【论文解读 KDD 2018 | PinSage】Graph Convolutional Neural Networks for Web-Scale Recommender Systems

论文链接:https://arxiv.org/abs/1806.01973
论文来源:KDD 2018 斯坦福大学, Pinterest
关键词:GCN,推荐系统,web-scale,PinSage
本文在GraphSAGE基础上进行改进(去掉了需要将整张图存储到内存中的限制),提出PinSage模型,成功在Pinterest的推荐系统上得到了应用,第一个将图卷积(GCN)在超大规模数据集上实现落地应用的方法。
知乎优质文章推荐阅读:全面理解PinSage
文章目录
- 1 摘要
- 2 引言
- 3 相关工作
- 4 方法
- 4.1 问题设置
- 4.2 模型架构
- 4.3 模型的训练
- 4.4 Node Embeddings via MapReduce
- 4.5 Effcient nearest-neighbor lookups
- 5 实验
- 5.1 数据集
- 5.2 实验任务
- 5.3 使用的特征
- 5.4 对比方法
- 5.5 Offline Evaluation
- 5.6 User Studies
- 5.7 运行时间
- 6 总结
- 参考文献
1 摘要
基于图结构数据的深度神经网络方法,在推荐系统的应用中取得了成功。但是如何将这些方法应用在超大规模(web-scale)的数据上,比如数以十亿的商品和数亿的用户,还是一个有待解决的挑战。
本文提出了了GCN模型PinSage,应用在了Pinterest的推荐系统中。PinSage模型使用了随机游走和图卷积,捕获到了图结构的特征以及节点的特征,以生成节点的嵌入表示。
和先前的GCN方法不同,本文基于有效的随机游走来进行卷积,并设计了一个训练策略,依赖于越来越难训练的样本,以提高模型的鲁棒性并加快收敛。
在Pinterest的超大规模数据集上使用PinSage进行了实验,结果显示PinSage比其他推荐系统表现更好。
2 引言
(1)GCN简介
使用深度学习的方法在图结构的数据上进行建模,学习到节点的嵌入表示,可以应用于推荐系统等应用中。在这一领域中,受到关注最多的就是图卷积网络(GCNs)。
GCN的核心思想是使用神经网络,递归地从图的局部邻域聚合特征信息,用来表示中心节点。卷积操作指的就是从节点的一跳(one-hop)邻居节点转换并聚合特征信息,并通过堆叠多层卷积,聚合到来自多跳邻居的特征信息。
和基于内容的深层模型(例如RNN)不同,GCN不仅利用了内容信息还利用了图结构的信息。
(2)将基于GCN的模型应用于真实世界推荐系统的挑战
已经有许多使用基于GCN的模型进行推荐的研究,但是这些模型并没有在真实世界的应用中使用。
因为GCN在训练时需要使用整张图的信息,如果图的规模非常大,比如有数十亿的节点和边,或者图中的节点是动态变化的,基于GCN的模型就非常难扩展到这样的数据集上。
(3)作者提出
作者提出高度可扩展的基于随机游走的GCN框架PinSage,可处理有30亿节点和180亿条边的图,并成功应用于Pinterest的推荐系统中。
PinSage实现可扩展性的亮点列举如下:
1)On-the-fly convolutions
传统的GCN算法,通过将特征矩阵乘以整个图拉普拉斯矩阵的幂来实现图卷积。
本文的PinSage算法,通过采样节点的邻居并动态地从采样邻居构建计算图,实现了有效的局部的卷积。这些动态形成的计算图(如图1所示)说明了如何围绕一个节点进行局部的卷积,并且在训练时不需要在整张图上进行操作。
2)Producer-consumer minibatch construction
作者设计了一个producer-consumer架构用于构建minibatches,以保证在模型训练时最大程度利用GPU资源。
3)Effcient MapReduce inference
给定完全训练过的GCN模型,作者设计了有效的MapReduce pipeline分散训练过的模型,以为数以十亿的节点生成嵌入表示,同时最小化重复计算次数。
除了可扩展性之外,作者还引入了新的训练技巧和算法上的创新:
1)通过随机游走构建卷积
使用节点所有的邻居进行卷积操作会导致计算图过于庞大,因此作者使用了采样的方法。作者没有使用随机采样,而是使用随机游走采样得到计算图。还有一个好处就是,每个节点此时都有了一个重要性分值,在池化/聚合步骤将使用到这个分值。
2)重要性池化
图卷积的核心部分就是从图中的邻居节点聚合特征信息。作者基于随机游走的相似性度量,在聚合过程中为节点特征分配了重要性权重。实验结果显示,该方法提升了模型的性能。
3)课程训练(Curriculum training)
设计了类似课程学习(强化学习中的概念)的训练模式,即在训练过程中使用越来越难训练的样本,以提升模型最终的性能。
3 相关工作
本文设计的模型PinSage和GraphSAGE算法最相关。传统的GCNs不能进行推理式任务(inductive learning),GraphSAGE是对其的改进,可以应用在推理式任务。
PinSage和GraphSAGE的区别在于,GraphSAGE需要将整张图存储到GPU内存中,而PinSage不需要。
PinSage使用低延时的随机游走并以producer-consumer的架构采样邻居节点。作者还引入了新的训练技巧以提升模型性能,并且使用MapReduce实现模型的可扩展性。
需要注意的是,例如node2vec和DeepWalk等图嵌入方法不能应用到推荐系统中。原因有以下节点:1)这些方法是无监督的方法;2)它们不能包含节点特征的信息;3)它们直接学习节点的嵌入,因此模型的参数量和图的大小成线性关系,参数量太大。
4 方法
模型的关键思想在于局部图卷积的概念。为了生成节点的嵌入表示,作者使用多个卷积模块来从邻居节点聚合特征信息(例如视觉特征,文本特征),如图1所示。

