实体-关系联合抽取:Incremental Joint Extraction of Entity Mentions and Relations
论文地址:https://www.aclweb.org/anthology/P14-1038.pdf
文章标题:Incremental Joint Extraction of Entity Mentions and Relations(增量联合提取提及的实体和关系)ACL2014
Abstract
提出了一种增量联合框架,利用结构感知器和有效的集束搜索同时提取提及的实体和关系。新框架采用了基于半马尔可夫链思想的基于分段的解码器,与传统的基于标记的标记方法不同。此外,通过不精确搜索,我们开发了一些新的和有效的全局特性作为软约束来捕获提及的实体和关系之间的相互依赖性。在自动内容提取(ACE)1语料库上的实验表明,我们的联合模型显著优于强流水线方法基线,该基线的性能优于最佳端到端系统。
一、Introduction
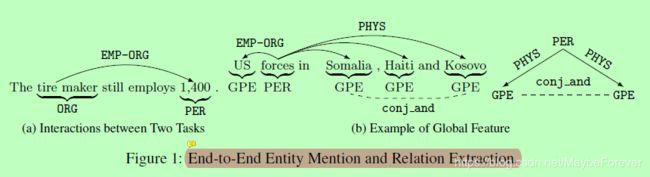
图一:端到端的实体提及和关系抽取
端到端实体提及和关系提取的目的是从非结构化文本中发现实体提及的关系结构。该问题被人为地分解为实体提及边界识别、实体类型分类和关系提取等几个部分。虽然采用这样的流水线方法可以使系统相对容易地进行组装,但是它有一些限制:首先,它禁止组件之间的交互。上游组件中的错误在没有任何反馈的情况下传播到下游组件。其次,它将问题过度简化为多个本地分类步骤,而没有对远程和跨任务依赖关系进行建模。相反,我们把这个任务重新表述为一个结构化的预测问题,以揭示隐藏结构的语言和逻辑属性。例如,在图1中,每个句子的输出结构可以解释为一个图,其中提到的实体是节点,关系是带有关系类型的有向弧。通过联合预测结构,我们的目标是通过捕获(一)两个任务之间的交互来解决上述限制。例如,在图1a中,虽然提取器很难预测“1400”是一个人(PER),但是上下文单词“雇用”在“轮胎制造商”和“1400”之间强烈地表明了一个雇佣组织(EMP-ORG)的关系,它必须包含PER的提及。(二)隐藏结构的全局特征。各种实体提及和关系共享语言和逻辑约束。例如,我们可以使用图1b中的三角形特征来确保“部队”之间的关系,每个实体都提到“索马里/GPE”、“海地/GPE”和“科索沃/GPE”是同一类型的(Physical(PHYS),在本例中)。
根据上述直觉,我们引入了一个基于结构化感知器的联合框架(Collins, 2002;Collins和Roark, 2004)使用集束搜索同时提取实体提及和关系。得益于不精确的搜索,我们还能够以较低的成本使用任意的全局特性。该算法已成功地应用于其它一些自然语言处理(NLP)任务。我们的任务不同于依赖项解析(如(Huang和Sagae, 2010)),因为关系结构更灵活,每个节点可以有任意的关系弧。我们之前的工作(Li et al., 2013)使用基于标记的标记感知器模型来联合提取事件触发器和参数。相比之下,我们的目标是解决一个更具挑战性的任务:识别提及边界和类型以及关系,这就提出了一个问题,即具有不同提及边界的相同句子的分配在搜索期间很难同步。为了解决这个问题,我们采用了一种基于分段的译码算法(Sarawagi and Cohen, 2004; Zhang and Clark, 2008)基于半马尔可夫链的思想(a.k.a, multiple-beam search algorithm)。
之前关于实体提及和关系的联合推理的尝试(如Roth和Yih, 2004;Roth和Yih, 2007))假设实体提及边界已经给出,提及和关系的分类器是分别学习的。作为一个关键的区别,我们使用单个模型逐步提取实体提及和关系。本文的主要贡献如下:
