TensorFlow2.0 学习笔记(七):变量的保存与恢复
欢迎关注WX公众号:【程序员管小亮】
专栏——TensorFlow学习笔记
文章目录
- 欢迎关注WX公众号:【程序员管小亮】
- 专栏——TensorFlow学习笔记
- 一、TensorFlow2.0 的变量保存与恢复
- 1_典型代码框架
- 2_多层感知机(MLP)实例
- 3_删除旧的 Checkpoint 以及自定义文件编号
- 二、TensorFlow1.x 的模型保存与恢复
- 推荐阅读
- 参考文章
一、TensorFlow2.0 的变量保存与恢复
很多时候,我们需要在模型训练完成后,将训练好的参数(变量)保存起来。在需要使用模型的其他地方,就可以载入模型和参数,直接得到训练好的模型,而不用重新训练,继而节省了很多时间。
可能第一个想到的是用 Python 的序列化模块 pickle 存储 model.variables。但不幸的是,TensorFlow 的变量类型 ResourceVariable 并不能被序列化。好在 TensorFlow 提供了 tf.train.Checkpoint 这一强大的变量保存与恢复类,可以使用其 save() 和 restore() 方法将 TensorFlow 中所有包含 Checkpointable State 的对象进行保存和恢复。
Checkpoint只保存模型的参数,不保存模型的计算过程,因此一般用于在具有模型源代码的时候,恢复之前训练好的模型参数。
具体而言,tf.keras.optimizer 、 tf.Variable 、 tf.keras.Layer 或者 tf.keras.Model 实例都可以被保存,使用方法非常简单,首先声明一个 Checkpoint:
checkpoint = tf.train.Checkpoint(model=model)
这里 tf.train.Checkpoint() 接受的初始化参数比较特殊,是一个 **kwargs 。具体而言,是一系列的键值对,键名可以随意取,值为需要保存的对象。例如,如果想保存一个继承 tf.keras.Model 的模型实例 model 和一个继承 tf.train.Optimizer 的优化器 optimizer ,可以这样写:
checkpoint = tf.train.Checkpoint(GoodModel=model, GoodOptimizer=optimizer)
这里 GoodModel 是为待保存的模型 model 所取的任意键名。
注意,在恢复变量的时候,还将使用这一键名。
接下来,当模型训练完成需要保存的时候,使用:
checkpoint.save(save_path_with_prefix)
其中,save_path_with_prefix 是保存文件的 目录 + 前缀。
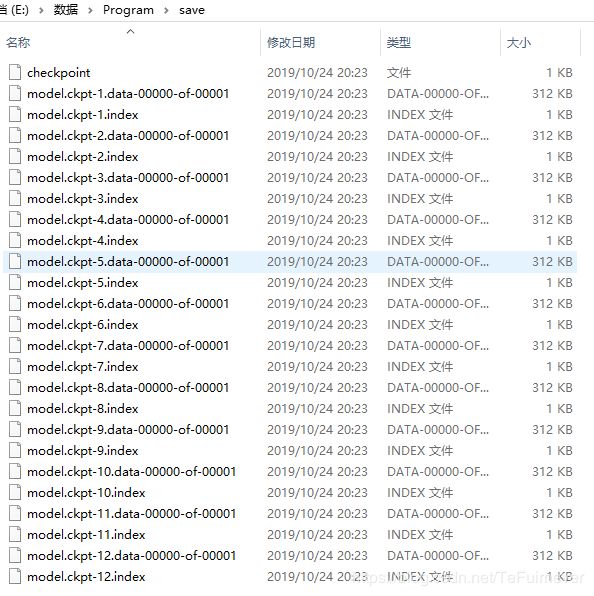
举个例子,假设在源代码目录下,建立了一个名为 save 的文件夹并调用一次 checkpoint.save('./save/model.ckpt') ,就可以在可以在 save 目录下发现名为 checkpoint 、 model.ckpt-1.index 、 model.ckpt-1.data-00000-of-00001 的三个文件,这些文件就记录了变量信息。
在
TensorFlow1.x中是使用tf.train.Saver函数进行模型的保存的。

checkpoint.save() 方法可以运行多次,每运行一次都会得到一个 .index 文件和 .data 文件,序号依次累加。
当在其他地方需要为模型重新载入之前保存的参数时,需要再次实例化一个 checkpoint,同时保持键名的一致,再调用 checkpoint 的 restore 方法,就像下面这样:
model_to_be_restored = MyModel() # 待恢复参数的同一模型
checkpoint = tf.train.Checkpoint(GoodModel=model_to_be_restored) # 键名保持为“GoodModel”
checkpoint.restore(save_path_with_prefix_and_index)
即可恢复模型变量。 其中 save_path_with_prefix_and_index 是之前保存的文件的 目录 + 前缀 + 编号。例如,调用 checkpoint.restore('./save/model.ckpt-1') 就可以载入前缀为 model.ckpt ,序号为 1 的文件来恢复模型。
当保存了多个文件时,我们往往想载入最近的一个。可以使用 tf.train.latest_checkpoint(save_path) 这个辅助函数返回目录下最近一次 checkpoint 的文件名。例如如果 save 目录下有 model.ckpt-1.index 到 model.ckpt-10.index 的 10 个保存文件, tf.train.latest_checkpoint('./save') 即返回 ./save/model.ckpt-10 。
1_典型代码框架
恢复与保存变量的典型代码框架如下:
# train.py 模型训练阶段
model = MyModel()
# 实例化Checkpoint,指定保存对象为model(如果需要保存Optimizer的参数也可加入)
checkpoint = tf.train.Checkpoint(myModel=model)
# ...(模型训练代码)
# 模型训练完毕后将参数保存到文件(也可以在模型训练过程中每隔一段时间就保存一次)
checkpoint.save('./save/model.ckpt')
# test.py 模型使用阶段
model = MyModel()
checkpoint = tf.train.Checkpoint(myModel=model) # 实例化Checkpoint,指定恢复对象为model
checkpoint.restore(tf.train.latest_checkpoint('./save')) # 从文件恢复模型参数
# 模型使用代码
2_多层感知机(MLP)实例
TensorFlow2.0 学习笔记(二):多层感知机(MLP) 中的训练代码
