Flink on Yarn HA模式部署
1. 配置yarn最大重试次数yarn-site.xml:
yarn.resourcemanager.am.max-attempts
4
2. 配置Yarn重试次数
[root@hadoop2 flink-1.5.0]# vi conf/flink-conf.yaml
yarn.application-attempts: 10
此参数代表Flink Job(yarn中称为application)在Jobmanager(或者叫Application Master)恢复时,允许重启的最大次数。
注意,Flink On Yarn环境中,当Jobmanager(Application Master)失败时,yarn会尝试重启JobManager(AM),重启后,会重新启动Flink的Job(application)。因此,yarn.application-attempts的设置不应该超过yarn.resourcemanager.am.max-attemps.
3. 配置ZooKeeper:
[root@hadoop2 flink-1.5.0]# vi conf/flink-conf.yaml
high-availability: zookeeper
high-availability.storageDir: hdfs:///flink/ha/
high-availability.zookeeper.quorum: 10.108.4.203:2181,10.108.4.204:2181,10.108.4.205:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /cluster_yarn
4. conf/masters修改
设置要启用JobManager的节点及端口:
10.108.4.202:8081
10.108.4.203:8081
5. conf/zoo.cfg修改
server.1=10.108.4.203:2888:3888
server.2=10.108.4.204:2888:3888
server.3=10.108.4.205:2888:3888
PS: 修改完后,使用scp命令将flink-conf.yaml、masters、 zoo.cfg文件同步到其他节点:
[root@hadoop2 conf]# scp flink-conf.yaml masters zoo.cfg root@hadoop3:/opt/flink-1.5.0/conf
6. 启动Flink Yarn Session
启动Flink Yarn Session有2种模式:分离模式、客户端模式
通过-d指定分离模式,即客户端在启动Flink Yarn Session后,就不再属于Yarn Cluster的一部分。如果想要停止Flink Yarn Application,需要通过yarn application -kill 命令来停止。
我们这里采用分离模式来启动Flink Yarn Session:
[root@hadoop2 bin]# ./yarn-session.sh -n 3 -jm 1024 -tm 1024 -s 3 -nm FlinkOnYarnSession -d -st
我们可以通过yarn的webUI查看一下当前启动的Application:
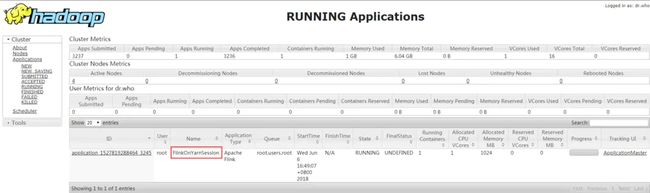
可以看到名字是FlinkOnYarnSession,总内存6GB,运行使用的内存1GB(-jm指定了1GB),当前容器数量为3.