- 这是第一个使用单个联合模型增量预测实体提及率和关系的工作(第3节)。
- 联合框架中提及边界的预测提出了在同一集束中同步不同任务的挑战。我们通过在节段级检测实体提及来解决这个问题,而不是使用传统的基于标记的方法(第3.1.1节)。
- 我们设计了一组新颖的全局特征,这些特征基于低成本的整个输出图结构的软约束(第4节)。
实验结果表明,该框架比流水线方法具有更好的性能,全局特征进一步提高了性能。
二、Background
2.1 Task Definition
我们正在处理的实体提及提取和关系提取任务是那些自动内容提取(ACE)程序。ACE定义了7种主要实体类型,包括人员(PER)、组织(ORG)、地理实体(GPE)、位置(LOC)、设施(FAC)、武器(WEA)和车辆(VEH)。关系抽取的目的是提取目标类型在同一句子中出现的一对实体提及之间的语义关系。ACE ’ 04定义了7种主要关系类型:物理关系(PHYS)、人-社会关系(PER- soc)、就业-组织关系(EMP-ORG)、代理-工件关系(ART)、单位/组织关系(Other-AFF)、gpe - attachment (GPE-AFF)和话语关系(DISC)。ACE’05保留了PER-SOC、ART和GPE-AFF,将PHYS分成PHYS和一个新的关系类型Part-Whole,去除DISC,将EMP-ORG和Other-AFF合并成EMP-ORG。
在这篇论文中,我们使用(特殊符号)表示非实体或非关系类。我们认为关系是不对称的。同一关系类型具有相反的方向被认为是两个类,我们称之为有向关系类型。
以往关于关系提取的研究大多假设在本文中给出了实体提及,我们的目标是解决从原始文本中端到端实体提及和关系提取的问题。
2.2 Baseline System
为了开发代表最先进的流水线方法的基线系统,我们训练了一个线性链条件随机场模型(Lafferty et al., 2001)用于实体提及提取和最大熵模型用于关系提取。
(1)Entity Mention Extraction Model
我们将实体提及提取的问题重新转换为当前系统中连续标记标记任务(Florian et al., 2006)。我们应用了BILOU方案,其中每个标记表示一个令牌分别表示一个实体的开始(Beginning)、内部(Inside)、最后(Last)、外部(Outside)和单元(Unit)。我们的大多数特征与(Florian et al.,2004;除了我们没有他们的地名辞典和其他提及检测系统的输出作为特征。我们的附加功能如下:
- 基于依赖项解析的当前令牌的调控词(Marneffe et al., 2006)。
- 布朗聚类中每个单词的前缀来自TDT5语料库(Sun et al., 2011)。
(2)Relation Extraction Model
给定一个带有实体提及注释的句子,基线关系提取的目标是将每个提及对分类为具有方向或(特殊符号,表示non-relation)。我们的大部分关系提取特征是基于(Zhou et al., 2005)和(Kambhatla, 2004)的前期工作。我们设计了以下附加功能:
- 包含两次提及的短语的标签序列。例如,图1a中的句子,其顺序是“NP VP NP”。我们还增加了每个短语的头词。
- (Chan和Roth, 2010)中描述了四种语义模式。
- 我们复制了每个词的特征,用它的布朗聚类替换每个词。
三、Algorithm
3.1 The Model
我们的目标是根据任意的特征和约束来预测每个句子的隐藏结构。我们使用以下线性模型预测对于x最可能的结构y:
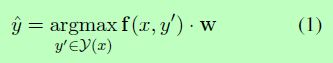
