50个数据可视化最有价值的图表(附完整Python代码,建议收藏)(上)
欢迎关注天善智能,我们是专注于商业智能BI,人工智能AI,大数据分析与挖掘领域的垂直社区,学习,问答、求职一站式搞定!
对商业智能BI、大数据分析挖掘、机器学习,python,R等数据领域感兴趣的同学加微信:tstoutiao,邀请你进入数据爱好者交流群,数据爱好者们都在这儿。
作者:lemonbit
微信公众号:Python数据之道

from Unsplash by @Mike Enerio
翻译 | Lemon
来源 | Machine Learning Plus
本文总结了 Matplotlib 以及 Seaborn 用的最多的50个图形,掌握这些图形的绘制,对于数据分析的可视化有莫大的作用,强烈推荐大家阅读后续内容。
如果觉得内容不错,欢迎分享到您的朋友圈。
Tips:
(1)本文原文部分代码有不准确的地方,已进行修改;
(2)所有正确的源代码,我已整合到 jupyter notebook 文件中,可以在公众号『Python数据之道』后台回复 “code”,可获得本文源代码;
(3)运行本文代码,除了安装 matplotlib 和 seaborn 可视化库外,还需要安装其他的一些辅助可视化库,已在代码部分作标注,具体内容请查看下面文章内容。
(4)由于微信文章总字数不能超过5万字,删除了部分代码,完整的文章请点击文章底部的阅读原文;
在数据分析和可视化中最有用的 50 个 Matplotlib 图表。 这些图表列表允许您使用 python 的 matplotlib 和 seaborn 库选择要显示的可视化对象。
介绍
这些图表根据可视化目标的7个不同情景进行分组。 例如,如果要想象两个变量之间的关系,请查看“关联”部分下的图表。 或者,如果您想要显示值如何随时间变化,请查看“变化”部分,依此类推。
有效图表的重要特征:
在不歪曲事实的情况下传达正确和必要的信息。
设计简单,您不必太费力就能理解它。
从审美角度支持信息而不是掩盖信息。
信息没有超负荷。
准备工作
在代码运行前先引入下面的设置内容。 当然,单独的图表,可以重新设置显示要素。
# !pip install brewer2mplimport numpy as npimport pandas as pdimport matplotlib as mplimport matplotlib.pyplot as pltimport seaborn as snsimport warnings; warnings.filterwarnings(action='once')large = 22; med = 16; small = 12params = {'axes.titlesize': large,'legend.fontsize': med,'figure.figsize': (16, 10),'axes.labelsize': med,'axes.titlesize': med,'xtick.labelsize': med,'ytick.labelsize': med,'figure.titlesize': large}plt.rcParams.update(params)plt.style.use('seaborn-whitegrid')sns.set_style("white")%matplotlib inline# Versionprint(mpl.__version__) #> 3.0.0print(sns.__version__) #> 0.9.0
3.0.20.9.0
一、关联 (Correlation)
关联图表用于可视化2个或更多变量之间的关系。 也就是说,一个变量如何相对于另一个变化。
1 散点图(Scatter plot)
散点图是用于研究两个变量之间关系的经典的和基本的图表。 如果数据中有多个组,则可能需要以不同颜色可视化每个组。 在 matplotlib 中,您可以使用 plt.scatterplot() 方便地执行此操作。
# Import datasetmidwest = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv")# Prepare Data# Create as many colors as there are unique midwest['category']categories = np.unique(midwest['category'])colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]# Draw Plot for Each Categoryplt.figure(figsize=(16, 10), dpi= 80, facecolor='w', edgecolor='k')for i, category in enumerate(categories):plt.scatter('area', 'poptotal',data=midwest.loc[midwest.category==category, :],s=20, cmap=colors[i], label=str(category))# "c=" 修改为 "cmap=",Python数据之道 备注# Decorationsplt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000),xlabel='Area', ylabel='Population')plt.xticks(fontsize=12); plt.yticks(fontsize=12)plt.title("Scatterplot of Midwest Area vs Population", fontsize=22)plt.legend(fontsize=12)plt.show()

