NLP入门(1)-词典分词方法及实战
分词是自然语言处理中最基本的任务之一,而词典分词是最简单、最常见的分词算法,仅需一部词典和一套查词典的规则即可。
利用词典分词,最主要的是定制合适的切分规则。规则主要有正向最长匹配、逆向最长匹配和双向最长匹配三种。本文主要介绍上述三种规则。
1、词典准备
既然是词典分词,那么我们首先需要找到一部字典,这里使用Hanlp提供的mini版本的中文词典:https://github.com/hankcs/HanLP/blob/master/data/dictionary/CoreNatureDictionary.mini.txt
下载下来之后保存在本地项目路径下,词典的内容如下:
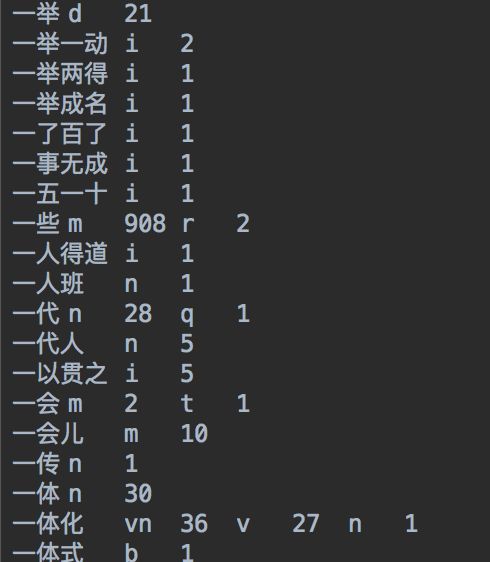
可以看到第一列是我们需要的词,后面每两列代表一种词性以及词频。我们只需要得到所有的词即可:
with open('data/CoreNatureDictionary.mini.txt') as f:
dict_set = set([s.split('\t')[0] for s in f.readlines()])
dict_set
得到输出如下:

好了,词典准备完毕,接下来介绍几种词典分词方法。
2、切分规则
常用的切分规则有正向最长匹配、逆向最长匹配和双向最长匹配,它们都基于完全切分过程,因此本节先介绍完全切分过程,再介绍三种匹配规则。
2.1 完全切分
完全切分顾名思义,就是找出一段文本中所有在字典中的单词。假设我们要分词的句子是“自然语言处理入门实战”,完全切分的代码如下:
#完全切分
def fully_segment(text,dic):
seg_list = []
for i in range(0,len(text)-1):
for j in range(i+1,len(text)):
word = text[i:j+1] # 注意这里是j+1
if word in dic:
seg_list.append(word)
return seg_list
print(','.join(fully_segment('自然语言处理入门实战',dict_set)))
输出为:
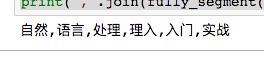
但完全切分不是真正意义上的分词,我们需要完善一下规则,考虑到越长的单词表达的意义越丰富,于是定义单词越长优先级越高。具体来说,在以某个字符为起点逐次向前或向后查找的过程中,优先输出更长的单词。这种规则统称为最长匹配算法。包括正向最长匹配、逆向最长匹配和双向最长匹配。
接下来,我们就来介绍下面这几种匹配算法。
2.2 正向最长匹配
正向匹配的过程示意图如下所示:
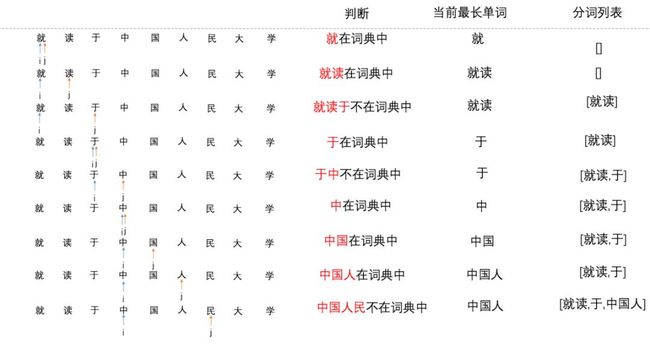
上图中,我们只给出了部分的分词过程,不过可以看到,它是一个从前向后匹配的过程,通过代码进一步理解下:
def forward_segment(text,dic):
seg_list = []
i = 0
while i < len(text):
longest_word = text[I]
for j in range(i+1,len(text)+1):
word = text[i:j]
if word in dic and len(word) > len(longest_word):
longest_word = word
seg_list.append(longest_word)
i += len(longest_word)
return seg_list
print(forward_segment("就读于中国人民大学",dict_set))
最终的分词结果如下:

可以看到,这样切分并不是我们想要的结果,因为中国人民大学切分为中国、人民和大学更加合理(或者当作一个专有名词,不进行切分),但在正向最长匹配中,因为中国人同样出现在了词典中,因此中国人便优先作为一个词输出了。
2.3 逆向最长匹配
接下来再看看逆向匹配的过程:

上图中,我们只给出了部分的分词过程,不过可以看到,它是一个从后向前匹配的过程,每次都认为从零位置到当前下标i位置的单词是最长的,然后基于词典不断往后移动j,直到切片对应的单词出现在词典中,通过代码进一步理解下:
def backward_segment(text,dic):
seg_list = []
i = len(text) - 1
while i >= 0:
longest_word = text[I]
for j in range(0,i):
word = text[j:i+1]
if word in dic and len(word) > len(longest_word):
longest_word = word
seg_list.append(longest_word)
i -= len(longest_word)
seg_list.reverse()
return seg_list
print(backward_segment("就读于中国人民大学",dict_set))
最终的切分结果如下:

可以看到切分结果符合我们的预期,但是从上面的流程图直观的就可以看到,逆向最长匹配的时间复杂度是明显高于正向匹配的,因为逆向匹配每次都需要从句子的最开始进行扫描。
2.4 双向最长匹配
对于同一个句子,正向最长匹配和逆向最长匹配带来的结果可能不同,那到底哪种更好呢?先看下面几个例子:
print(forward_segment("就读于中国人民大学",dict_set))
print(forward_segment("电视上的电影节目",dict_set))
print(forward_segment("项目的研究",dict_set))
print(forward_segment("角色本人将会参与配音",dict_set))
print(backward_segment("就读于中国人民大学",dict_set))
print(backward_segment("电视上的电影节目",dict_set))
print(backward_segment("项目的研究",dict_set))
print(backward_segment("角色本人将会参与配音",dict_set))
分词结果如下:
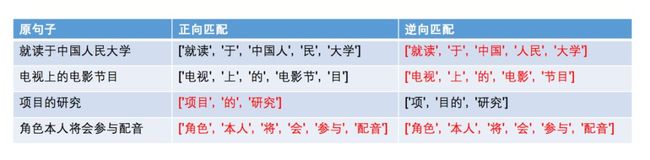
可以看到,有时候正向匹配的效果更好,有时候逆向匹配的效果更好,但似乎逆向匹配的匹配成功次数更多。那能不能从两种结果中挑选一种比较好的呢?于是我们又有了双向最长匹配。规则如下:
1)同时执行正向和逆向最长匹配,若两者的词数不同,则返回词数更少的那一个;
2)否则,返回两者中单字更少的那一种;
3)当单子数量也相同时,优先返回逆向最长匹配的结果。
双向匹配的代码如下:
def count_single_word(word_list):
return sum(1 for word in word_list if len(word) == 1)
def bidiectional_segment(text,dic):
f = forward_segment(text,dic)
b = backward_segment(text,dic)
if len(f) < len(b):
return f
elif len(f) > len(b):
return b
else:
if count_single_word(f) < count_single_word(b):
return f
else:
return b
print(bidiectional_segment("就读于中国人民大学",dict_set))
print(bidiectional_segment("电视上的电影节目",dict_set))
print(bidiectional_segment("项目的研究",dict_set))
print(bidiectional_segment("角色本人将会参与配音",dict_set))
最终的切分结果如下:
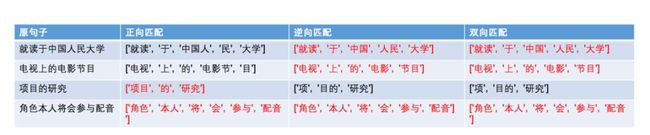
第三个句子还是没有获得正确的切分,因为在分词长度以及单字个数都一致的情况下,优先返回的是逆向匹配的结果。由此可见,基于词典匹配的规则分词方法,效果是比较差的。
好了,几种基于词典的规则分词方法就介绍道这里,下一篇我们将介绍如何对分词结果的精度进行评价,总不能一个个用肉眼去看吧,哈哈。
上述内容总结自《自然语言处理入门》: