用pyecharts生成仪表盘——将多张图片汇总到一个页面,大屏可视化数据展示
(前情提要)我爬了拉勾网搜索“设计”职位的招聘信息,详见Python爬虫获取拉勾网招聘信息并用pyecharts画了地图Geo,Map,条形图,饼图,词云图以及箱线图。详见拉勾网“设计”职位数据分析之用pyecharts画地图Geo,Map,拉勾网“设计”职位数据分析之用pyecharts画条形图Bar,拉勾网“设计”职位数据分析之用pyecharts画饼图(南丁格尔图玫瑰图)Pie,拉勾网“设计”职位数据分析之用pyecharts画词云图,拉勾网“设计”职位数据分析之用pyecharts画箱线图。
接下来,就用pyecharts里的page,将前面生成的统计图都汇总 到一个页面,并生成大屏可视化数据展示。
import json
import pandas as pd
import numpy as np
import jieba
import jieba.analyse
from pyecharts import options as opts
from pyecharts.charts import Geo,Map,Bar, Line, Page,Pie, Boxplot, WordCloud
from pyecharts.globals import ChartType, SymbolType,ThemeType
我把之前的生成各个统计图的代码都写到函数里啦,在此就不再赘述了。
#数据分析
#画各个省市招聘人数块地图
def setmap(df):
#转化省份信息
dfp = pd.read_excel('province.xlsx')
df_new = pd.merge(df,dfp.loc[:,['city','province']],how='left',on = 'city')
result=pd.value_counts(df_new['province'])
resultp=dict(result)
province = list(resultp.keys())
values = list(resultp.values())
valuesint=[]
for i in values:
valuesint.append(int(i))
c = (
Map(init_opts=opts.InitOpts( theme=ThemeType.LIGHT))#设置主题
.add("各个省市招聘人数", [list(z) for z in zip(province, valuesint)], "china",is_map_symbol_show=False, tooltip_opts=opts.TooltipOpts())
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="各个省市招聘人数"),
visualmap_opts=opts.VisualMapOpts(max_=200,is_piecewise = True,#图例分段显示
))
)
return c
#画各个省市招聘人数条形图
def setbar(df):
#转化省份信息
dfp = pd.read_excel('province.xlsx')
df_new = pd.merge(df,dfp.loc[:,['city','province']],how='left',on = 'city')
result=pd.value_counts(df_new['province'])
resultp=dict(result)
province = list(resultp.keys())
values = list(resultp.values())
valuesint=[]
for i in values:
valuesint.append(int(i))
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))#设置主题
.add_xaxis(province)#x轴为省份
.add_yaxis("人数",valuesint)#y轴为人数
.set_global_opts(title_opts=opts.TitleOpts(title="各个省市招聘人数"))
.set_series_opts(
label_opts=opts.LabelOpts(is_show=False),
#插入平均值线
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average", name="平均值"),]),
#插入最大值最小值点
markpoint_opts=opts.MarkPointOpts(data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
])
)
)
return c
#画学历饼图
def setpai(df):
result=pd.value_counts(df['education'])
resulted=dict(result)
ed = list(resulted.keys())
edvalues = list(resulted.values())
edvaluesint=[]
for i in edvalues:
edvaluesint.append(int(i))
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add(
"",
[list(z) for z in zip(ed, edvaluesint)],
radius=["30%", "75%"],
center=["25%", "50%"],
rosetype="radius",
label_opts=opts.LabelOpts(is_show=False),
)
.add(
"",
[list(z) for z in zip(ed, edvaluesint)],
radius=["30%", "75%"],
center=["75%", "50%"],
rosetype="area",
)
.set_global_opts(title_opts=opts.TitleOpts(title="学历要求"))
)
return c
#画不同工作经验的薪酬分布箱线图
def setbox(df):
#处理薪酬数据
pattern = '\d+'
# 将字符串转化为列表,薪资取最低值加上区间值得25%,比较贴近现实
df['salarys'] = df['salary'].str.findall(pattern)
#
avg_salary_list = []
for k in df['salarys']:
int_list = [int(n) for n in k]
avg_salary = int_list[0] + (int_list[1] - int_list[0]) / 4
avg_salary_list.append(avg_salary)
df['月薪'] = avg_salary_list
#处理工作年限数据
df['workYears']=df['workYear'].replace({'应届毕业生':'1年以下','不限':'1年以下'})
groupby_workyear=df.groupby(['workYears'])['月薪']
count_groupby_workyear=groupby_workyear.count()
