25、路由算法二(网络层)
1、层次路由
- 随着网络规模的增长,路由器的路由表也成比例地增长。不断增长的路由表不仅消耗路由器内存,而且还需要更多的CPU时间来扫描路由器表以及更多的带宽来发送有关的状态报告。当网络增长到一定规模时,路由器不太可能再为其他每一个路由器维护一个表项。所以,路由不得不分层进行,就好像电话网络中的做法那样。
- 在采用了分层路由之后,路由器被划分成区域。每个路由器知道如何将数据包路由到自己所在区域内的目标地址,但是对于其他区域的内部结构毫不知情。当不同的网络被互联在一起,很自然会将每个网络当做一个独立的区域,一个网络中的路由器不必知道其他网络的拓扑结构。
- 对于大型网络,两级的层次结构可能还不够;可能有必要将区域组织成簇,将簇组织成区,将区组织成群,等等。举一个例子,请考虑如何将一个数据包从加利福利亚的伯克利路由到肯尼亚的马林迪。伯克利的路由器知道加利福利亚的详细拓扑结构,但是可能将其他所有州际的流量发送给洛杉矶的路由器;洛杉矶的路由器能够将流量直接路由器给美国其他国家的路由器,但是它会将国际流量发送到纽约;纽约的路由器直接将所有流量发送至目标国家中负责处理国际流量的路由器,比如肯尼亚的内罗毕。最后,该数据包将沿着肯尼亚国家中的路径树往下传送,一直到达马林迪。
- 图中给出了一个两级层次的定量分析例子,其中包含了5个区域。路由器1A的完整路由表有17个表项,如图b所示。如果采用分级路由,则路由表如图c所示,所有针对本区域内的路由表项都跟原先一样;但是,所有到其他区域的路由器都将被压缩到了单个路由器中。因此,所有到区域2的流量都要经过1B-2A线路,其余的远程流量都经过1C-3B线路。层次路由使得路由器1A的路由表从17项降低为7项。随着区域数与每个区域中路由器数量之比值的增加,节省下来的表空间也随之增加。
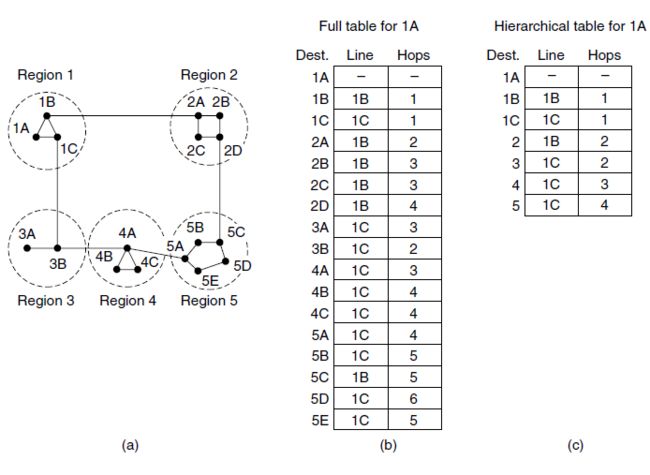
- 不幸的是,这种空间的节省不是免费得来的,它需要付出代价,其代价形式是增加了路径长度。例如,从1A到5C的最佳路径是经过区域2,但采用了层次路由之后,所有到区域5的流量都要经过区域3,因为对于区域5中的大多数目标来说,这是更好的选择。
- 当单个网络变得非常大时,应该分多少层?例如,一个具有720个路由器的子网。如果没有分层,每个路由器需要720个表项;如果子网被分成24个区域,每个区域30个路由器,那么,每个路由器只需要30个本地表项,加上23个远程表项,总共53个表项;如果采用三级层次结构,总共8个簇,每个簇包含9个区域,每个簇包含9个区域,每个区域10个路由器,那么每个路由器需要10个表项用于本地记录,8个表项用于到同一簇内其他区域的路由,7个表项用于远程的簇,总共25个表项。Kamoun和Kleinrock发现,对于一个包含N个路由器的网络,最优层数是ln N,每个路由器所需的路由器表项是elnN个,它们还证明了由于分层路由而导致的平均路径长度的实际增长非常小,通常是可以接收的。
2、广播路由
- 在有些应用中,主机需要给其他多个或者全部主机发送消息。例如,用于发布天气预报、股市行情最新报告或者现场直播节目等服务,它们最佳的工作方式是将消息广播给所有机器,然后让那些感兴趣的机器读取数据。同时给全部目标地址发送一个数据包称为广播。
- 一种不要求网络具有任何特殊性质的广播方法是让源机器简单地给每一个目标单独发送一个数据包。这种方法不仅浪费带宽,而且还要求源机器拥有所有目标机器的完整地址列表。实际上这种做法不够理想,即使它广泛适用。一种改进方法称为多目标路由,每个数据包包含一组目标地址,或者一个位图,由该位图指定所期望到达的目标。当一个数据包到达一个路由器时,路由器检查数据包携带的所有目标,确定哪些输出线路是必要的(只要一条输出线路是到达至少一个目标的最佳路径,那么就是必要的)。路由器为每一条需要用到的输出线路生成一份该数据包新的副本,在这份副本中只包含了那些使用这条线路的目标地址。实际上,原来的目标集合被分散到这些输出线路上。在经过了足够多的跳数之后,每个数据包将只包含一个目标地址,因此可被当做普通的数据包来对待。多目标路由方法就如单个地址的数据包一样,只不过当多个数据包必须遵循同样的路径时,其中一个数据包承担了全部的费用,而其他的舒筋梢则是免费搭载。因此,网络带宽的利用率更高。然而,这种模式依然要求源端知道全部的目标地址,对于路由器来说,要确定从哪些线路转发多目标数据包的工作量太大,尤其是处理多个不同的数据包时。
- 泛洪是更好的广播路由技术。当每个源实现了序号,泛洪能有效利用链路,而且路由器要做的决策也很简单。虽然泛洪方法不适合普通的点到点通信,但它被认为值得考虑做广播,而且,事实证明,一旦计算出普通数据包的最短路径,我们可以把广播做得更好。
- 逆向路径转发思想被认为是一种非常优秀的广播技术。当一个广播数据包到达一个路由器时,路由器检查它到来的那条线路是否正是通常用来给广播源端发送数据包用的那条线路。如果是,说明这是一个极好的机会,该广播数据包是沿着最佳路径被转发过来的,因而是到达当前路由器的第一份副本。如果是这种情况,则路由器将该数据包转发到除了到来的那条线路之外的其他线路上。然而,如果广播数据包时从其他任何一条并非首选的到达广播源的线路入境的话,该数据包被当做一个可能的重复数据包而被丢弃。
- 例子如图。图a显示了一个网络,图b显示了该网络中路由器 I 的一棵汇集树,图c显示了逆向路径算法是如何工作的。在第一跳,I 发送数据包给F、H、J和N。这些数据包中的每一个都是在通向 I 的首选路径(假定首选路径都沿着汇集树)到来的,这点用字母外面加一个圆圈来表示。在第二跳,共产生了8个数据包,其中,在第一跳接收到数据包的路由器各产生2个数据包。结果,所有这8个数据包都到达了以前没有访问过的路由器,其中5个是沿着首选线路到来的。在第三跳所产生的6个数据包中,只有3个是沿着首选线路(在C、E和K)到来的,其他的都是重复数据包。在经过5跳和24个数据包以后,广播过程终止。相比之下,如果完全沿着汇集树的话,只需要4跳和14个数据包。

- 逆向路径转发的路径的主要优点是它有效而且易于实现。它只往每个方向上的链路发送一次广播数据包,就像泛洪一样简单,而仅仅要求路由器知道如何到达全部目标;路由器无须记住序号(或使用其他机制来防止泛洪)或者在数据包中列出全部的目标地址。
- 最后一种算法改进了逆向路径转发行为。它明确使用了以发起广播的路由器为根的汇集树,或者任何其他便利的生成树。生成树是网络的一个子集,它包含所有的路由器,但是没有任何环路。汇集树是生成树的一种。如果每个路由器都知道它的哪些线路属于生成树,那么,它就可以将一个入境广播数据包复制到除了该数据包到来的那条线路之外的所有生成树线路上。这种方法可最佳使用带宽,并且所生成的数据包也绝对是完成这项任务所需要的最少数量。例如,图b的汇集树就被用作生成树,广播数据包的副本最少,只有14个。唯一的问题是每个路由器都必须知道这棵生成树才可以正常工作。有时候这样的信息是可以得到的(比如采用了链路状态路由算法,所有路由器都知道完整的网络拓扑,因而它们计算出一条生成树),但是有时候无法获得这样的信息(比如采用了距离矢量路由算法)。
