【论文解读 EMNLP 2019】Joint Event and Temporal RE with Shared Representations and Structured Prediction

论文题目:Joint Event and Temporal Relation Extraction with Shared Representations and Structured Prediction
论文来源:EMNLP 2019 南加利福尼亚大学,伊利诺伊大学香槟分校
论文链接:https://www.aclweb.org/anthology/D19-1041/
关键词:联合学习,事件抽取,时序关系抽取,BERT,Bi-LSTM
文章目录
- 1 摘要
- 2 引言
- 3 联合的事件-事件关系抽取模型
- 3.1 Neural SSVM
- 3.2 多任务的神经打分函数
- 3.3 MAP Inference
- 3.3.1 目标函数
- 3.3.2 限制
- 3.4 学习
- 4 实施细节
- 4.1 Baselines
- 4.2 端到端的事件时序关系抽取
- 5 实验
- 6 总结
1 摘要
本文解决的是事件和事件关系(本文研究的是时序关系)的联合抽取任务。
本文的模型和现有的方法比较,有两个优点:
(1)允许事件模块和关系模块共享相同的上下文嵌入和神经表示学习器,有助于事件表示的学习。
(2)采用联合学习的方式,分配事件标签和关系标签,避免了传统的pipeline方法误差传播的问题。
实验显示,本文提出的模型在EE和时序关系抽取任务上超越了state-of-the-art。
2 引言
(1)任务介绍
事件间的关系抽取是自然语言理解(NLU)中一项重要的任务,有助于处理多种下游任务,比如问答、信息检索和叙述生成。
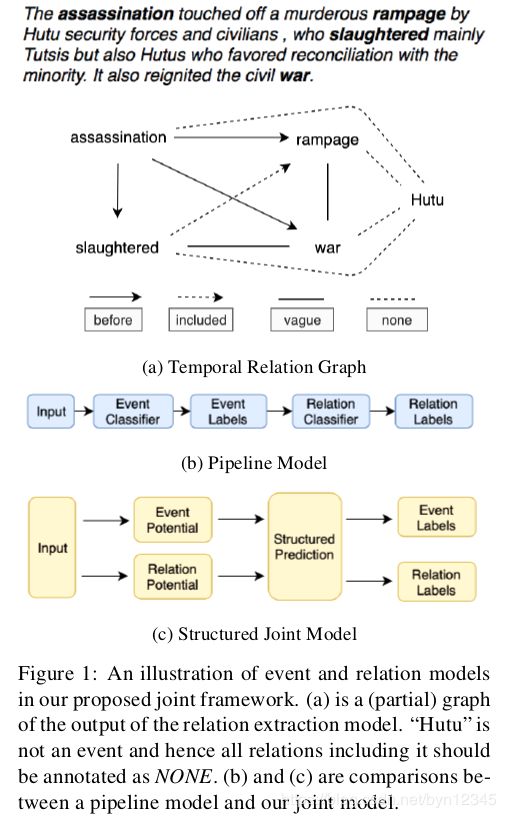
给定一个文本,该任务可以建模成一个图,图中的节点是事件,边是相对应的关系。图1 a就是一个例子,图中的节点assassination, slaughtered, rampage, war, 和 Hutu都是候选的事件节点,不同类型的边表示它们之间不同类型的关系。由于“Hutu”实际上不是一个事件,因此系统要能识别出“Hutu”和图中其他节点的关系是NONE,也就是没有关系。
(2)现有的方法
现有的方法都是使用pipeline的形式将这一任务分解成两个子任务:事件抽取(EE)和关系分类,并且假定在训练关系分类器时,给定了准确的事件。pipeline模型会将EE模块中产生的误差传递到关系分类器模块。
(3)本文贡献
1)第一个提出联合学习的模型,同时抽取出事件和关系,如图1 c所示。(受实体和关系联合学习模型的启发)
作者认为,如果使用非事件节点间的NONE关系训练关系分类器,则会有潜在的纠正EE错误的能力。以图1 a为例,如果关系分类器以高可信度预测 ( H u t u , w a r ) (Hutu, war) (Hutu,war)间的关系为NONE,这就为事件分类器提供了一个很强的信号:Hutu和war中至少有一个不是事件节点。
2)通过在EE模块和关系抽取模块共享相同的上下文嵌入和神经表示学习器,改进了事件的表示。
本文的模型在共享的嵌入和神经表示学习器的基础上,生成了图结构的输出,以表示给定句子中的所有事件和关系。
3)第一个使用神经的事件抽取器(neural event extractor)处理时序关系抽取,并证明了方法的有效性。(不是主要贡献)