图1
2 带边界的气泡图(Bubble plot with Encircling)
有时,您希望在边界内显示一组点以强调其重要性。 在这个例子中,你从数据框中获取记录,并用下面代码中描述的 encircle() 来使边界显示出来。
from matplotlib import patchesfrom scipy.spatial import ConvexHullimport warnings; warnings.simplefilter('ignore')sns.set_style("white")# Step 1: Prepare Datamidwest = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv")# As many colors as there are unique midwest['category']categories = np.unique(midwest['category'])colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]# Step 2: Draw Scatterplot with unique color for each categoryfig = plt.figure(figsize=(16, 10), dpi= 80, facecolor='w', edgecolor='k')for i, category in enumerate(categories):plt.scatter('area', 'poptotal', data=midwest.loc[midwest.category==category, :],s='dot_size', cmap=colors[i], label=str(category), edgecolors='black', linewidths=.5)# "c=" 修改为 "cmap=",Python数据之道 备注# Step 3: Encircling# https://stackoverflow.com/questions/44575681/how-do-i-encircle-different-data-sets-in-scatter-plotdef encircle(x,y, ax=None, **kw):if not ax: ax=plt.gca()p = np.c_[x,y]hull = ConvexHull(p)poly = plt.Polygon(p[hull.vertices,:], **kw)ax.add_patch(poly)# Select data to be encircledmidwest_encircle_data = midwest.loc[midwest.state=='IN', :]# Draw polygon surrounding verticesencircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="k", fc="gold", alpha=0.1)encircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="firebrick", fc="none", linewidth=1.5)# Step 4: Decorationsplt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000),xlabel='Area', ylabel='Population')plt.xticks(fontsize=12); plt.yticks(fontsize=12)plt.title("Bubble Plot with Encircling", fontsize=22)plt.legend(fontsize=12)plt.show()

图2
3 带线性回归最佳拟合线的散点图 (Scatter plot with linear regression line of best fit)
如果你想了解两个变量如何相互改变,那么最佳拟合线就是常用的方法。 下图显示了数据中各组之间最佳拟合线的差异。 要禁用分组并仅为整个数据集绘制一条最佳拟合线,请从下面的 sns.lmplot()调用中删除 hue ='cyl'参数。
# Import Datadf = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")df_select = df.loc[df.cyl.isin([4,8]), :]# Plotsns.set_style("white")gridobj = sns.lmplot(x="displ", y="hwy", hue="cyl", data=df_select,height=7, aspect=1.6, robust=True, palette='tab10',scatter_kws=dict(s=60, linewidths=.7, edgecolors='black'))# Decorationsgridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))plt.title("Scatterplot with line of best fit grouped by number of cylinders", fontsize=20)plt.show()

图3
针对每列绘制线性回归线
或者,可以在其每列中显示每个组的最佳拟合线。 可以通过在 sns.lmplot() 中设置 col=groupingcolumn 参数来实现,如下:
# Import Datadf = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")df_select = df.loc[df.cyl.isin([4,8]), :]# Each line in its own columnsns.set_style("white")gridobj = sns.lmplot(x="displ", y="hwy",data=df_select,height=7,robust=True,palette='Set1',col="cyl",scatter_kws=dict(s=60, linewidths=.7, edgecolors='black'))# Decorationsgridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))plt.show()
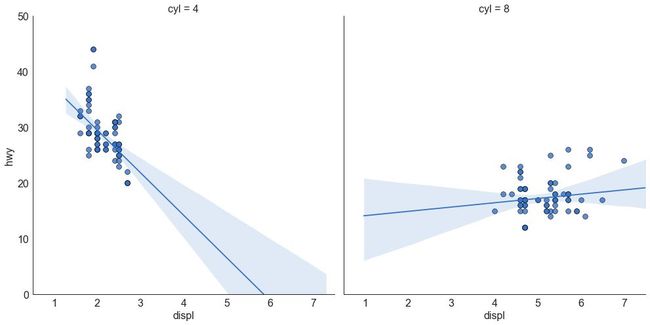
图3-2
4 抖动图 (Jittering with stripplot)
通常,多个数据点具有完全相同的 X 和 Y 值。 结果,多个点绘制会重叠并隐藏。 为避免这种情况,请将数据点稍微抖动,以便您可以直观地看到它们。 使用 seaborn 的 stripplot() 很方便实现这个功能。
# Import Datadf = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")# Draw Stripplotfig, ax = plt.subplots(figsize=(16,10), dpi= 80)sns.stripplot(df.cty, df.hwy, jitter=0.25, size=8, ax=ax, linewidth=.5)# Decorationsplt.title('Use jittered plots to avoid overlapping of points', fontsize=22)plt.show()