其中每个候选赋值的得分定义为特征向量f (x, y)与特征权值w的内积。
由于该结构包含了实体提及关系和全局特征,因此我们的目标是利用全局特征。不存在多项式时间算法来寻找最佳结构。在实际应用中,我们采用集束搜索来逐步扩展输入句子的部分结构,从而找到得分最高的结构。
3.1.1 Joint Decoding Algorithm
一个主要的挑战,搜索实体提及和关系增量是不同分配的对齐。同一句子的赋值可以有不同数量的实体提及和关系弧。实体提及提取任务通常被重新转换为BIO或BILOU方案的标记级顺序标记问题(Ratinov和Roth, 2009;弗洛里安等人,2006)。我们的任务的一个简单的解决方案是采用这种策略,将每个令牌视为一种状态。然而,同一句子的不同赋值可能有不同的提及边界。比较部分提及和完全提及的模型得分是不公平的。关系的搜索过程也很难同步。例如,同一句话以“York”结尾的两个假设是:

该模型将倾向于不正确的分配“New/B-GPE York/L-GPE”,因为它可以有更多的信息特征作为完整的提及(例如,如果整个提及出现在GPE gazetter中的二进制特征)。此外,由于“New/B-FAC York/I-FAC”还没有被完全提及,所以对两个物理关系的预测无法同步。
为了解决这些问题,我们采用了半马尔可夫链的思想(Sarawagi和Cohen, 2004),其中每个状态对应于输入序列的一段。他们提出了一种用于半马尔可夫链精确推理的维特比算法。我们通过集束搜索来放松最大操作,从而得到一个类似于in (Zhang and Clark, 2008)中的多波束算法的基于分段的解码器。让ˆd实体提及长度的上界。以第i个令牌结束的k-best局部赋值可计算为:
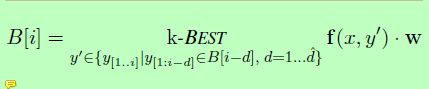
其中y[1:i−d]表示在(i-d)-th令牌处结束的部分构型,而y[i−d+1,i]对应于一个新的分段x[i−d+1,i]的结构。我们的联合解码算法如图2所示。对于每个令牌索引i,它为部分赋值维护一个集束,其最后一部分在第i个令牌结束。搜索过程中有两种类型的操作:

图二:实体提及和关系的联合解码。
1、APPEND (Lines 3-7)
首先,该算法列举了所有可能的片段(子序列),该子序列在具有各种实体类型的当前令牌处结束。一种特殊类型的段是带有非实体标签(特殊符号)的单个令牌。然后,将每个段附加到一个先前的集束中,形成新的赋值。最后将k个结果记录在当前集束中。
2、LINK (Lines 8-16)
在每个附加步骤之后,算法向后查找,将新识别的实体提及和以前的实体提及(如果有的话)与关系弧联系起来。在第j个子步骤中,它只考虑在第j个前一个令牌结束的前一个提到。因此,不同的配置保证具有相同数量的子步骤。最后,使用新的关系信息对所有作业重新排序。
有m附加动作,每个后跟最多(i−1)链接操作(第8行)。因此最坏时间复杂度是O(ˆd·k·m2),其中ˆd表示段长度的上界。
3.1.2 Example Demonstration

图三:解码步骤的例子。x轴和y轴分别表示输入语句和实体类型。矩形用实体类型表示线段,其中阴影部分是三个相互竞争的假设,以“1400”结尾。实线和箭头分别表示正确的附加操作和链接操作,而虚线表示错误的操作。
在这里,我们通过再次考虑图1a中描述的句子来演示一个简单但具体的示例。假设我们处在令牌“1400”处。在这一点上,我们可以提出多个不同长度的实体提及。假设“1400 / PER”、“1400 / ?和“(employs,1400)/PER”是可能的分配,算法将这些新段分别附加到“雇用”和“仍然”令牌梁的部分分配中。图3说明了这个过程。为了简单起见,只给出了搜索空间的一小部分。然后,该算法将新识别的提及项链接到相同配置中的前一个提及项。在本例中,前面只提到了“(轮胎制造商)/ORG”。最后,由于“(轮胎制造商)/PER”和“1400 /PER”之间的EMP-ORG关系具有更多指示性的上下文特性,因此模型将首选“1400 /PER”。