3、组播路由
- 有些应用,比如多人游戏或者体育赛事视频直播到几个观看点,这样的应用将数据包发送给多个接收者。除非组的规模很小,否则给每个接收者单独发不同的数据包的代价很昂贵。另一方面,如果在一个由百万节点组成的网络中有一个由1000个机器组成的组,采用广播技术发送数据包显然是一种浪费,因为大多数接收者对广播的消息并不感兴趣。因此需要一种办法能够给明确定义的组发送消息,这些组的成员数量虽然很多,但相比整个网络规模却很小。
- 给一个组发送消息称为组播,使用的路由算法称为组播路由。所有的组播方案都需要一些方法来创建和撤销特定的组,并确定哪些路由器是组的成员。如何完成这些任务不是路由算法要关注的。现在,假定每个组由一个组播地址标识,并且路由器知道自己属于哪些组。组播方案建立在广播路由方案的基础上,为了将数据包传递给组的成员同时有有效利用带宽,数据包可沿着生成树发送。然而,最佳生成树的使用取决于组的密度分布。密集分布指接收者遍布在网络的大部分区域;洗漱分布指大部分网络都不属于组。
- 如果组是密集分布的,那么广播是一个良好的开端,因为它能有效地把数据包发送到网络的每个角落。但广播可能将一些不属于该组成员的路由器,因而也是一种浪费。Deering和Cheriton探索出一个方案,就是通过修建广播生成树把不通往组成员的链路从树中删掉。修剪结果得到的是一棵有效的组播生成树。
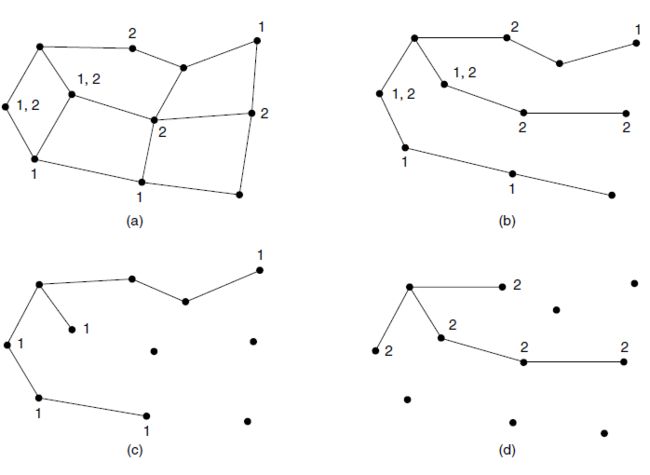
- 例子如图,图a其中有两个组:组1和组2。有些路由器连接的主机属于其中的一个组或同时属于两个组。最左边的路由器的一棵生成树如图b。此树可用于广播,对于组播来说则过度了,这从下面显示的两个修剪版本可见一斑。在图c中,所有不通向组1成员的主机链路已被删除,结果是一棵针对最左边路由器发送到组1的生成树。数据包的转发就只能沿着这棵树进行,可见这比广播树有效,因为这里只有7条链路而不是10条链路。如d显示了一棵针对组2修剪后的组播生成树。相比广播树它也更加有效,此时只有5条链路。这个例子表明,不同的组播组有不同的生成树。
- 生成树的修剪方式有许多种。如果路由器使用了链路状态路由算法,并且每个路由器知道完整的网络拓扑结构,包括了解哪些主机属于哪个组,那么就可以使用一种最简单组播算法。每个路由器针对组内每个发送者构造一棵它自己修剪后生成树,具体做法是先按常规方法构造一棵以发送者为根的汇集树,然后从汇集树节点上删除所有不连接到组成员的链路。MOSPF就是一个以这种方式工作的链路状态协议例子。
- 如果采用距离矢量路由算法,则要遵循不同的修剪策略。基本算法是逆向路径转发。然而,一旦一个路由器不属于任何一个组,并且没有连接到需要连接该组播消息的其他路由器,那么它要用PRUNE(减少、删除)消息作为接收该组播消息的响应,告诉发送方该消息的邻居不要再给自己发送任何来自该组发送者的消息。如果一个路由器连接的主机没有一个属于该组成员,并且从它以前转发组播消息的所有线路都接收了这样的修剪消息(意味着除源端以为的其他连接处都没有属于该组的成员,寒注),那么它也同样以PURNE消息来响应(它自然也不需要连接源端了,寒注),通过这种递归方式,最终修剪出一棵生成树。距离矢量组播路由协议(DVMRP)就是以一个这样方式工作的组播路由协议的例子。