图4
5 计数图 (Counts Plot)
避免点重叠问题的另一个选择是增加点的大小,这取决于该点中有多少点。 因此,点的大小越大,其周围的点的集中度越高。
# Import Datadf = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")df_counts = df.groupby(['hwy', 'cty']).size().reset_index(name='counts')# Draw Stripplotfig, ax = plt.subplots(figsize=(16,10), dpi= 80)sns.stripplot(df_counts.cty, df_counts.hwy, size=df_counts.counts*2, ax=ax)# Decorationsplt.title('Counts Plot - Size of circle is bigger as more points overlap', fontsize=22)plt.show()

图5
6 边缘直方图 (Marginal Histogram)
边缘直方图具有沿 X 和 Y 轴变量的直方图。 这用于可视化 X 和 Y 之间的关系以及单独的 X 和 Y 的单变量分布。 这种图经常用于探索性数据分析(EDA)。

图6
7 边缘箱形图 (Marginal Boxplot)
边缘箱图与边缘直方图具有相似的用途。 然而,箱线图有助于精确定位 X 和 Y 的中位数、第25和第75百分位数。
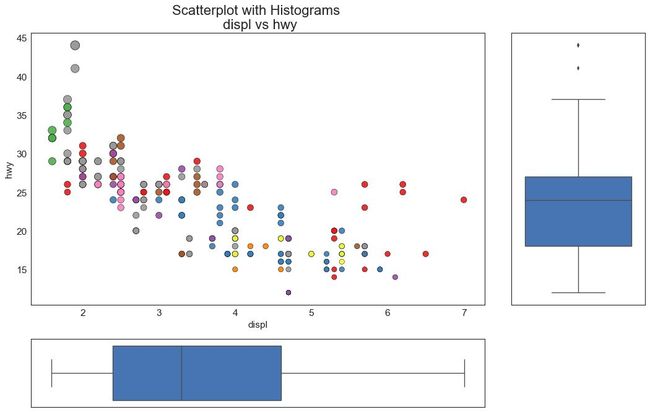
图7
8 相关图 (Correllogram)
相关图用于直观地查看给定数据框(或二维数组)中所有可能的数值变量对之间的相关度量。
# Import Datasetdf = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")# Plotplt.figure(figsize=(12,10), dpi= 80)sns.heatmap(df.corr(), xticklabels=df.corr().columns, yticklabels=df.corr().columns, cmap='RdYlGn', center=0, annot=True)# Decorationsplt.title('Correlogram of mtcars', fontsize=22)plt.xticks(fontsize=12)plt.yticks(fontsize=12)plt.show()