3.2 Structured-Perceptron Learning
为了估计特征权值,我们使用结构化感知器(Collins, 2002)作为学习框架,它是用于结构化预测的标准感知器的扩展。Huang等人(2012)用earlyupdate等修正错误的更新方法证明了结构感知器在不精确搜索时的收敛性(Collins and Roark, 2004)。由于我们在这项工作中使用了集束搜索,所以我们应用了早期更新。此外,我们使用平均参数来减少过拟合,如(Collins, 2002)。

图四:感知器算法与集束搜索和早期更新。y0是金标准的前缀,z是顶部赋值。
图4显示了带有早期更新的结构化感知器训练的伪代码。这里BEAMSEARCH在图2中描述的解码算法是一样的,除了如果y0,黄金标准的前缀y,beam在每次执行k-BEST函数(7和16行)后,然后返回顶部作业z和y0参数更新。值得注意的是,这只有在黄金标准的一个部分在当前令牌结束时才会发生。例如,在图1a的示例中,B[2]不能触发任何早期更新,因为黄金标准不包含在第二个令牌处结束的任何段。
3.3 Entity Type Constraints
实体类型约束已被证明在预测关系方面是有效的(Roth和Yih, 2007;陈和罗斯,2010)。我们从训练数据中自动收集每个关系类型的允许实体类型的映射表。我们没有在后处理推理中应用约束,而是在搜索过程中删除了违反类型约束的分支。这种类型的修剪可以减少搜索空间,同时使参数更新的输入噪声更小。在我们的实验中,开发集中只有7个关系提及(0.5%),测试集中只有5个关系提及(0.3%)违反了从训练数据中收集的约束。
四、Features
我们的框架的一个优点是,我们可以很容易地利用这两个任务的任意特性。本节描述我们在本文中开发的局部特性(第4.1节)和全局特性(第4.2节)。
4.1 Local Features
我们设计了基于分段的特性来直接评估一个实体的属性,而不是它所包含的单个令牌。下面是一个基于分段的特征的例子:
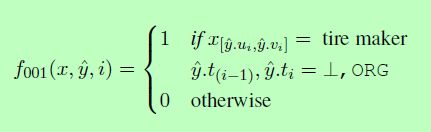
我们的基于分段的功能描述如下:
(1)Gazetteer features
实体类型的每个部分基于匹配的人,国家,城市和组织的地名。
(2)Case features
一段话是大写、小写还是混合?
(3)Contextual features
文本的一元语法和二元语法以及片段上下文窗口大小为2的词性标记。
(4)Parsing-based features
特性来源于组成解析树,包括(a)的短语类型最低的共同祖先中包含的令牌,(b)的深度最低的共同祖先,©二进制特征表明如果部分是基本短语或短语的后缀基地,和(d)的头文字段和相邻短语。
此外,我们将每个三重
4.2 Global Entity Mention Features
由于有效不精确的搜索,我们能够使用任意特性从整个结构ˆy捕捉长距离依赖性。在解码过程中,一旦添加了新的片段,就会提取相关实体提及之间的以下特征。
(1)Coreference consistency
参照的实体提及应该被分配相同的实体类型。我们使用一些简单的启发式规则来确定同一句子中两个片段之间的高回忆共参考链接:
- 完全或部分匹配两个段的字符串。
- 代词(如“their”、“it”)指的是前面提到的实体。例如,在“他们的汽车没有保险”中,“他们”和“他们的”应该具有相同的实体类型。
