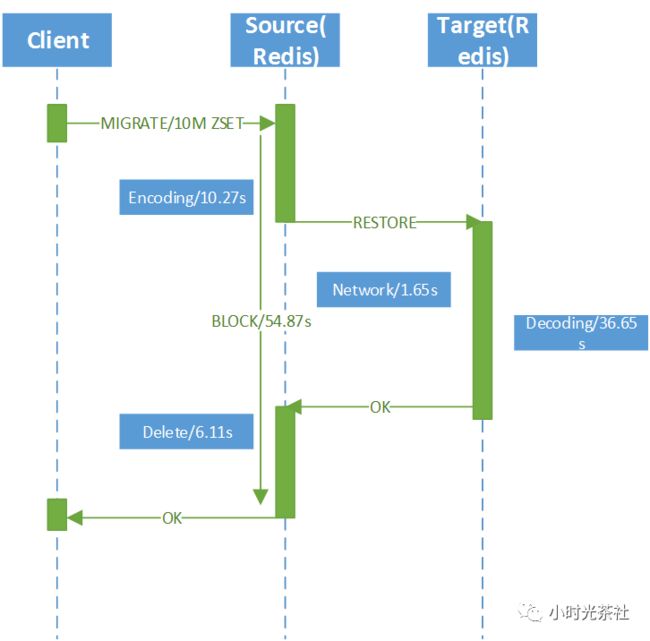
图七 Redis同步迁移流程
再看为什么同步迁移慢,图七是迁移一个1000万元素的ZSET耗时分析,当Client发起迁移指令后,源端将整个ZSET序列化成payload花费了10.27s,通过网络传输给目的端Redis花费1.65s,目的端Redis收到数据后,将其反序列化成内存中的数据结构,花费了36.65s,最后源端Redis删除迁移完成的Key又花费了6.11s,而整个迁移过程中,源端Redis是完全阻塞的,不能提供任何读写访问。因此,异步迁移方案若要提升迁移性能,必须在以上四个流程上面做优化。
异步迁移的流程如图八所示,面对同步迁移的四个核心点,异步迁移的解决方案如下:
拆分rdbSave(encoding)过程,解决同步序列化开销。对于大key,不再使用rdbSave对数据进行encoding,而是通过指令拆解, redis中的数据结构(list,set,hash,zset)都可以等价的拆分成若干个添加指令,比如含有1000万元素的zset,可以拆分成10万个zadd指令,每个zadd指令添加100个数据
拆分Restore(network)过程,解决同步IO开销。异步IO实现,发送数据不再阻塞。
拆分rdbLoad(decoding)过程,解决反序列号开销。因源端发送过来的数据不再是rdb二进制数据,目的端redis无需再使用rdbLoad,只需将收到的添加指令数据直接更新到对应的内存数据结构即可,同时使用了一些trick,比如内存预分配,避免频繁申请内存,double转换成long long,提高迁移性能等。
异步删除Key,解决同步删除Key耗时问题。通过额外的工作线程异步删除key,不再阻塞redis主线程。

图八 Redis异步迁移流程
1000万的ZSET,同步迁移需要54.87s,而异步迁移只需要8.3s,在不阻塞在线业务的前提下,性能提升6倍多,以我们生产环境某全球9000w排行榜为例,之前单机主备版加载到内存都需要20分钟,而用异步跨机器迁移只需要180s左右, 更详细的迁移介绍可参看附录spinlock的Codis新版本特性介绍。
六、高可用
各组件中跟用户请求相关性很强的组件分别是Proxy、Redis、元数据存储(ZooKeeper),相关性较弱的是Dashboard。
Proxy:多机多IDC部署,调度服务会根据IDC ID,自动打散相同proxy,尽量保证同一集群proxy部署在不同IDC,通过L5和CMLB进行容灾。
Redis:基于Redis Sentinel进行主备自动化切换。
ZooKeeper:高可用分布式协调服务,一半以上节点存活即可提供服务,同时只有在Proxy启动时和运行过程中发生数据迁移才会依赖ZooKeeper,绝大部分正常请求不受ZooKeeper 集群状态影响。
Dashboard: 负责协调集群状态变更及一致性,目前在设计上是个单点,但是只有在就集群运行过程中发生数据迁移才会依赖它,因此是弱相关性, 后续还可以优化成多节点部署,通过ZooKeeper的分布式锁来保证只有一个节点能提供服务,当提供服务的节点故障时,通过一系列流程(如需通知Proxy,Dashboard变更等)实现Dashboard自动化故障切换。
重点介绍redis的主备自动切换流程,常见的Master-Slave存储系统自动切换方案一般有如下三种:
基于ZooKeeper来做主备自动切换,如公司内部的TDSQL,在Mysql主备节点上部署Agent,在ZooKeeper集群上注册临时节点,当主机宕机时,Scheduler在检测到临时节点消失超过阀值后发起容灾流程。
基于相互独立的探测Agent实现,如MIG的DCache,IEG的TRedis。IEG TRedis将主备自动切换流程拆分成故障决策模块(探测Redis存活)、故障同步模块、故障监控模块(double check)、故障切换表同步模块(将待切换的实例放入队列)、故障核心模块( 切换路由)。
基于Quorum的分布式探测Agent,如Redis的Sentinel,Sentinel在新浪微博等公司已经进行了较大规模应用,Codis也是基于此实现主备自动切换,我们在此基础上增加了告警和当网络出现分区时,增加了一个降级操作,避免脑裂,其详细流程图八所示。