图8
9 矩阵图 (Pairwise Plot)
矩阵图是探索性分析中的最爱,用于理解所有可能的数值变量对之间的关系。 它是双变量分析的必备工具。
# Load Datasetdf = sns.load_dataset('iris')# Plotplt.figure(figsize=(10,8), dpi= 80)sns.pairplot(df, kind="scatter", hue="species", plot_kws=dict(s=80, edgecolor="white", linewidth=2.5))plt.show()
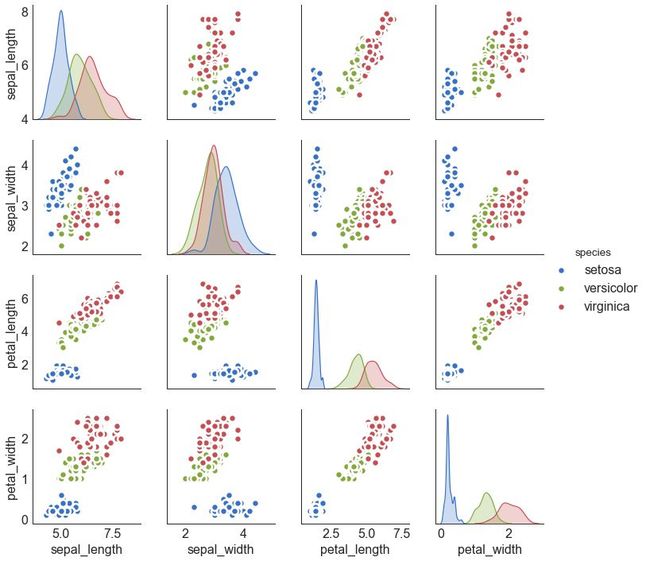
图9
# Load Datasetdf = sns.load_dataset('iris')# Plotplt.figure(figsize=(10,8), dpi= 80)sns.pairplot(df, kind="reg", hue="species")plt.show()
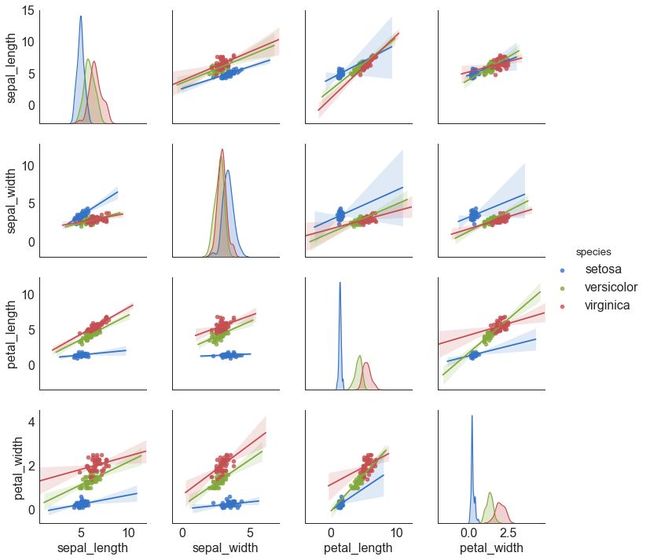
图9-2
二、偏差 (Deviation)
10 发散型条形图 (Diverging Bars)
如果您想根据单个指标查看项目的变化情况,并可视化此差异的顺序和数量,那么散型条形图 (Diverging Bars) 是一个很好的工具。 它有助于快速区分数据中组的性能,并且非常直观,并且可以立即传达这一点。
# Prepare Datadf = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")x = df.loc[:, ['mpg']]df['mpg_z'] = (x - x.mean())/x.std()df['colors'] = ['red' if x < 0 else 'green' for x in df['mpg_z']]df.sort_values('mpg_z', inplace=True)df.reset_index(inplace=True)# Draw plotplt.figure(figsize=(14,10), dpi= 80)plt.hlines(y=df.index, xmin=0, xmax=df.mpg_z, color=df.colors, alpha=0.4, linewidth=5)# Decorationsplt.gca().set(ylabel='$Model$', xlabel='$Mileage$')plt.yticks(df.index, df.cars, fontsize=12)plt.title('Diverging Bars of Car Mileage', fontdict={'size':20})plt.grid(linestyle='--', alpha=0.5)plt.show()

