本文首发于微信公众号《与有三学AI》
为AI摄影铺路,第一个大规模的美学质量数据库
不知道你有没有读过笔者之前发过的一篇文章?
《干掉柯洁的下一步,阿尔法狗创始人又要毁掉这个行业(深度学习)》
文章在在公众号和知乎专栏都有,
AI的确对摄影的方方面面带来了很大的冲击,那么,当深度学习没有起来之前,计算机又是怎么玩摄影的呢?
从今天起,我们会分享一段时间的计算机美学方面的研究。所谓计算机美学,直白点就是给图片打个分,告诉你这是张高质量图片还是低质量图片。当然不直白点说,咱们就慢慢来吧。
今天,也是这个系列的第一篇,我们先从AVA美学质量评估数据库说起。因为数据是机器学习里最重要的东西,所以也算是合情合理。
1 AVA Dataset【1】是什么?
这是一个美学质量评估的数据库,包括250000张照片。每一张照片,都有一系列的评分,以及语义级别的label,其中语义级别的label共60类,同时还有photographic style,也就是照片的风格,有14类,文后详说。
一句话总结:在规模,多样性和标注的一致性上,都不是以往的数据库可以比拟的。
在文章后面作者们还举了3个应用的例子,强调了该数据库的意义。
2 AVA Dataset都做了什么标注?
2.1 Aesthetic annotations
顾名思义,美学质量标注。每一张图,都有若干人来投票,投票的数量从78~549。大概每一张图,有210个投票。投票的分数,从0~9,分值越高,说明图片质量越高。
并且,标注者中不止包括了专业的图像工作者,摄影师,也包括了摄影爱好者,这样显得更有普适性。
2.2 Semantic annotations
什么是语义标注呢?顾名思义,就是图像中到底包含了什么内容。具体来说,这个数据集包含了66个textual tags。大概有200000张图只包含一个tags,150000张图包含2个tags。
哪些tags最多呢,作者们也作出了一个统计。
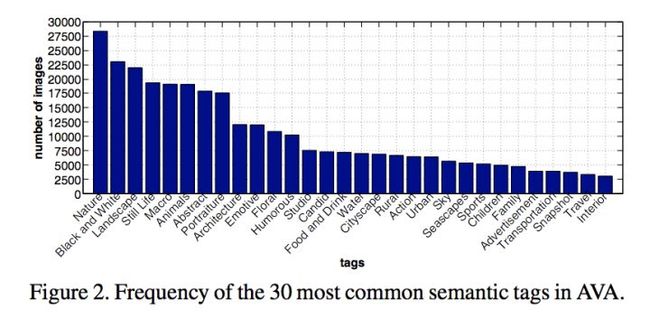
从中可以看出,这些tags都不在一个维度的。
怎么说呢,有的是描述图像的内容,比如water,architecture,有的是描述图像的风格,比如black and white。
2.3 Photographic style annotations
好了,这个是比较难理解的一个部分 。为什么呢?因为真正的涉及到摄影美学了。从3大方向开始描述:
light, colour, composition。
最终得到了14个属性:
下面列出了所有属性,以及包含该属性的图片数量。
Complementary Colors (949), Duotones (1,301), High Dynamic Range (396), Image Grain (840), Light on White (1,199), Long Exposure (845), Macro (1,698), Motion Blur (609), Negative Image (959), Rule of Thirds (1,031), Shallow DOF (710), Silhouettes (1,389), Soft Focus (1,479), Vanishing Point (674).