我们通过点击ApplicationMaster选项 查看Flink的WebUI:
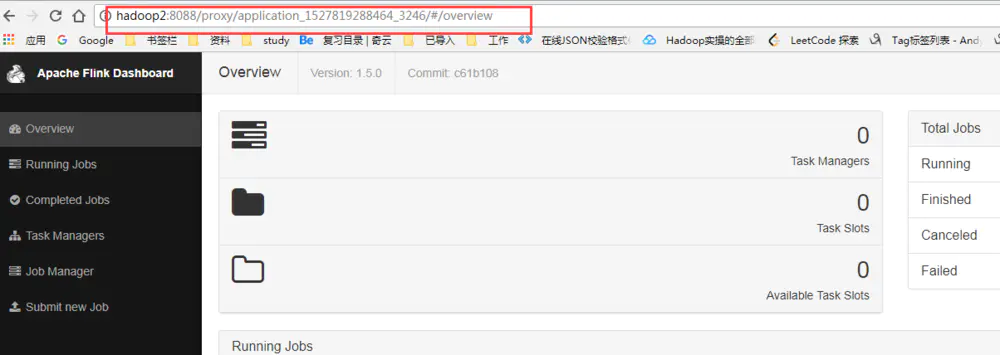
7. 提交Job
通过CLI方式提交:
flink run -c wikiedits.Test1 toptrade-flink-1.0.jar
我们看下目前Job的JobGraph:
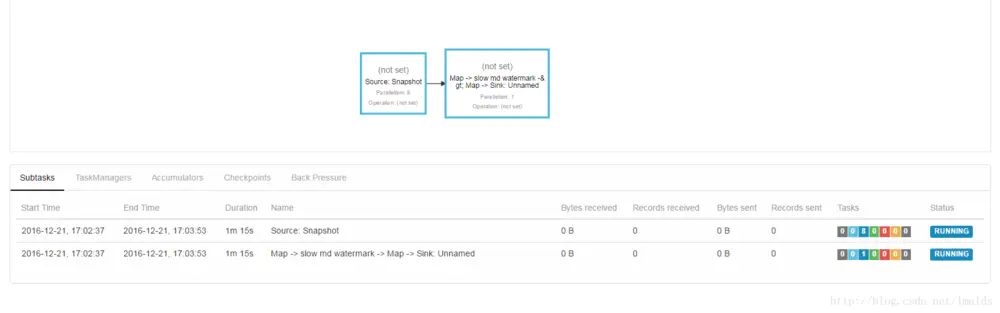
8. HA测试
现在,我们kill掉Jobmanager(AM)进程YarnApplicationMasterRunner,看看Yarn Cluster的HA情况。
[root@hadoop2 flink-1.5.0]# jps
32751 NodeManager
8911 YarnSessionClusterEntrypoint
[root@hadoop2 flink-1.5.0]# kill -9 8911
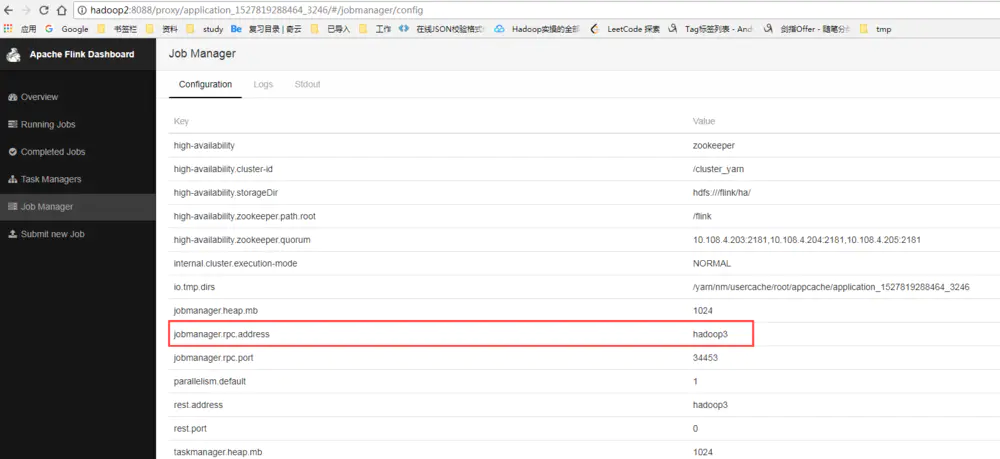
可以看到Application Attemp的ID增加了1:

我们再到mf42的$YARN_CONF_DIR(如果没设置则在$HADOOP_CONF_DIR)下看看日志情况,当前AM的日志路径在$HADOOP_CONF_DIR/userlogs//下,可以看出Yarn在重启YarnApplicationMasterRunner进程,并在重启期后重新提交Flink的Job。
再次查看进程号:
[root@hadoop3 flink-1.5.0]# jps
22519 YarnSessionClusterEntrypoint
YarnApplicationMasterRunner进程号变了。
此时,Flink的WebUI又可以访问了,而且Job被cancel掉后重新启动了。
转载地址:https://www.jianshu.com/p/8f1e650ebcad