一年的打磨,MNN正式版发布!

作者|MNN团队
出品|阿里巴巴新零售淘系技术部
MNN 的诞生源于淘系技术部的一群对技术充满热情的同学,在充分的行业调研后认为当时的推理引擎如 TFLite 不足以满足手机淘宝这样一个亿级用户与日活的超级 App 。
于是我们从零开始自己搭建了属于阿里巴巴的推理引擎 MNN 。1年前的这个时候,MNN 在 Github 上开源【1】。它比其他的推理引擎更快更轻量,更符合手机淘宝这样庞大、复杂的生产部署环境。今年3月份,MNN 的引擎设计与优化理念还获得了学术界的认可,在 MLSys 2020 【2】上发表了论文,并进行了 oral presentation 。
开源1年以来,获益于公司内外的用户反馈和业务推动,MNN 在许多方面都取得了长足的进步:
1. 在阿里巴巴集团内部得到广泛推广,成为了端上推理引擎的事实标准,覆盖了如手机淘宝、手机天猫、优酷、钉钉、闲鱼等20多个 App 。
2. 新添了模型训练的支持,从此 MNN 不再是单纯的推理引擎,而是具有推理+训练能力的深度学习引擎。基于 MNN 的训练能力,我们可以进行 Quantization-Aware Training(QAT)。在 MobileNet 上,MNN 量化训练之后的模型准确率几乎不降。
3. 持续投资于异构硬件后端的优化,尤其是利用 ARMv8.2 指令集,获得了两倍的性能提升。
4. 进一步完善 Python 工具链,累计新增超过 150 个接口。
5. 开源了应用层开箱即用的解决方案 MNNKit【3】,包含了人脸跟踪与检测、人像分割、手势识别场景的解决方案。
6. 开办了三期《 MNN 学院》直播(1期【4】, 2期【5】, 3期【6】),增加了与用户们交流,也获得了忠粉们的大量高质量反馈意见。
截止到今天,MNN 在开源社区获得了近 4000 的 Github Stars,这是大家对我们的工作所投的 4000 张认可票,也是鞭策我们完善 MNN 的动力。近日,MNN 发布了 1.0.0 正式版本。自此,MNN 不再被 Github 贴上 “Pre-release” 的标签了!相较于0.2.2版本,1.0.0 版本的主要升级在于:模型训练、异构性能和 Python 工具链。下面,我们逐项说明。
模型训练
▐ 模型构建
MNN支持使用 Express (表达式)接口来构建模型,如下例所示,接口还是比较简洁明了的。模型的构建、训练和保存具体可以参考说明文档【7】。
VARP x = inputs[0];
x = conv1->forward(x);
x = _MaxPool(x, {2, 2}, {2, 2});
x = conv2->forward(x);
x = _MaxPool(x, {2, 2}, {2, 2});
x = _Convert(x, NCHW);
x = _Reshape(x, {0, -1});
x = ip1->forward(x);
x = _Relu(x);
x = dropout->forward(x);
x = ip2->forward(x);
x = _Softmax(x, 1);
return {x};
以 MNIST 数据集 + Lenet 网络为例,一个 epoch 60000 张图片,一般可达到 97-98% 的准确率。性能上,同款 MBP 上,MNN 比 PyTorch 和 Caffe 都有明显优势;而手机上,MNN 也达到了完全可用的性能水准。

▐ 量化训练
模型量化既可以降低模型大小,又可以利用硬件特性提升推理性能,可谓业务应用必备之选。但美中不足之处在于,模型量化会带来一定的精度损失 —— 对于精度攸关的项目,就难免要做出艰难的选择了。
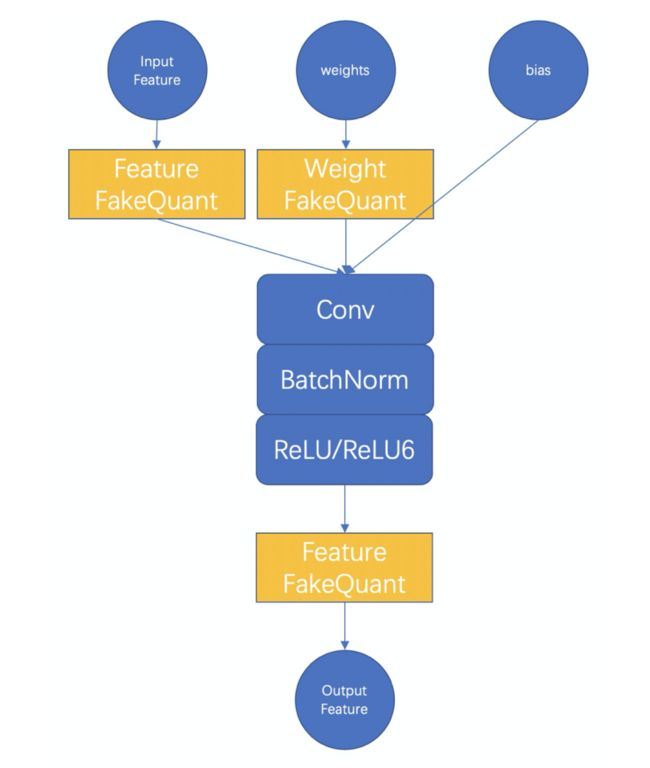
为此,MNN 借助自身模型训练能力,实现了模型训练量化,具体实现可以参考说明文档【8】。精度和压缩率方面,我们以 MobileNet V2 为例说明:
模型 |
类型 |
准确率 |