有效的图预测应该满足两个结构上的限制:
1)若两个节点中有任意一个不是事件,则它们间的关系应该是NONE;
2)图中的关系指的是事件间的时序关系,所以不能有环。
通过求解一个带有结构约束的整数线性规划(ILP)优化问题,保证了图的有效性。本文的联合模型使用neural SSVM(structural support vector machines)以端到端的形式进行训练。
3 联合的事件-事件关系抽取模型
首先对本文的neural SSVM模型进行概述,然后对各个模块进行详细介绍:1)多任务的神经打分模块;2)模型如何进行推断和学习。
R \mathcal{R} R表示所有可能的关系标签的集合(包括NONE), E \mathcal{E} E表示所有的候选事件节点集合, E E \mathcal{EE} EE表示所有的候选关系。
3.1 Neural SSVM
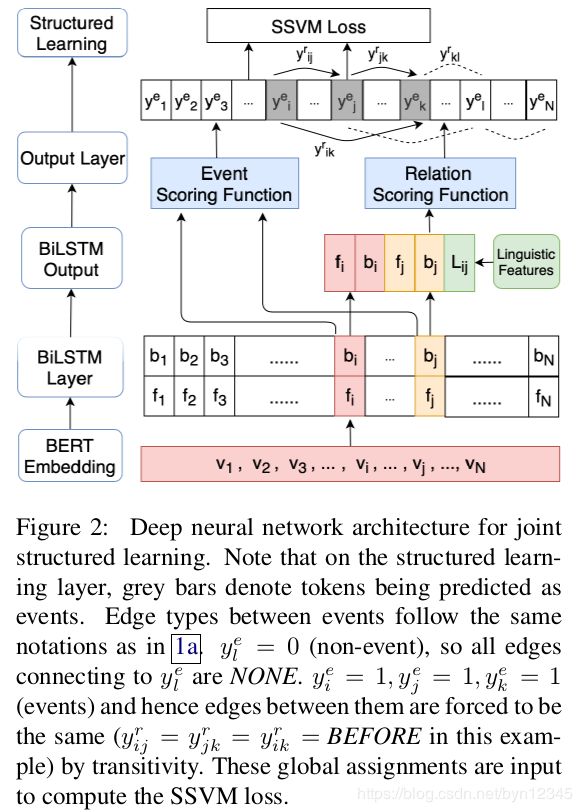
模型架构如图2所示:
损失函数为:
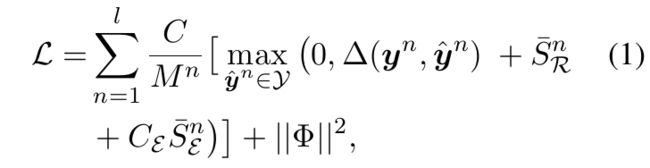
- S ˉ E n = S ( y ^ E n ; x n ) − S ( y E n ; x n ) \bar{S}^n_{\mathcal{E}} = S(\hat{y}^n_{\mathcal{E}}; x^n) - S(y^n_{\mathcal{E}}; x^n) SˉEn=S(y^En;xn)−S(yEn;xn);
- S ˉ R n = S ( y ^ R n ; x n ) − S ( y R n ; x n ) \bar{S}^n_{\mathcal{R}} = S(\hat{y}^n_{\mathcal{R}}; x^n) - S(y^n_{\mathcal{R}}; x^n) SˉRn=S(y^Rn;xn)−S(yRn;xn);
- Φ \Phi Φ表示模型参数;
- n n n表示实例的索引;
- M n = ∣ E ∣ n + ∣ E E ∣ n M^n=|\mathcal{E}|^n + |\mathcal{EE}|^n Mn=∣E∣n+∣EE∣n,表示实例 n n n中关系数量和事件数量的和;
- one-hot向量 y n y^n yn和 y ^ n \hat{y}^n y^n分别表示实例 n n n中事件和事件间关系标签的实际值和预测值。关系标签: y R n , y ^ R n ∈ { 0 , 1 } ∣ E E ∣ y^n_{\mathcal{R}}, \hat{y}^n_{\mathcal{R}}\in {\{0, 1}\}^{|\mathcal{EE}|} yRn,y^Rn∈{0,1}∣EE∣;实体标签: y E n , y ^ E n ∈ { 0 , 1 } ∣ E ∣ y^n_{\mathcal{E}}, \hat{y}^n_{\mathcal{E}}\in {\{0, 1}\}^{|\mathcal{E}|} yEn,y^En∈{0,1}∣E∣;
- Δ ( y n , y ^ n ) \Delta(y^n, \hat{y}^n) Δ(yn,y^n)表示真实值和预测值间的汉明距离;
- 超参数 C C C和 C E C_{\mathcal{E}} CE用于权衡事件和关系的损失,以及正则损失;