图九 Redis主备自动切换流程
图九流程简要分析如下:
图中三个Sentinel部署在不同的可用区,实际现网我们是部署了五个,覆盖各大运营商IDC等,各Sentinel会定时向master/slave发送ping等请求探测master/slave存活,并通过gossip协议相互交流信息,同时各Proxy实时监听Sentinel的状态消息。(图八1,2流程)
当master出现异常,Sentinel在一定时间(可配置,如2min,避免网络抖动,误切)内都持续无法访问Master时,Sentinel就会认为此节点为主观故障(S_DOWN),Sentinel会彼此通过gossip协议相互交换信息,当一半以上(可配置)的sentinel认为此master都故障后,此节点会被判断为客观故障(O_DOWN),各Sentinel会选举出一个Leader来执行主备切换,Leader首先从各备机中选择一个最佳节点,算法是首选过滤掉与master断线时间超过阀值的slave,其次优先选择slave_priority较小的,若priority一样,则选择replication offset最大的,若offset也一致,则按字典顺序排序选择最小的runid.选择出最佳候选master后,Leader会将其提升为master,同时向订阅者发出+switch-master 事件,通过tnm2/uwork发出L0告警通知开发运维,然后更改其他备机主从关系,从新主机同步数据(图八3,4,5流程)。
各个Proxy收到Sentinel的+switch-master event后,会遍历所有sentinel查询故障组最新master,当一半以上的sentinel返回了故障组新的master,Proxy则会切换路由,路由到组的请求,将发到新的master,主备自动切换完成。(图八6流程)
但是在极端情况下若网络出现分区,业务服务、个别Proxy跟Redis Master在同一个可用区,则会出现脑裂,为了避免此种情况,部署在Redis机器上的Agent会定时持续检测与ZooKeeper连接是否通畅,若连接不上则会向Redis发送降级指令,不可读写(图八7流程)。
七、运营实践
多维度监控
Proxy/Dashboard/Redis机器上的Agent定时采集proxy、redis的qps、connection、memory_used等10几个指标,上报到米格监控系统,针对核心监控指标配置阀值和波动告警。监控系统在线上数次捕捉到集群异常(如连接数超过阀值、某redis实例无备机等),及时发出有效告警,提前发现问题、解决问题。同时,也不连VPN的情况下也可以便捷地通过手机快速查看监控曲线、定位问题等,大大提高工作效率。

图十 Redis Ops曲线

图十一 master/slave offset差异曲线
低负载优化
集群缩容和相同业务复用同集群
存储机多实例部署,现在默认8个实例
通过Agent顺序触发个实例aof rewrite和rdb save,避免多个实例同时fork,从而提高存储机内存使用率至最高80%
Proxy机器多实例部署(进行中)
3.多租户
小业务通过在key前缀增加业务标识,复用相同集群
大业务使用独立集群,独立机器
4.数据安全及备份
访问所有Redis实例都需要鉴权
Proxy层可统计汇总所有写请求指令
默认开启AOF日志
定时上报Redis AOF、RDB文件到HDFS集群
八、总结
基于Codis为核心的Redis服务平台高效解决了SNG大量业务的痛点(不限制Key大小,原生的Redis内核,高性能),提高了开发效率,助力产品更快发展,但是因人力有限(半个开发投入,在业务项目人力紧张的时候,零投入),还有若干待完善的地方,如不支持冷热分离等。 在千呼万唤中,目前公司内的存储组自研的CKV+(基于共享内存实现Redis各类数据结构)的单机主从版也终于上线,集群版也在紧锣密鼓的开发中,CKV+较好的解决了Redis内存使用率、跨IDC部署、数据备份及同步机制的一些不足之处,后续业务也将有更多的选择!最后感谢antirez,spinlock的无私贡献!
九、参考资料
Redis Documentation
Github Codis
Github Redis
4. Codis新版本特性介绍(spinlock)