模型大小 |
原始模型 |
float32 |
72.324% |
13M |
MNN 训练量化模型 |
symm int8 |
72.456% |
3.5M |
TensorFlow 训练量化模型 |
symm int8 |
71.1% |
3.5M |
注1:训练和验证均采用 ImageNet 数据集。训练采用32为 batchsize,执行100个迭代,即,使用了 3200 张图片进行训练;精度验证则使用了 50000 张图片。
注2:原始模型为 TensorFlow 官方模型,官方准确率为 71.8%,但因预处理代码上有细微差别,我们测试原始模型的准确率结果稍高于官方;
可以看出,在实现了 73% 模型尺寸压缩的情况下,量化模型的精度甚至要稍高于原始模型。
▐ 迁移学习示例
这里节选 MobileNet V2 的 4 分类迁移学习示例,来说明模型的 Finetune,完整示例请参考文档【9】。
class MobilenetV2TransferModule : public Module {
public:
MobilenetV2TransferModule(const char* fileName) {
// 读取原始MobilenetV2模型
auto varMap = Variable::loadMap(fileName);
// MobilenetV2的输入节点
auto input = Variable::getInputAndOutput(varMap).first.begin()->second;
// MobilenetV2分类层之前的节点,AveragePooling的输出
auto lastVar = varMap["MobilenetV2/Logits/AvgPool"];
// 初始化一个4分类的全连接层,MNN中可以用卷积来表示全连接层
NN::ConvOption option;
option.channel = {1280, 4};
mLastConv = std::shared_ptr(NN::Conv(option));
// 初始化内部特征提取器, 内部提取器设成不需要训练
mFix.reset(PipelineModule::extract({input}, {lastVar}, false));
// 注意这里只注册了我们新初始化的4分类全连接层,那么训练时将只更新此4分类全连接层
registerModel({mLastConv});
}
virtual std::vector onForward(const std::vector& inputs) override {
// 输入一张图片,获得MobilenetV2特征提取器的输出
auto pool = mFix->forward(inputs[0]);
// 将上面提取的特征输入到新初始化的4分类层进行分类
auto result = _Softmax(_Reshape(_Convert(mLastConv->forward(pool), NCHW), {0, -1}));
return {result};
}
// MobilenetV2特征提取器,从输入一直到最后一个AveragePooling
std::shared_ptr mFix;
// 重新初始化的4分类全连接层
std::shared_ptr mLastConv;
};
int main(int argc, const char* argv[]) {
std::string trainImagesFolder = argv[2];
std::string trainImagesTxt = argv[3];
std::string testImagesFolder = argv[4];
std::string testImagesTxt = argv[5];
// 读取模型,并替换最后一层分类层