- 关系代词(例如“which”、“that”和“who”)指它在解析树中修饰的名词短语。例如,在《起跑者是nikita kargalskiy,他可能离他的家乡有5000英里远》中,“nikita kargalskiy”和“who”都应该被贴上“人”的标签。
然后对全局特性进行编码,以检查两个参照段是否共享相同的实体类型。这一特征对代词尤其有效,因为它们的上下文本身通常不能提供信息。
(2)Neighbor coherence
相邻的实体提及往往具有连贯的实体类型。例如,在“Barbara Starr was reporting from the Pentagon”中,“Barbara Starr”和“Pentagon”是由从属链接连接起来的,因此它们不太可能同时出现。考虑两种类型的邻居:(一)当前段之前提到的第一个实体,和(二)由单个单词或与当前段的依赖链接连接的段。我们把这两个部分的实体类型和链接作为一个全局特性。例如,“PER prep from PER”是上面例子中的一个特性,“Barbara Starr”和“Pentagon”都被标记为PER提及。
(3)Part-of-whole consistency
如果一个实体引用在语义上是另一个引用的一部分(通过依赖关系链接的prep连接),它们应该被分配相同的实体类型。例如,在“some of Iraq’s exiles”中,“some”和“exiles”都被提及;在“镇上两家肉类加工厂之一”中,“一家”和“两家”都被FAC提及;在“the rest of America”中,“rest”和“America”都被提到了GPE。
4.3 Global Relation Features
关系弧也可以共享相互依赖或服从软约束。当解码过程中产生新的关系假设时,我们提取了以下以关系为中心的全局特征。

(1)Role coherence
如果提到的实体涉及同一类型的多个关系,那么它的角色应该是一致的。例如,一份简历不可能有一个以上的雇主。然而,一个GPE提及可以是多个实体提及的物理位置。我们将关系类型和实体提到的参数角色组合为一个全局特性,如图5a所示。
(2)Triangle constraint
多个实体提到不太可能与相同的关系类型完全连接。我们使用一个负面特性来惩罚任何包含这种结构类型的配置。图5b显示了一个示例。
(3)Inter-dependent compatibility
如果两个实体被一个依赖链接连接起来,它们就会与其他实体有兼容的关系。例如,在图5c中,“索马里”和“科索沃”之间的conj和从属关系表明它们可能与提到的第三个实体“势力”具有相同的关系类型。
(4)Neighbor coherence
与实体提及的相邻连通性特征相似,我们也将两个相邻关系的类型在同一个句子中组合成双字母特征。
五、Experiments
5.1 Data and Scoring Metric
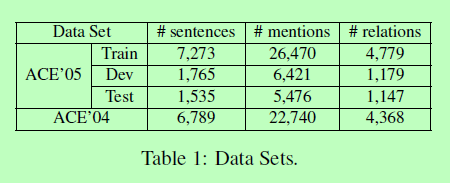
以前关于ACE关系提取的大部分工作都报告了ACE’04数据集的结果。我们将在稍后的实验中展示,ACE’05在关系类型定义和注释质量方面都有显著的改进。因此,我们给出了ACE ’ 05数据的整体表现。我们删除了两个非正式类型的小子集——cts和un,然后将剩余的511个文档随机分为3个部分:351个用于培训,80个用于开发,剩下的80个用于盲测。为了与最先进的技术进行比较,我们还对ACE ’ 04语料库的bnews和nwire子集进行了与之前工作相同的5倍交叉验证。这些数据集的统计汇总如表1所示。我们运行了Stanford CoreNLP工具包5来自动恢复小写文档的真实情况。