- 修剪过程的最后结果得到的是一棵有效的生成树,该树只用到了那些抵达组成员真正需要的链路。这种方法的一个潜在缺点是路由器需要做大量的工作,特别是大型网络。假设一个网络有n组,平均每个组有m个节点。在每个路由器上针对n组,每个组有m棵修剪生成树(因为每个路由器给组中成员发送消息的生成树是不同的),因此总共有mn棵生成树。路由器转发数据包将沿着不同的方向进行,具体方向取决于组内哪个节点是发送者的位置。当存在大量的组,并且组内发送者很多时,需要大量空间来储存所有的树。
- 另一种设计是采用基于核心树的技术,计算某个组的单棵生成树。采用这种方法时所有路由器都同意某个路由器作为根,这个根称为核心或汇聚点,然后每个成员通过给根发送一个数据包来建立这棵树。树是组播数据包遵循的路径集合。图a显示了一棵组1的核心树。为了把数据包发送到这个组,发送者把数据包发送给核心;当数据包到达核心后,它再被沿着树往下转发。图b显示了网络右侧一个发送者的组播过程。作为性能优化的一种措施,发送该组的数据包并不需要先发送到核心然后再开始组播。一旦数据包到达树,它便沿着树向上转发给根,但同时沿着树转发到其他分支。
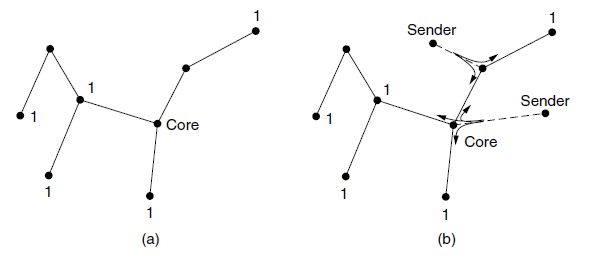
- 对于所有的组播源使用同一棵共享树是无法达到最优的。例如,在图b中,从网络右侧的发送者到达右上角的组成员通过核心要三跳,如果直接发送或许不需要三跳。共享树的低效率取决于核心和发送者的位置,把核心设置在所有发送者的中间往往是一种合理的做法。如果只有一个发送者,比如视频流传输到一个组,那么将发送者作为核心是最优的。另外值得注意的是共享树可以大大节省储存开销、消息发送和计算。每个路由器只要为每个组保存一棵树,而不是m棵树。此外,不属于这棵共享树一部分的路由器根本不需要为组做任何工作。正是出于这个原因,像基于核心树的共享树方法被用于Internet的稀疏组播,成为协议流的一部分,例如协议独立组播。
4、选播路由
- 在选播方式下,数据包被传递给最近的一个组成员。发现这些路径的方案就是所谓的选播路由。为什么需要选播?有时候,节点提供了诸如报时或者内容分发等服务,这类服务对客户而言最重要的是获取正确的信息而不是与哪个节点取得联系,任何节点都可以,只有它能提供所需的服务。例如,选播就作为域名系统的一部分广泛应用于Internet。
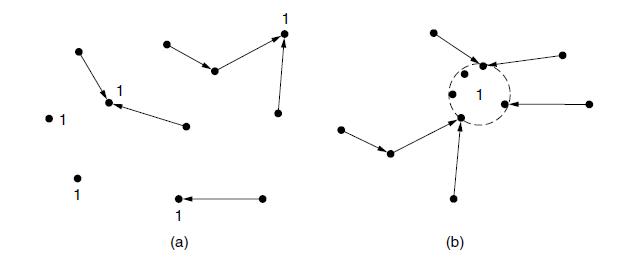
- 我们不需要为选播指定新的路由方案,因为普通的距离矢量和链路状态路由算法可用来生成选播路由。假设我们要选播数据包到组1的成员,该组成员都将被赋予一个组地址“1”而不是一个个独立的地址。距离矢量路由就像往常一样分发向量,并且节点将只选择到目的地1的最短路径。这将导致数据包被发送到目的地1的最近实例。图a显示了选播路由,此过程之所以能正常工作是因为路由协议并没有意识到目的地多个实例。也就是说,它认为节点1的实例都是同一个节点,如图b所示的拓扑结构。
- 这个过程也同样适用于链路状态路由协议,虽然要额外考虑这样的情况,路由协议似乎找不到通过节点1的最短路径,这将导致跨越网络空间的跳跃,因为节点1的实例是那些真正位于网络不同部分的节点。然而,链路状态协议已经能够区分路由器和主机。
5、移动主机路由
- 将使用术语移动主机示意诸如移动过程中使用计算机的这些设备,以便与从不移动的固定主机截然区分。移动主机引入了新的复杂性:路由一个数据包到移动主机,网络首先要找到该主机。我们将考虑的模型世界中,假设所有主机都有一个永久的家乡位置,该位置用于不会改变。每个主机也有一个永久的家乡地址,用来确定其家乡位置。移动主机所在系统的路由目标是使人们有可能利用固定的家乡地址来发送数据包,无论它们在哪里都能有效地把数据包送到。当然,这里的关键是要找到它们。