图10
11 发散型文本 (Diverging Texts)
发散型文本 (Diverging Texts)与发散型条形图 (Diverging Bars)相似,如果你想以一种漂亮和可呈现的方式显示图表中每个项目的价值,就可以使用这种方法。
# Prepare Datadf = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")x = df.loc[:, ['mpg']]df['mpg_z'] = (x - x.mean())/x.std()df['colors'] = ['red' if x < 0 else 'green' for x in df['mpg_z']]df.sort_values('mpg_z', inplace=True)df.reset_index(inplace=True)# Draw plotplt.figure(figsize=(14,14), dpi= 80)plt.hlines(y=df.index, xmin=0, xmax=df.mpg_z)for x, y, tex in zip(df.mpg_z, df.index, df.mpg_z):t = plt.text(x, y, round(tex, 2), horizontalalignment='right' if x < 0 else 'left',verticalalignment='center', fontdict={'color':'red' if x < 0 else 'green', 'size':14})# Decorationsplt.yticks(df.index, df.cars, fontsize=12)plt.title('Diverging Text Bars of Car Mileage', fontdict={'size':20})plt.grid(linestyle='--', alpha=0.5)plt.xlim(-2.5, 2.5)plt.show()
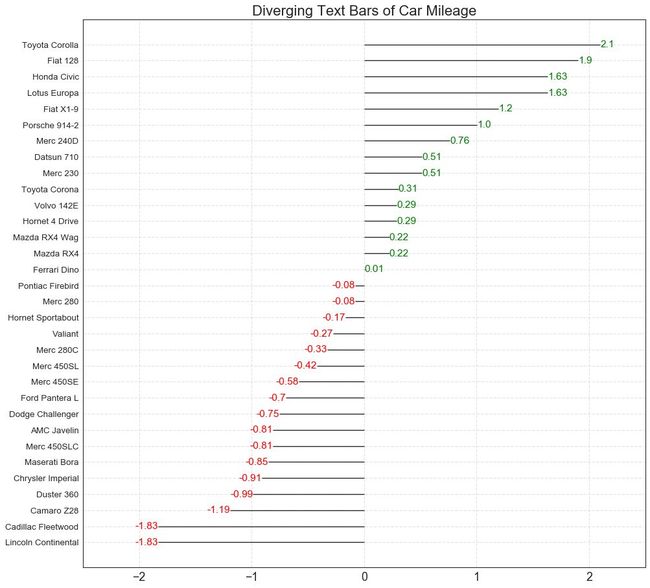
图11
12 发散型包点图 (Diverging Dot Plot)
发散型包点图 (Diverging Dot Plot)也类似于发散型条形图 (Diverging Bars)。 然而,与发散型条形图 (Diverging Bars)相比,条的缺失减少了组之间的对比度和差异。
# Prepare Datadf = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")x = df.loc[:, ['mpg']]df['mpg_z'] = (x - x.mean())/x.std()df['colors'] = ['red' if x < 0 else 'darkgreen' for x in df['mpg_z']]df.sort_values('mpg_z', inplace=True)df.reset_index(inplace=True)# Draw plotplt.figure(figsize=(14,16), dpi= 80)plt.scatter(df.mpg_z, df.index, s=450, alpha=.6, color=df.colors)for x, y, tex in zip(df.mpg_z, df.index, df.mpg_z):t = plt.text(x, y, round(tex, 1), horizontalalignment='center',verticalalignment='center', fontdict={'color':'white'})# Decorations# Lighten bordersplt.gca().spines["top"].set_alpha(.3)plt.gca().spines["bottom"].set_alpha(.3)plt.gca().spines["right"].set_alpha(.3)plt.gca().spines["left"].set_alpha(.3)plt.yticks(df.index, df.cars)plt.title('Diverging Dotplot of Car Mileage', fontdict={'size':20})plt.xlabel('$Mileage$')plt.grid(linestyle='--', alpha=0.5)plt.xlim(-2.5, 2.5)plt.show()

图12
13 带标记的发散型棒棒糖图 (Diverging Lollipop Chart with Markers)
带标记的棒棒糖图通过强调您想要引起注意的任何重要数据点并在图表中适当地给出推理,提供了一种对差异进行可视化的灵活方式。