我们使用标准的F1度量来评估实体提及提取和关系提取的性能。如果实体的实体类型是正确的,并且它的提及头的偏移量是正确的,那么实体提及就被认为是正确的。如果关系类型正确,则关系提及被认为是正确的,并且两个实体提及参数的偏移量都是正确的。与Chan和Roth(2011)一样,我们排除了DISC关系类型,并删除了系统输出中的关系,这些关系通过共引用链接隐含地正确,以便进行公平比较。此外,我们结合这两个标准来评估端到端实体提及和关系提取的性能。
5.2 Development Results
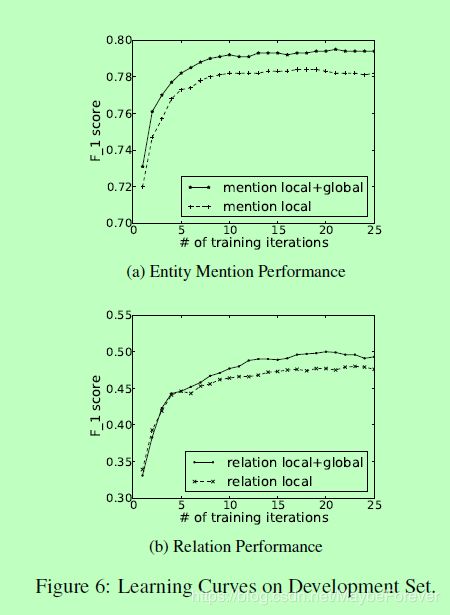
图六:Learning Curves on Development Set
一般来说,较大的集束尺寸可以产生更好的性能,但会增加训练和解码时间。作为折衷,我们在整个实验中将光束尺寸设置为8。图6显示了开发集上的学习曲线,并比较了具有和不具有全局特性的性能。从这些图中我们可以清楚地看到,全局特征不断地提高了两个任务的提取性能。根据这些曲线,我们将训练迭代次数设置为22次。
5.3 Overall Performance
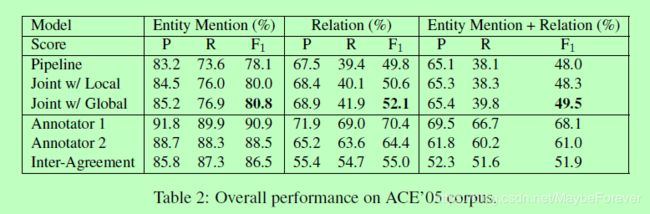
表二:Overall performance on ACE’05 corpus
表2展示了各种方法对ACE ’ 05测试数据的整体性能。我们将我们提出的方法(联合w/ Global)与流水线系统(Pipeline)、只具有局部特征的联合模型(联合w/ local)以及两个在ACE ’ 05语料库中注释了73个文档的人工标注者进行了比较。

图七:Two competing hypotheses for “a marcher from Florida” during decoding
我们可以看到,我们的方法在这两个任务上都显著优于流水线方法。作为一个真实的例子,对于来自测试数据的部分句子“a marcher from Florida”,流水线方法没有将“marcher”作为一个单独的提及,从而忽略了“marcher”和“Florida”之间的基本关系。我们的联合模型正确地识别了实体提及及其关系。图7显示了将联合模型应用到这句话时的细节。在标记“marcher”时,集束中最重要的假设是,而正确的答案是第二好的。解码器对令牌“佛罗里达”进行处理后,每gpe对的邻域相干特征将正确的假设提升到波束的顶部。此外,在通过GEN-AFF关系将两者联系起来之后,错误假设被降至第4位,从而使正确的假设相差很大。
F1在端到端关系提取上的得分只有70%左右,这说明这是一个非常具有挑战性的任务。此外,注释者间协议的F1评分为51.9%,仅比我们提出的方法高2.4%。
与人工标注方法相比,自动标注方法的瓶颈是关系提取的召回率低。在631个遗留的缺失关系中,有318个(50.3%)是由于缺失实体提及参数造成的。在培训数据中很少出现大量的名义提及头,如人员(“至上主义者”、“牧羊人”、“寡头”、“富人”)、地缘政治实体(“美国本土”)、设施(“路障”、“细胞”)、武器(“sim lant”、“核武器”)和车辆(“婴车”)。此外,关系常常以各种形式含蓄地表达出来。以下是一些例子:
- “赖斯已被布什总统选为新国务卿”表明“赖斯”与“布什”有密切关系。
- “美国这表明“军队”与“巴格达”之间存在“物理关系”。
- “俄罗斯和法国向巴格达派遣飞机”表明“俄罗斯”和“法国”与“飞机”的所有者存在艺术关系。
除了上下文特征外,还需要更深层次的语义知识来捕捉这种隐含的语义关系。
5.4 Comparison with State-of-the-art
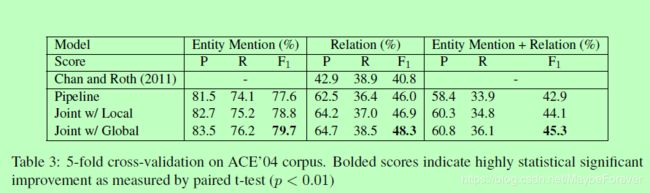