std::shared_ptr model(new MobilenetV2TransferModule(argv[1])); // arg1: /path/to/mobilenetV2Model
// 进入训练环节
MobilenetV2Utils::train(model, 4, 0, trainImagesFolder, trainImagesTxt, testImagesFolder, testImagesTxt);
return 0;
}
异构性能
▐ x86
在 x86 上,我们重点优化了矩阵乘法。在分析过 AVX 和 Arm 向量乘指令差异后,我们修改了 AVX 下的权重矩阵布局,降低了 I/O 布局,以充分利用 CPU 算力。
此外,我们允许在支持 FMA 扩展的设备上,启用扩展,将乘法和加法合为一条指令,以进一步降低指令耗时。
当前,FMA 扩展的启用开关还放置在 CMakeLists.txt 中,后续会在运行时判别。

综合两项优化,x86 上有 30% 左右的性能优化。
▐ ARM64
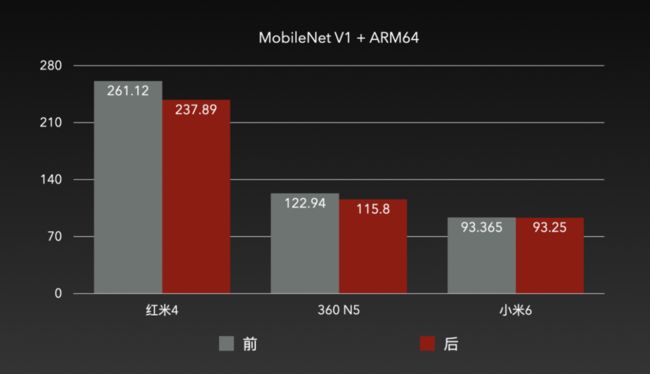
在 ARM64 上,我们面向中低端设备,调整了矩阵乘法的分块策略,矩阵中每个元素的均摊 I/O 降低了22%;同时,将数据对齐从32字节调整为64字节,与 ARM 架构 CPU 下场景的 L1 cacheline 匹配;最后,优化了缓存预取。优化结果如下:
▐ ARMv8.2
ARM 在「Bringing Armv8.2Instructions to Android Runtime」【10】一文中,列举了可以在 Android 运行时中应用的 ARMv8.2 新特性。其中,FP16 extensions和Dot Product可以分别应用于浮点计算加速和量化计算加速。
FP16extensions
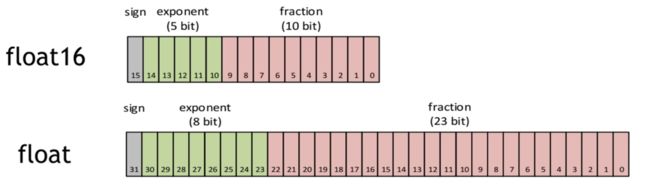
亦记作asimdhp(Advanced SIMD Half Precision),是 ARMv8.2 架构的可选扩展。asimdhp可用时,可以使用相关 SIMD 指令实现float16的读写计算。float16将float32所需的位数降低了一半,因此在 SIMD 下,可以实现两倍的并发吞吐,从而优化性能。为此,我们在卷积中,采用[N,C/8,H,W,8]的数据布局,新增了部分卷积实现,效果如下:
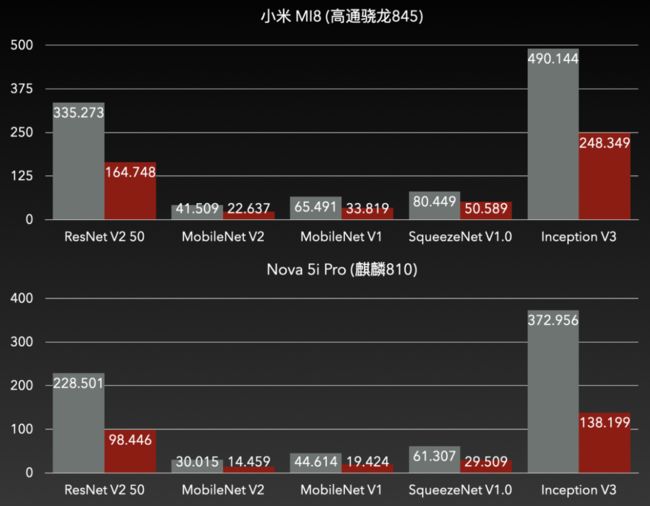
精度上几乎没有下降,但是性能足足提升了一倍。搭配上 MNN 转换工具的--fp16输出选项,模型大小还能减小一半。一箭双雕。
Dot Product

亦记作 asimddp(Advanced SIMD Dot Product),是 ARMv8.2 架构的可选扩展。asimddp 可用时,可以使用 SDOT/UDOT 指令实现 int8/uint8 的点积计算。SDOT/UDOT 指令如上图所示,一次可以处理两个 4x4 int8/uint8 数据乘,并累加到 4x1 的 int32/uint32 的寄存器上。这样强大的硬件加速指令,还是双发射的。
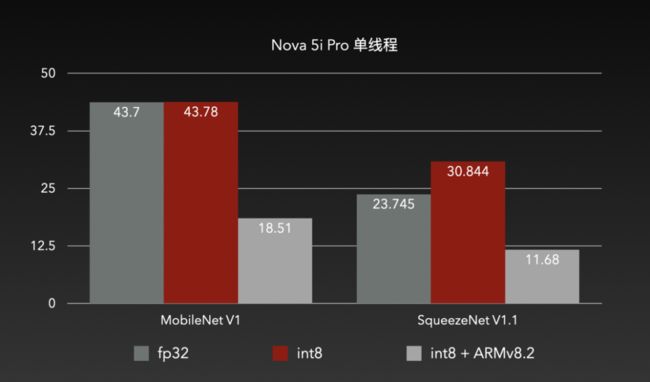
实战表现效果也非常明显,在原先 int8 无法发挥效用的设备上,ARMv8.2 也成功实现了耗时减半。
Python 工具链
2019年的绿盟开发者大会上,我们发布了 MNN 的 Python 前端和 Python 版的转换、量化、可视化工具。而今,Python 又增加了对 MNN Express (表达式)、模型训练的封装,累计新增超过 150 个接口。具体可以参考说明文档【11】。
依然是前文的 Express 构图,使用 Python 改写的版本如下:
class Net(nn.Module):
"""construct a lenet 5 model"""
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.conv(1, 20, [5, 5])