- S ( y E n ; x n ) , S ( y R n ; x n ) S(y^n_{\mathcal{E}}; x^n), S(y^n_{\mathcal{R}}; x^n) S(yEn;xn),S(yRn;xn)是通过多任务的神经架构学习到的打分函数。
最大化后验概率(MAP)得到 y ^ n \hat{y}^n y^n,并形式化为ILP问题,在3.3节中详细介绍。
损失函数的训练目标是最小化 Δ ( y n , y ^ n ) \Delta(y^n, \hat{y}^n) Δ(yn,y^n)。
本文的neural SSVM和传统的SSVM的区别在于打分函数。传统的SSVM使用线性函数和人为设计的特征来计算分数;本文的nural SSVM使用RNN估计出打分函数,并端到端地进行训练。
3.2 多任务的神经打分函数
RNN架构广泛用于先前的时序关系抽取工作,RNN编码了上下文信息。受这些工作的启发,作者提出了基于RNN的打分函数,用于事件和事件间关系的预测,用数据驱动的方式学习到特征,并捕获到输入中较长依赖的特征。
如图2所示,底层对应于使用预训练模型BERT得到的词表示,记为 v k v_k vk。然后将其输入到Bi-LSTM层中,进一步编码特定任务的上下文的信息。事件抽取和事件间关系抽取任务共享这个Bi-LSTM层。
图2中Bi-LSTM层后的左边两个分支,是将每个token前向和后向隐层向量直接拼接,用于事件打分函数的计算。
右边两个分支,对于每个候选事件对 ( i , j ) (i, j) (i,j),分别得到两个候选事件的前向和后向隐层向量,将它们和语言学特征 L i , j L_{i, j} Li,j拼接起来作为输入,去计算关系标签的概率分布。
语言学特征是从原始数据集中得到的简单的特征:token距离,时态,事件的极性。
( i , j ) ∈ E E (i, j)\in \mathcal{EE} (i,j)∈EE表示候选的关系, i i i表示候选的事件。
事件打分函数和关系打分函数就是基于RNN的打分函数,下一小节将进行介绍。
3.3 MAP Inference
在训练过程中需要进行MAP inference,以得到损失函数中的 y ^ n \hat{y}^n y^n;在测试时也需要进行MAP inference,以得到全局一致的结果。我们将这个推断问题形式化为一个ILP问题。
使用得到的局部分值并进行一些全局的限制,构建全局的目标函数,以形成推断框架。全局的限制有:1)预测是单标签的;2)事件-事件关系的一致性;3)对称性和传递性。
3.3.1 目标函数
全局推断的目标函数是找到概率最高的全局标签分配,如下式所示:

- y k e y^e_k yke是指示器,表示第 k k k个候选是否为一个事件;
- y i . j r y^r_{i. j} yi.jr也是一个指示器,表示 ( i , j ) (i, j) (i,j)间是否预测有关系 r ∈ R r\in R r∈R;
- S ( y k e , x ) , ∀ e ∈ { 0 , 1 } S(y^e_k, x), \forall e\in {\{0, 1}\} S(yke,x),∀e∈{0,1}和 S ( y i , j r , x ) , ∀ r ∈ R S(y^r_{i, j}, x), \forall r\in R S(yi,jr,x),∀r∈R分别是事件打分函数和关系打分函数;
- C E C_{\mathcal{E}} CE是超参数