图13
14 面积图 (Area Chart)
通过对轴和线之间的区域进行着色,面积图不仅强调峰和谷,而且还强调高点和低点的持续时间。 高点持续时间越长,线下面积越大。
import numpy as npimport pandas as pd# Prepare Datadf = pd.read_csv("https://github.com/selva86/datasets/raw/master/economics.csv", parse_dates=['date']).head(100)x = np.arange(df.shape[0])y_returns = (df.psavert.diff().fillna(0)/df.psavert.shift(1)).fillna(0) * 100# Plotplt.figure(figsize=(16,10), dpi= 80)plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] >= 0, facecolor='green', interpolate=True, alpha=0.7)plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] <= 0, facecolor='red', interpolate=True, alpha=0.7)# Annotateplt.annotate('Peak
1975', xy=(94.0, 21.0), xytext=(88.0, 28),bbox=dict(boxstyle='square', fc='firebrick'),arrowprops=dict(facecolor='steelblue', shrink=0.05), fontsize=15, color='white')# Decorationsxtickvals = [str(m)[:3].upper()+"-"+str(y) for y,m in zip(df.date.dt.year, df.date.dt.month_name())]plt.gca().set_xticks(x[::6])plt.gca().set_xticklabels(xtickvals[::6], rotation=90, fontdict={'horizontalalignment': 'center', 'verticalalignment': 'center_baseline'})plt.ylim(-35,35)plt.xlim(1,100)plt.title("Month Economics Return %", fontsize=22)plt.ylabel('Monthly returns %')plt.grid(alpha=0.5)plt.show()

图14
三、排序 (Ranking)
15 有序条形图 (Ordered Bar Chart)
有序条形图有效地传达了项目的排名顺序。 但是,在图表上方添加度量标准的值,用户可以从图表本身获取精确信息。

图15
16 棒棒糖图 (Lollipop Chart)
棒棒糖图表以一种视觉上令人愉悦的方式提供与有序条形图类似的目的。
# Prepare Datadf_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x: x.mean())df.sort_values('cty', inplace=True)df.reset_index(inplace=True)# Draw plotfig, ax = plt.subplots(figsize=(16,10), dpi= 80)ax.vlines(x=df.index, ymin=0, ymax=df.cty, color='firebrick', alpha=0.7, linewidth=2)ax.scatter(x=df.index, y=df.cty, s=75, color='firebrick', alpha=0.7)# Title, Label, Ticks and Ylimax.set_title('Lollipop Chart for Highway Mileage', fontdict={'size':22})ax.set_ylabel('Miles Per Gallon')ax.set_xticks(df.index)ax.set_xticklabels(df.manufacturer.str.upper(), rotation=60, fontdict={'horizontalalignment': 'right', 'size':12})ax.set_ylim(0, 30)# Annotatefor row in df.itertuples():ax.text(row.Index, row.cty+.5, s=round(row.cty, 2), horizontalalignment= 'center', verticalalignment='bottom', fontsize=14)plt.show()

图16
17 包点图 (Dot Plot)
包点图表传达了项目的排名顺序,并且由于它沿水平轴对齐,因此您可以更容易地看到点彼此之间的距离。
# Prepare Datadf_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x: x.mean())df.sort_values('cty', inplace=True)df.reset_index(inplace=True)# Draw plotfig, ax = plt.subplots(figsize=(16,10), dpi= 80)ax.hlines(y=df.index, xmin=11, xmax=26, color='gray', alpha=0.7, linewidth=1, linestyles='dashdot')ax.scatter(y=df.index, x=df.cty, s=75, color='firebrick', alpha=0.7)# Title, Label, Ticks and Ylimax.set_title('Dot Plot for Highway Mileage', fontdict={'size':22})ax.set_xlabel('Miles Per Gallon')ax.set_yticks(df.index)ax.set_yticklabels(df.manufacturer.str.title(), fontdict={'horizontalalignment': 'right'})ax.set_xlim(10, 27)plt.show()

图17
18 坡度图 (Slope Chart)
坡度图最适合比较给定人/项目的“前”和“后”位置。

图18
19 哑铃图 (Dumbbell Plot)
哑铃图表传达了各种项目的“前”和“后”位置以及项目的等级排序。 如果您想要将特定项目/计划对不同对象的影响可视化,那么它非常有用。