- 一种不同的模型是每当移动主机移动,以及拓扑结构发生变化后就重新就算路由。然后我们可以采用前述的路由方案。然而,随着移动主机的数目越来越多,这种模式将很快导致整个网络陷入不断计算新路由的过程。使用家乡地址能大大降低这种负荷。
- 另一种方法是在网络层之上提供移动,这就是今天笔记本电脑典型的用法。当它们被转移动新的Internet位置,笔记本电脑就获得一个新的网络地址。这里新老地址之间不存在任何关联;网络也不知道他们属于同一台笔记本电脑。在此模型中,一台笔记本电脑可用于浏览网页,但其他主机无法给它发送数据包(例如一个入境呼叫),除非有更高层的位置服务,例如移动之后再登录Skype。此外,主机在移动期间无法保持与网络的连接,而是必须重新启动建立新的连接。网络层的移动性对解决这些问题非常有用。
- Internet和蜂窝网络的移动路由采用的基本思想是移动主机把自己在哪里告诉给家乡位置的一台主机。这台主机称为家乡代理,它将以移动主机的名义采取行动,一旦它知道移动主机的当前位置,它就可以将数据包转发给移动主机。
- 如图。一个在西北部的西雅图的发送者想发送一个数据包给通常设在美国纽约的主机,但是移动主机到来圣地亚哥。在圣地亚哥的移动主机必须获得一个本地网络地址,然后才能使用网络。这是主机获得网络地址通常会发生的情况。本地地址称为转交地址。一旦移动主机有了这个地址,它可以告诉家乡代理它在哪儿。他给家乡代理发送一个带有转交地址的注册消息(第一步),图中用虚线表示,以表明它是一个控制信息而不是一个数据报文。
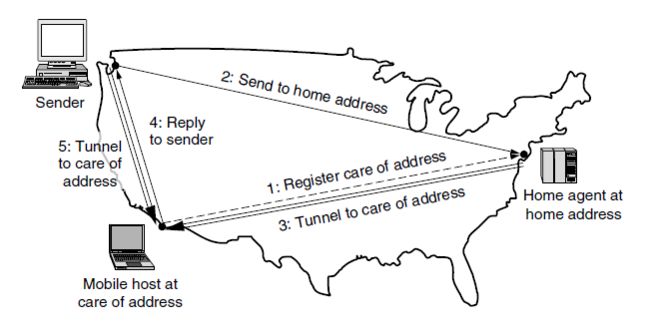
- 接下来,发送者使用其永久地址发送一个数据包给移动主机(第二步)。这个数据包被网络路由到主机的家乡位置,因为这是主机家乡地址的所属地。在纽约,家乡代理截获该数据包,然后用一个新的头包裹或者封装该数据包,并在捆绑后的结果发送给转交地址(第三步)。这种机制称为隧道,该机制在Internet上非常重要。当封装后的数据包到达转交地址,移动主机解开它并提取出来自发送者的数据包,然后移动主机直接给发送者发应答数据包(第四步)。这个路由过程称为三角路由,因为如果远程位置离家乡位置很远时,这条路由可能是迂回的。作为第四步的一部分,发送者可借鉴当前的转交地址,把随后的数据包直接发送给移动主机。具体做法是通过隧道发送到转发地址(第5步),完全绕过家乡位置。无论什么原因,在移动主机移动时如果失去了连接,则家乡地址可随时用来寻址到移动主机。
- 一般来说,当一个主机或路由器得到这种形式的信息“现在开始,请把Z的所有邮件发送给我”时,可能会产生两个问题,我在跟谁谈话,以及这是否是个好主意。安全信息被包含在消息中,因此可以用加密协议检查消息的合法性。
- 移动路由算法有许多变种。上面描述的方案是IPv6流动模型,这种移动主要形式用在Internet,以及诸如UMTS蜂窝网络中基于IP的那部分。我们发现如果发送方是个固定节点,则情况简单些;但设计方案时必须考虑这两个节点都是移动的情形。另外主机可能是移动网络的一部分,例如在一个平面上的计算机。对基本方案进行扩展就可以支持移动网络,不涉及任何主机部分的工作。
- 有些方案利用外地(即远程)代理,类似家乡代理但放置在远程位置,或类似于蜂窝网络中的访问位置寄存器(VLR)。然而,最近的研究方案并不需要外地代理;移动主机自己承担外地代理的行为。在这两种情况下,移动主机的临时位置仅限于被少量的主机获得(例如移动主机、家乡代理和发送者),因此大型网络中的许多路由器不需要重新计算路由。