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data,
self.test_label) = mnist.load_data()
# MNIST中的图像默认为uint8(0-255的数字)
# 以下代码将其归一化到0-1之间的浮点数,并在最后增加一维作为颜色通道
self.train_data = np.expand_dims(
self.train_data.astype(
np.float32) / 255.0,
axis=-1) # [60000, 28, 28, 1]
self.test_data = np.expand_dims(
self.test_data.astype(
np.float32) / 255.0,
axis=-1) # [10000, 28, 28, 1]
self.train_label = self.train_label.astype(np.int32) # [60000]
self.test_label = self.test_label.astype(np.int32) # [10000]
self.num_train_data, self.num_test_data = self.train_data.shape[
0], self.test_data.shape[0]
def get_batch(self, batch_size):
# 从数据集中随机取出batch_size个元素并返回
index = np.random.randint(0, np.shape(self.train_data)[0], batch_size)
return self.train_data[index, :], self.train_label[index]
class MLP(tf.keras.Model):
def __init__(self):
super().__init__()
# Flatten层将除第一维(batch_size)以外的维度展平
self.flatten = tf.keras.layers.Flatten()
# 全连接层
self.dense1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs): # [batch_size, 28, 28, 1]
x = self.flatten(inputs) # [batch_size, 784]
x = self.dense1(x) # [batch_size, 100]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
import tensorflow as tf
import numpy as np
import argparse
from test2 import MLP
from test2 import MNISTLoader
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('--mode', default='train', help='train or test')
parser.add_argument('--num_epochs', default=1)
parser.add_argument('--batch_size', default=50)
parser.add_argument('--learning_rate', default=0.001)
args = parser.parse_args()
data_loader = MNISTLoader()
def train():
model = MLP()
optimizer = tf.keras.optimizers.Adam(learning_rate=args.learning_rate)
num_batches = int(
data_loader.num_train_data //
args.batch_size *
args.num_epochs)
checkpoint = tf.train.Checkpoint(
GoodModel=model) # 实例化Checkpoint,设置保存对象为model
for batch_index in range(1, num_batches + 1):
X, y = data_loader.get_batch(args.batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(
y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
if batch_index % 100 == 0: # 每隔100个Batch保存一次
path = checkpoint.save('./save/model.ckpt') # 保存模型参数到文件
print("model saved to %s" % path)
def test():
model_to_be_restored = MLP()
# 实例化Checkpoint,设置恢复对象为新建立的模型model_to_be_restored
checkpoint = tf.train.Checkpoint(GoodModel=model_to_be_restored)
checkpoint.restore(tf.train.latest_checkpoint('./save')) # 从文件恢复模型参数
y_pred = np.argmax(
model_to_be_restored.predict(
data_loader.test_data),
axis=-1)
print(
"test accuracy: %f" %
(sum(
y_pred == data_loader.test_label) /
data_loader.num_test_data))
# train.py 模型训练阶段
if __name__ == '__main__':
if args.mode == 'train':
train()