self.conv2 = nn.conv(20, 50, [5, 5])
self.fc1 = nn.linear(800, 500)
self.fc2 = nn.linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool(x, [2, 2], [2, 2])
x = F.relu(self.conv2(x))
x = F.max_pool(x, [2, 2], [2, 2])
x = F.convert(x, F.NCHW)
x = F.reshape(x, [0, -1])
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = F.softmax(x, 1)
return x
对熟悉 Python 的开发者来说,是不是要亲切上许多呢?
注:目前 Python Express API 处于 BETA 阶段。我们会根据社区和内部的反馈持续改进 Python API ,包含进行 backward incompatible 的改动。
后续计划
2020年,我们计划每个季度发布一个稳定版本。
未来的计划,主要集中在性能、训练、NPU 支持和模型压缩。
性能
性能是 MNN 的立身之本,相信很多朋友选择 MNN,也主要出于它飙车般的性能。有兴趣的朋友,可以去看看 MNN 发表在今年 MLSys 的论文解读【12】。
CPU 上,移动设备方面,ARMv8.2 将是新手机的主流,上文所展示 2 倍加速比非常诱人,我们会进一步挖掘 ARMv8.2 的优化空间;其他平台方面, x86 的性能在单机训练、服务端推理的场景中举足轻重,会是性能优化的另一个目标。
GPU 上,我们会聚焦 Vulkan—— Android 下一代 GPGPU API 的事实标准。
训练
MNN 最新拥有的训练能力已经通过 Express (表达式)接口支持常用模型的训练、量化、蒸馏,我们会进一步完善训练能力,添加更多算子和求导的支持,以支持更多的模型。
NPU 支持
NPU 具有超高的性能、超低的能耗,将是未来手机的标配。NPU 的支持,也是许多 MNN 用户经常在钉钉群里提出的需求。MNN 在未来的1年,会逐步支持更多的 NPU,请大家拭目以待!
模型压缩
MNN 目前已经拥有 Post-training quantization 和 Quantization-aware training 的能力。我们会持续投入模型压缩(如蒸馏,稀疏,剪枝,低比特等),给业界提供更多优秀的、即插即用模型压缩算法。
链接:
1、https://github.com/alibaba/MNN
2、https://proceedings.mlsys.org/static/paper_files/mlsys/2020/7-Paper.pdf
3、https://github.com/alibaba/MNNKit
4、http://mudu.tv/watch/4308076
5、http://mudu.tv/watch/4397479
6、http://mudu.tv/watch/4844443
7、https://www.yuque.com/mnn/cn/kgd9hd
8、https://www.yuque.com/mnn/cn/bhz5eu
9、https://www.yuque.com/mnn/cn/vniw5p
10、https://community.arm.com/developer/tools-software/oss-platforms/b/android-blog/posts/bringing-armv8-2-instructions-to-android-runtime
11、https://www.yuque.com/mnn/cn/usage_in_python
12、https://mp.weixin.qq.com/s/ZmKC4fHTNPUj5iGqag19HA