就不翻译了,大家可以先对着去看中文。
如果对摄影相关的术语还不太懂,可以去我的摄影公众号《言有三工作室》去学习。
反正也不用着急,因为我们会慢慢道来。
3 AVA Dataset靠不靠谱?
AVA不是第一个美学质量数据库,也不是最后一个,但是仍然是最大的美学数据集。
下面是AVA与其他的数据集做的比较:
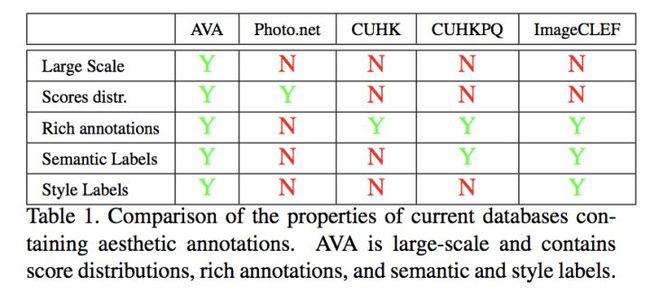
其中,现在看来很多的维度都非常重要。
比如,当全局的美学平均分不够用时,AVA也提供了一个分布,而且每张图的标注数量很大,有偏性就很了。
另外,Semantic 和 style label现在甚至都可以单独当作一个问题来研究的。
不过,由于美学是一个很主观的东西,虽然每一张图都有人投票,但是评分到底靠不靠谱,
个体差异会不会很大呢?
作者做了分数分布统计,如下:
(1) 首先,分数的极端,也就是0和9分的占比。2~8分占超过99.77%的量,所以0和9的比例非常低,不必担心评分过于离谱。
(2) 再看各个区间,如下图。
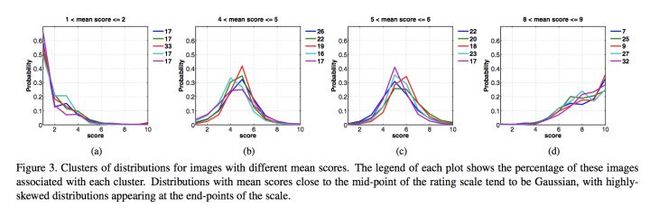
可知,对于分值接近于5的,分布是很明显的高斯,这说明投票比较一致。而对于分值很高或者很低的,也分别在两侧有很陡的表现。综合表现说明,所有投票基本是达到一致结论的。
从下面方差图可以看出,越是分值接近于0.5的,越是方差小,说明越是稳定。

关于这个方差,作者也举例说明了:

如上图,都是在5分左右的图。上面一组图的方差小,这说明大家比较能达成一致,认为是5分左右,也就是一般般的图,不好不坏。但是下面的方差大,这说明有些人认为很好,有些人认为很差。
这种情况,通常出现在比较抽象的图。
综上,AVA dataset很靠谱。
4 提一下应用
4.1 Large-Scale aesthetic quality categorization
应用于图像质量评估。
作者实验表明,随着数据库量级的增大和训练图像质量的增加,原来的各种方法都能在原有基础上得到提升。
4.2 Content-based aesthetic categorization
基于内容的图像质量聚类。作者取了最多的8个类别,训练了3个分类器:
(1) 训练了8个独立的SVM二分类器。
(2) 从这些类别中随机取了同样数量的图训练了1个分类器。
(3) 从AVA中随机选了10倍于(1),(2)中图像数量的图做了训练。
结果表明,第(1)个分类器效果好于第(2)个,而第(3)个又好于第(1)个,所以,可见越大的数据集,是有效的。 4.3 style categorization
作者训练了14个分类器,然后观察结果表明,对于”duotones”,“complementary colors”,“light on white”等,颜色直方图是最好的特征。而对于,“shallow depth of field”,“vanishing point”,SIFI和LBP是最好的特征。这些表明,对于不同style的照片,需要不同的特征来描述,所以style的标注是非常有意义的。
更多请移步
1,我的gitchat达人课
龙鹏的达人课
2,AI技术公众号,《与有三学AI》
【走向AI摄影终极之路 · 第二篇】 没有AVA数据集的时候,大家用什么?
3,以及摄影号,《有三工作室》
论我眼中的国产动画崛起
[1] AVA: A Large-Scale Database for Aesthetic Visual Analysis
http://gitbook.cn/m/mazi/activity/5a10fa46a625c025b1800fc3?giftToken=a8c65830-ccd9-11e7-a69c-c935a9531f2d&sut=844a9360d28611e79254eb304c8a2a1e