紧跟目标函数的一个限制是:对于所有的实体和关系,只能分别对其分配一个标签。
3.3.2 限制
引入一些附加的限制以保证事件图的有效性和合理性。
(1)事件-事件关系一致性
定义为:输入的一对tokens有正向的时序关系,当且仅当这两个tokens都是事件节点。如下的全局限制可以满足这一性质:
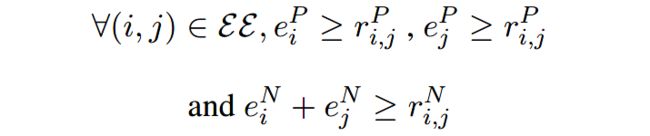
其中 e i P e^P_i eiP表示事件的token, e i N e^N_i eiN表示非事件的token; r i , j P r^P_{i, j} ri,jP表示正向的关系:BEFORE, AFTER, SIMULTANEOUS, INCLUDES, IS_INCLUDED, VALUE; r i , j N r^N_{i, j} ri,jN表示负向的关系,例如NONE。
这一属性的证明见原文附录A
(2)对称性和传递性限制
作者还引入了关系的对称性和传递性限制,规定如下:

对称性表示如果将一个事件对的顺序颠倒,则颠倒后的事件对的关系也应该颠倒。例如,若 r i , j = B E F O R E r_{i, j}=BEFORE ri,j=BEFORE,则 r j , i = A F T E R r_{j, i}=AFTER rj,i=AFTER。
传递性表示,若图中存在 ( i , j ) , ( j , k ) (i, j), (j, k) (i,j),(j,k)和 ( i , k ) (i, k) (i,k),则 ( i , k ) (i, k) (i,k)的关系标签应该由 ( i , j ) (i, j) (i,j)和 ( j , k ) (j, k) (j,k)决定。
3.4 学习
作者在实验中直接对SSVM损失进行优化,但发现模型的性能却下降了。
因此,作者使用了一个两阶段的学习方法,首先用pipeline的当时训练联合模型,不使用来自全局约束的反馈。也就是说,使用从事件模型的输出直接构建出的候选关系以及真实的事件,形成交叉熵损失,以对局部的神经打分函数进行优化。
在第二个阶段,使用式(1)中的全局SSVM损失函数,重新优化网络以调整全局属性。
在下一节中介绍更多细节。
4 实施细节
对baselines进行介绍,并介绍我们构建的端到端事件时序关系提取系统的4个模型,并重点介绍结构化的联合模型。
4.1 Baselines
运行了两个事件和关系抽取模型:在TB-Dense数据集上运行CAEVO模型,在MATRES数据集上运行CogCompTime模型。
这两个方法都是基于人为设计的特征,使用传统的学习算法进行优化,并且是pipeline的方式。
4.2 端到端的事件时序关系抽取
(1)单任务模型
构建一个端到端的系统,最基本的方法就是分别训练事件检测模型和关系预测模型。即图2中的Bi-LSTM层不共享。
在验证和测试阶段,使用事件检测模型的输出构建出关系候选,并使用关系预测模型来进行最终的预测。
(2)多任务模型
Bi-LSTM层在两个任务中共享,其他的和单任务模型一样。
需要注意的是,单任务和多任务模型在训练中都没有直接处理NONE关系。它们都依赖于事件模型的预测来标注关系是正向的还是NONE。
(3)Pipeline联合模型
模型架构和多任务模型一样,区别在于pipeline的联合模型在训练阶段,使用事件模型来构建关系候选,以用于训练关系模型。