在运行上面的 train 代码之后,会在同目录下建立 save 文件夹,并且在训练之后,save 文件夹内将会存放每隔 100 个 batch 保存一次的模型变量数据。

再次运行 test 代码之后,将直接使用最后一次保存的变量值恢复模型并在测试集上测试模型性能,可以直接获得 95% 左右的准确率。
# test.py 模型使用阶段
if __name__ == '__main__':
if args.mode == 'test':
test()

3_删除旧的 Checkpoint 以及自定义文件编号
在模型的训练过程中,往往每隔一定步数保存一个 Checkpoint 并进行编号。不过很多时候会有这样的需求:
- 在长时间的训练后,程序会保存大量的
Checkpoint,但我们只想保留最后的几个Checkpoint; Checkpoint默认从 1 开始编号,每次累加 1,但我们可能希望使用别的编号方式。
这时,可以使用 TensorFlow 的 tf.train.CheckpointManager 来实现以上需求。具体而言,在定义 Checkpoint 后接着定义一个 CheckpointManager:
checkpoint = tf.train.Checkpoint(model=model)
manager = tf.train.CheckpointManager(checkpoint, directory='./save',
checkpoint_name='model.ckpt', max_to_keep=k)
其中 directory 参数为文件保存的路径, checkpoint_name 为文件名前缀(不提供则默认为 ckpt ), max_to_keep 为保留的 Checkpoint 数目。
在需要保存模型的时候,直接使用 manager.save() 即可。如果希望自行指定保存的 Checkpoint 的编号,则可以在保存时加入 checkpoint_number 参数。例如 manager.save(checkpoint_number=100) 。?
看一个例子,展示使用 CheckpointManager 限制仅保留最后三个 Checkpoint 文件,并使用 batch 的编号作为 Checkpoint 的文件编号。
import tensorflow as tf
import numpy as np
import argparse
from test2 import MLP
from test2 import MNISTLoader
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('--mode', default='train', help='train or test')
parser.add_argument('--num_epochs', default=1)
parser.add_argument('--batch_size', default=50)
parser.add_argument('--learning_rate', default=0.001)
args = parser.parse_args()
data_loader = MNISTLoader()
def train():
model = MLP()
optimizer = tf.keras.optimizers.Adam(learning_rate=args.learning_rate)
num_batches = int(data_loader.num_train_data // args.batch_size * args.num_epochs)
checkpoint = tf.train.Checkpoint(GoodModel=model)
# 使用tf.train.CheckpointManager管理Checkpoint
manager = tf.train.CheckpointManager(checkpoint, directory='./save', max_to_keep=3)
for batch_index in range(1, num_batches):
X, y = data_loader.get_batch(args.batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
if batch_index % 100 == 0:
# 使用CheckpointManager保存模型参数到文件并自定义编号
path = manager.save(checkpoint_number=batch_index)
print("model saved to %s" % path)
def test():
model_to_be_restored = MLP()
checkpoint = tf.train.Checkpoint(GoodModel=model_to_be_restored)
checkpoint.restore(tf.train.latest_checkpoint('./save'))
y_pred = np.argmax(model_to_be_restored.predict(data_loader.test_data), axis=-1)
print("test accuracy: %f" % (sum(y_pred == data_loader.test_label) / data_loader.num_test_data))
if __name__ == '__main__':
if args.mode == 'train':
train()
if args.mode == 'test':
test()

二、TensorFlow1.x 的模型保存与恢复
推荐一下自己的博客,基于 TensorFlow1.x 的模型保存与恢复,详细的看这个博客——TensorFlow学习笔记之快速求解四元一次方程的完整代码以及保存模型和读取模型的讲解
推荐阅读
- TensorFlow2.0 学习笔记(五):循环神经网络(RNN)
- TensorFlow2.0 学习笔记(六):TensorFlow2.0 和 Keras 的纠葛
参考文章
- TensorFlow 官方文档
- 简单粗暴 TensorFlow 2.0