6、自组织网络路由
- 当主机移动时路由器的工作如前所述,另一种更极端的情形是路由器本身也是移动的。这种可能性主要发生在以下几种情况下:地震现场的紧急救援工作、战场上的军事车辆、海上航行的一队舰队或者一群配备了笔记本电脑的人们聚集在一个没有802.11网络的区域。
- 在所有这样或那样的情形中,每个节点用无线通信,并且同时承担路由器和主机的双重角色。如果网络中的节点彼此靠近,那么该网络称为自组织(Ad hoc)网络,或者移动自组织网络(MANET)。Ad hoc网络区别于有线网络的原因在于网络拓扑更加复杂。节点可以来来去去,消失一会儿突然又出现在一个新的地方。在有线网络中,如果一台路由器有一条通往某个目标的有效路径,那么该路径将会持续有效(除非故障)。而在Ad hoc网络中,拓扑结构可能每时每刻都在变化,所以路径的可能性和有效性自发地改变着,甚至没有任何警告。毋庸多说,这些情况使得Ad hoc网络的路由比固定网络更具挑战性。
- 针对Ad hoc目前已经提出了许多种路由算法。然而,由于Ad hoc网络相比移动网络实际很少使用,因此无法确定哪种协议更有效。作为一个学习案例,我们将考察其中一个最流行的路由算法,即Ad hoc按需距离矢量(AODV)路由算法。它是相对的距离矢量算法,适应在移动环境中工作,即节点的带宽有限和电源寿命相对较短。下面是此算法的陈述。
路由发现
- 在AODV中,到某个目的地的路由是按需发现的,即只有当某个节点要给目标节点发送数据时才去找路径。这种方式可以节省大量不必要的工作,比如在路由使用之前拓扑就发生变化,因而之前的所有路由工作都白费了。在任何时刻,Ad hoc网络都可以用连接节点的图来描述。如果两个节点可以直接通信,则这两个节点是连接的。我们采用了一个简单恰当的模型,即每个节点都可以与位于其覆盖范围内的其他节点通信。实际网络要复杂得多,可能有建筑物、山坡或者其他妨碍通信的障碍物,还可能出现这种情况情况:节点A连接到节点B,但是节点B却无法连接到节点A,因为A有比B更强大的功率。为了简化起见,假设所有的连接都是对称的。
- 图中是一个Ad hoc网络。假设节点A上的一个进程想要给节点 I 上的一个进程发送数据包。AODV算法在每个节点上维护了一张距离矢量表,以目标节点作为关键字,每个表项给出了有关该目标节点的信息,包括将数据包发送给哪个邻居才可以到达这个目标。首先,A检查自己的表,没有发现针对 I 的表项。因此,它必须去发现一条通向 I 的路径。

- 为了找到节点 I ,A构造一个ROUTE REQUEST(路由请求)包,并且使用前述的泛洪算法广播它。该包从A被传输到B和D,如图所示。每个节点重新广播,该包继续达到节点F、G和C → 节点H、E和 I 。源端设置的一个序号用来淘汰泛洪算法过程中的重复请求包。例如,D丢弃来自B的传输,因为它已经转发过请求数据包了。
- 最后请求包到达节点 I ,节点 I 构造一个ROUTE REPLY(路由应答)包。这个包沿着请求包所遵循的路径逆向单播给发送者。这项工作要求每一个中间节点必须记住给它发送请求包的节点。如图b\c\d所示,虚线表示可能的逆向路由,实现表示发现的路由。每个中间节点在转发应答数据包时还要讲跳数递增1,告诉节点到目标节点多远。应答数据包还告诉每个中间节点,使用哪个邻居能到达目标节点。节点G和D在处理应答数据包时把听到的最好的路由填入它们的路由表中。当该应答包到达节点A,一条新路由ADGI就被创建出来。