使用这一策略,在训练阶段若一个候选关系的元素不是事件,则会生成NONE对。这些NONE对会帮助关系模型分辨出正关系和负关系,从而增强对事件预测误差的鲁棒性。
作者采用的是:在训练的前几个epoch中,先使用真实的事件和关系候选,以得到相对准确的事件模型,然后再转换到pipeline的版本。
(4)结构化的联合模型
这一模型在第3节中有介绍。
但是,作者在直接使用SSVM损失对模型进行训练时遇到了困难。这是由于有大量的非事件的token,模型在一开始不具备分辨出它们的能力。
因此,作者采用了两阶段(two-stage)的学习方法:先使用最佳的pipeline联合模型,然后使用SSVM损失重新对模型进行优化。
为了限制SSVM损失的ILP推断中事件的搜索空间,作者使用了从事件检测模型中得到的预测概率,对非事件进行过滤。
注意,结构化的联合模型和pipeline模型有很大的不同。pipeline模型是先对事件进行预测,然后使用预测出的事件构建关系。这里的结构化的联合模型仅使用一个超参数 T e v t T_{evt} Tevt来过滤掉高度不相关的候选事件。
事件标签和关系标签是在使用ILP进行全局推断时同时分配的,如3.3节所述。
我们还会过滤掉有POS标签的tokens(表示在训练集中没有出现过),因为TB-Dense数据集中大多数的事件都是名词或者动词,MATRES数据集中所有的事件都是动词。
5 实验
(1)时序关系数据集
TB-Dense,MATRES
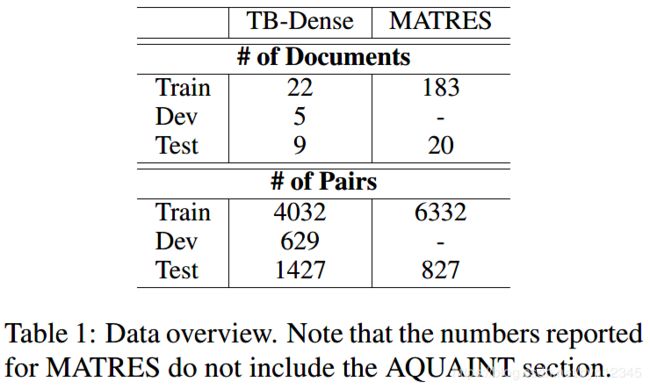
(2)实验任务
事件抽取,事件时序关系抽取
(3)评价度量
- micro-average scores
- 排除了NONE和VAGUE对
两种度量的可视化见附录中的图4
(4)实验结果
本文的方法在两个数据集上的实验结果:

消融实验对比结果:

6 总结
本文提出了一个端到端的事件时序关系抽取的系统。
作者提出了一个神经结构的预测模型,进行联合的表示学习,以实现对事件和关系的同时预测。
联合学习可以避免pipeline系统带来的误差传播问题。
实验证明了本文的模型可以使用端到端的方式,有效地处理事件时序关系抽取任务,并且在两个数据集上实现了state-of-the-art。
未来工作:
(1)在事件和关系间构建更鲁棒的结构化约束,比如考虑事件的类型,来提高使用ILP在全局进行标签分配的质量。
(2)由于事件模型有助于关系的抽取,所以还可以考虑使用多个数据集来增强事件抽取系统的性能。
本文解决的任务是事件抽取和事件间时序关系的抽取。
本文的亮点在于:
(1)第一个提出了联合学习的模型,同时处理上述的两项任务。已有的对事件和关系进行抽取的任务都是pipeline形式的,这就会将事件抽取时产生的误差带到关系抽取模型中,并且这个误差是在训练关系抽取模型时不能优化的。已有一些研究,提出了对实体和关系进行联合抽取的模型,本文的模型正是受这些工作的启发而提出的。
(2)针对事件抽取和事件间时序关系的抽取两个任务,使用了一层Bi-LSTM,实现了表示的共享,有助于两个任务相互促进。
我认为本文的不足之处在于:
(1)只是共享了第一层Bi-LSTM,没有共享更深层的表示。DyGIE模型就针对这一问题,进行了改进。
(2)本文实现了事件和关系的联合抽取,此处的关系指的是事件间的时序关系,事件间应该还有多种多样的关系(比如逻辑关系),如何对这类关系进行抽取有待研究。
本文的一些细节还需要看附录,我没有阅读附录,日后如果有需要再进行精读。