表3比较了ACE ’ 04语料库的性能。对于实体提及提取,我们的联合模型在5次交叉验证中获得了79.7%的结果,与(Florian et al., 2006)在单次重复验证中获得的最佳F1分数79.2%相当。然而,Florian et al.(2006)使用一些地名辞典和其他信息提取(IE)模型的输出作为附加特征,这提供了显著的收益(Florian et al., 2004)。由于这些gazetteers,额外的数据集和外部的IE模型都不是公开的,直接将我们的联合模型和他们的结果进行比较是不公平的。
对于端到端实体提及和关系提取,在相同的设置下,联合方法和流水线基线都优于(Chan和Roth, 2011)的最佳结果。
六、Related Work
实体提及提取(e.g., (Florian et al., 2004;Florian et al., 2006;Florian et al., 2010;Zitouni和Florian, 2008;Ohta et al., 2012))和关系提取(例如,(Reichartz et al., 2009;Sun et al., 2011;江和翟,2007;Bunescu和Mooney, 2005;赵和Grishman, 2005年;库洛塔和索伦森,2004年;周等,2007;钱,周,2010;钱等,2008;陈和罗斯,2011年;普兰克和莫斯科提,2013))近年来备受关注,但通常是单独研究。大多数关系提取工作假设实体提及边界和/或类型被给定。Chan和Roth(2011)报告了使用预测实体提及率的最佳结果。
之前的一些工作使用关系和实体提及在联合推理框架中相互增强,包括重新排序(Ji和Grishman, 2005),整数线性规划(ILP) (Roth和Yih, 2004;罗斯和Yih, 2007;Yang和Cardie, 2013),和卡片金字塔解析(Kate和Mooney, 2010)。所有这些工作都指出了利用跨组件交互和更丰富的知识的优点。然而,他们依赖于为每个子任务分别学习的模型。作为一个关键的区别,我们的方法联合提取实体提及和关系使用一个单一的模型,其中任意的软约束可以很容易地纳入。其他一些工作将概率图形模型应用于联合提取(e.g., (Singh et al., 2013;Yu和Lam, 2010))。相比之下,我们的工作采用了一种高效的联合搜索算法,没有对多个变量的联合分布进行建模,因此更灵活,计算更简单。此外,(Singh et al., 2013)使用了goldstandard提边界。
我们之前的工作(Li et al., 2013)使用基于标记的解码器的结构化感知器,基于实体提及和其他候选参数作为输入的一部分的假设,联合预测事件触发器和参数。在本文中,我们解决了一个更具挑战性的问题:以原始文本为输入,在一个单一的模型中识别边界、实体提及的类型和关系。Sarawagi和Cohen(2004)提出了一种基于节段的CRFs模型用于名称标记。Zhang和Clark(2008)使用基于分段的解码器进行分词和词性标注。我们将类似的思想扩展到端到端任务中,通过增量地预测关系和实体提及段。
七、Conclusions and Future Work
在本文中,我们介绍了一种新的体系结构,用于更强大的端到端实体提及和关系提取。我们第一次使用增量集束搜索算法和结构化感知器来解决这个具有挑战性的任务。当与其他组件联合检测提边界时,对同一波束内的多个任务同步提出了挑战,采用了一种简单而有效的基于分段的解码器来解决这个问题。更重要的是,我们利用了一组基于这两个任务的语言和逻辑属性的全局特征来预测更一致的结构。实验表明,我们的方法在这两种任务上都明显优于流水线方法,并且具有非常先进的技术水平。
在未来的工作中,我们计划探索更多的软约束和硬约束,以减少搜索空间,提高准确性。此外,我们的目标是将其他IE组件(如事件提取)合并到联合模型中。