- 在一个大型网络中,AODV算法会产生许多广播包,即使对于比较近的目标也是如此。为了减少开销,可以使用IP包的Time to live字段来限制广播范围。该字段由发送者初始化,并且每经过一跳该字段被减1。如果该字段被减到0,则把包丢弃,不再广播。因此,路由发现过程可以作如下修改:为了发现一个目标,发送者广播一个ROUTE REQUSET包,其中TTL字段设置为1。如果在一段合理的时间内没有应答包返回,则再发送一个ROUTE REQUSET包,这次将TTL字段设置为2。以后的每一次尝试分别使用TTL的3、4等值,按照这种方法,搜索过程首先在本地进行,然后扩大到更大的范围。(Windows系统下可以设置,也可以使用pathping和tracert命令跟踪).
路由维护
- 因为节点可以移动或关闭,所以网络的拓扑结构也自然会发生变化。路由算法必须能够处理这样的情况。每个节点周期广播一个HELLO消息,并且期望它的邻居做出响应。如果没有响应到来,消息的广播这就知道它的邻居已经离开接收范围或者失效。类似地,如果它试图给一个邻居发送数据包而没有响应,那么它也知道邻居不可用。
- 这些信息可被用来清除掉那些不再有效的路由。对于每一可能的目标节点,每个节点(比如说N)记录自己的活跃邻居,即那些在最近时间给它发过到达该目标的数据包。当N的邻居变得不可达时,它就检查自己的路由表看哪些通往目标节点的路由使用了刚刚离开的邻居。对于这些路径中的一个,通知相应的活跃邻居,因为它们经过N的路径不再有效,必须从路由表中删除。一般情况下,活跃邻居在告诉它们自己的活跃邻居,如此递归下去,直到所有依赖走掉节点的路由从全部路由表中删除。
- 在这个阶段,无效的路由器已被清除出网络,发送者可以使用我们描述过的路由发现机制来发现新的有效路由。然而,这里有一点复杂,距离矢量协议可能有慢收敛问题,或者拓扑发生变化后的无穷计数问题,这些问题把新的有效路由和旧的无效路由混淆在一起。为了保证快速收敛,路由包括了一个由目标节点控制的序号。目标序号就像个逻辑时钟。目标节点每次发送一个新的ROUTE REPLY时就递增该序号。发送者请求发现一条新路由时,就在ROUTE REQUEST请求报文中包括它最后使用的那条路由的序号,这个序号要么是刚刚被清除的路由的序号,要么作为初始值被设置为0。该求情报文将被广播直到发现一条具有更高序列的路由。中间节点储存具有更高序号的路由,或者当前序号下具有更少跳的路由。(混乱)
- 按需协议的精髓在于中间节点只储存正在使用中的路由。在广播期间了解的其他路由信息经过短暂延迟后会超时。相比需要定期广播路由更新信息的标准距离矢量协议,只发现并储存那些要使用的路由有助于节省带宽和电池寿命。到目前为止,我们已经考虑过网络中只有单条路由的情况,即从 A 到 I 。为了进一步节省资源,路由发现和路由维护可被重叠的路由共享。例如,如果B也想给 I 发送数据包,它将执行路由发现。然而,在这种情况下,请求报文首先到达D,而D已经有了一条路由可以通向 I 。因此节点 D 生成一个路由应答报文,告诉B这条路由无需做任何额外工作。
- 还有许多其他的Ad hoc路由方案。另一个著名的按需路由方案是动态源路由(DSR)。贪婪边界无状态路由(GPSR)则探讨了另一种基于地理位置信息的不同的路由策略。如果所有节点知道它们的地理位置,则数据包的转发无需进行路由计算,只需简单地朝着正确的方向,并绕开任何死角即可。究竟哪个路由协议能胜出将取决于Ad hoc网络的类型,必须时间证明对这种网络是有效的。