count_groupby_workyear=count_groupby_workyear.reindex(['1年以下','1-3年','3-5年','5-10年'])
a = count_groupby_workyear.index
dff=[]
for b in a:
c=groupby_workyear.get_group(b).values
dff.append(c)
c = Boxplot(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
c.add_xaxis(['1年以下','1-3年','3-5年','5-10年']).add_yaxis("薪酬k/月", c.prepare_data(dff)
).set_global_opts(title_opts=opts.TitleOpts(title="不同工作经验的薪酬分布"))
return c
#画设计类型饼图
def setrose(df):
result=pd.value_counts(df['secondType'])
resultst=dict(result)
st= list(resultst.keys())
stvalues = list(resultst.values())
stvaluesint=[]
for i in stvalues:
stvaluesint.append(int(i))
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add(
"",
[
list(z)
for z in zip(
st ,
stvaluesint ,
)
],
#设置圆心坐标
center=["40%", "57%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="设计类型"),
legend_opts=opts.LegendOpts(
type_="scroll", pos_left="80%", orient="vertical",pos_top="15%"
),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
return c
#画岗位需求词云图
def setword(df):
needs=[]
for i in df['need']:
needs.append(i)
set_need=str(needs).replace('n1',"").replace('n2',"").replace('n3',"").replace('n4',"").replace('n5',"").replace('n6',"").replace('n7',"").replace('n',"")
cut = jieba.lcut(set_need)
need_cut=' '.join(cut)
#设置停止词,删除跟岗位需求无关的词
stopwords = ['nan','具备','岗位职责','任职','相关','公司','进行','工作','根据','提供','作品','以上学历','优先','计算','经验','学历','上学','熟练','使用','以上',
'熟悉','能力','负责','完成','能够','要求','项目','制作','具有','良好','行业','专业','设计','团队','岗位','优秀','我们','关注'
,'xa0','产品','软件','n6','视频','创意','游戏','需求','视觉','大专','本科','各种','以及','n7','了解','职位','结果'
]
jieba_need = jieba.analyse.extract_tags(set_need, topK=80, withWeight=True)
jieba_result=[]
for i in jieba_need:
if i[0] not in stopwords:
jieba_result.append(i)
c = (
WordCloud(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add("", jieba_result, word_size_range=[20, 100],shape=SymbolType.RECT)
.set_global_opts(title_opts=opts.TitleOpts(title="岗位需求"))
)
return c
下面重点来了,首先需要保证你的pyecharts版本在1.4以上,我这里安装了最新版本的pip install pyecharts==1.7.1,还有page = Page(layout=Page.DraggablePageLayout)记住这句话是关键信息!
df = pd.read_excel('lagou_sj.xlsx')
page = Page(layout=Page.DraggablePageLayout)
page.add(setword(df),setrose(df),setbox(df),setpai(df),setbar(df),setmap(df))
page.render("test.html")
这时候打开保存好的"test.html"文件,大概是这个样子(我稍微压缩了一下,不然截图不方便)
你会看到有很多虚线的方格,这些模块就是我们之前生成的统计图,接下来就是见证你的美术(拼图)功底的时候啦,点击鼠标可以放大缩小,拖动位置,把这些图片排成你喜欢的亚子。
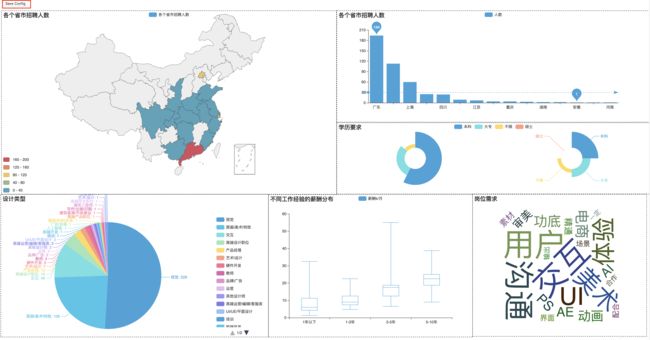
之后一定要点一下左上角的Save Config按钮,会自动下载一个保存了你刚才设置的json,再用这个文件“格式化”你的page并保存
Page.save_resize_html("test.html",
cfg_file="chart_config.json",
dest="my_test.html")
补充强调一下,我是用jupyter notebook写的代码,可以一行一行运行所以没有注意到,如果用别的IDE的小伙伴,运行Page.save_resize_html之前,一定要把前面的page.render("test.html")这句注释掉啊!!!
df = pd.read_excel('lagou_sj.xlsx')
page = Page(layout=Page.DraggablePageLayout)
page.add(setword(df),setrose(df),setbox(df),setpai(df),setbar(df),setmap(df))
#page.render("test.html")
Page.save_resize_html("test.html",
cfg_file="chart_config.json",
dest="my_test.html")

这就是我们最终的结果啦,我还做了一个底色是黑色的(在生成每张统计图的时候设置一下主题,其他环节都是一样滴)
另外还可以通过修改其他参数来调整最后的html,不过涉及到前端的知识,我就不在这里班门弄斧啦。本次的关于『拉勾网“设计”职位数据分析』系列到这里就告一段落啦,主要是为了记录一下自己学习的心路历程,有不足之处还望各位大神多多包涵,多多交流

本文学习了@乌 鸦 坐 飞 机 大神的pyecharts实现新冠肺炎疫情可视化并搭建BI数据大屏(Plus),小伙伴们也可以移步去那里学习鸭