图19
四、分布 (Distribution)
20 连续变量的直方图 (Histogram for Continuous Variable)
直方图显示给定变量的频率分布。 下面的图表示基于类型变量对频率条进行分组,从而更好地了解连续变量和类型变量。
# Import Datadf = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")# Prepare datax_var = 'displ'groupby_var = 'class'df_agg = df.loc[:, [x_var, groupby_var]].groupby(groupby_var)vals = [df[x_var].values.tolist() for i, df in df_agg]# Drawplt.figure(figsize=(16,9), dpi= 80)colors = [plt.cm.Spectral(i/float(len(vals)-1)) for i in range(len(vals))]n, bins, patches = plt.hist(vals, 30, stacked=True, density=False, color=colors[:len(vals)])# Decorationplt.legend({group:col for group, col in zip(np.unique(df[groupby_var]).tolist(), colors[:len(vals)])})plt.title(f"Stacked Histogram of ${x_var}$ colored by ${groupby_var}$", fontsize=22)plt.xlabel(x_var)plt.ylabel("Frequency")plt.ylim(0, 25)plt.xticks(ticks=bins[::3], labels=[round(b,1) for b in bins[::3]])plt.show()

图20
21 类型变量的直方图 (Histogram for Categorical Variable)
类型变量的直方图显示该变量的频率分布。 通过对条形图进行着色,可以将分布与表示颜色的另一个类型变量相关联。
# Import Datadf = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")# Prepare datax_var = 'manufacturer'groupby_var = 'class'df_agg = df.loc[:, [x_var, groupby_var]].groupby(groupby_var)vals = [df[x_var].values.tolist() for i, df in df_agg]# Drawplt.figure(figsize=(16,9), dpi= 80)colors = [plt.cm.Spectral(i/float(len(vals)-1)) for i in range(len(vals))]n, bins, patches = plt.hist(vals, df[x_var].unique().__len__(), stacked=True, density=False, color=colors[:len(vals)])# Decorationplt.legend({group:col for group, col in zip(np.unique(df[groupby_var]).tolist(), colors[:len(vals)])})plt.title(f"Stacked Histogram of ${x_var}$ colored by ${groupby_var}$", fontsize=22)plt.xlabel(x_var)plt.ylabel("Frequency")plt.ylim(0, 40)plt.xticks(ticks=bins, labels=np.unique(df[x_var]).tolist(), rotation=90, horizontalalignment='left')plt.show()

图21
22 密度图 (Density Plot)
密度图是一种常用工具,用于可视化连续变量的分布。 通过“响应”变量对它们进行分组,您可以检查 X 和 Y 之间的关系。以下情况用于表示目的,以描述城市里程的分布如何随着汽缸数的变化而变化。
# Import Datadf = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")# Draw Plotplt.figure(figsize=(16,10), dpi= 80)sns.kdeplot(df.loc[df['cyl'] == 4, "cty"], shade=True, color="g", label="Cyl=4", alpha=.7)sns.kdeplot(df.loc[df['cyl'] == 5, "cty"], shade=True, color="deeppink", label="Cyl=5", alpha=.7)sns.kdeplot(df.loc[df['cyl'] == 6, "cty"], shade=True, color="dodgerblue", label="Cyl=6", alpha=.7)sns.kdeplot(df.loc[df['cyl'] == 8, "cty"], shade=True, color="orange", label="Cyl=8", alpha=.7)# Decorationplt.title('Density Plot of City Mileage by n_Cylinders', fontsize=22)plt.legend()plt.show()

图22
Python的爱好者社区历史文章大合集:
2018年Python爱好者社区历史文章合集(作者篇)
关注后在公众号内回复“ 课程 ”即可获取:
小编的转行入职数据科学(数据分析挖掘/机器学习方向)【最新免费】
小编的Python的入门免费视频课程!
小编的Python的快速上手matplotlib可视化库!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告扩展制作免费学习视频。
玩转大数据分析!Spark2.X + Python精华实战课程免费学习视频。