并且,这些局部卷积模块中的参数在所有节点间是共享的,使得模型的参数复杂度独立于输入图的规模。
4.1 问题设置
(1)Pinterest介绍
Pinterest是一个内容发现的应用,用户可以和pins进行交互,pins指的是在线内容的可视书签,例如人们想做的食谱,或者想买的衣服。
用户将这些pins组成boards,boards包含用户认为和主题相关的pins的集合。
Pinterest图包含2 billion pins,1 billion boards和超过18 billion的边。
(2)明确任务
我们的任务就是为图中的pins生成高质量的嵌入表示,以用于推荐系统。为了学习到这些嵌入,作者将Pinterest图建模成二部图。二部图中的节点由pins的集合 I \mathcal{I} I和boards的集合 C \mathcal{C} C组成, I \mathcal{I} I可视为item的集合, C \mathcal{C} C可视为用户定义的contexts或collections。
处理图结构,作者还假设 I \mathcal{I} I中的pins/items有属性 x u ∈ R d x_u\in \mathbb{R}^d xu∈Rd。这些属性可能包含了items的元数据或内容信息。而对于Pinterest来说,pins具有丰富的文本特征和图像特征。我们的目标就是利用这些输入的属性信息以及二部图的结构信息,以生成高质量的节点嵌入,最终应用于推荐系统中。推荐系统的应用可体现在给定一个pin,找到与其相关的pins。
为了方便,当我们描述PinSage算法时,节点集合指的是整张图的节点 V = I ∪ C \mathcal{V} = \mathcal{I} \cup \mathcal{C} V=I∪C,并不区分pin节点和board节点,将其统称为节点。
4.2 模型架构
如图1所示,输入节点特征,使用局部卷积模块转换和聚合图中的特征,来生成节点的嵌入表示。
(1)前向传播算法
任务是根据节点 u u u自身的输入特征以及节点周围的图结构特征,生成节点 u u u的嵌入表示 z u z_u zu。

PinSage算法的核心是局部卷积操作,也就是如何聚合节点 u u u的邻居信息,算法1展示了具体流程。
接下来结合图1,我们逐行理解一下算法1。
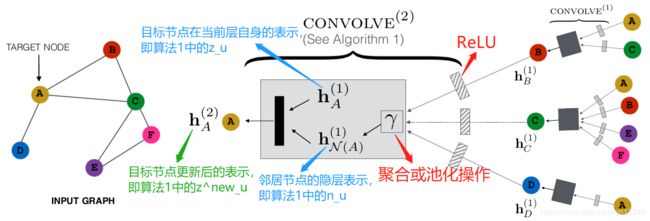
line 1表示对目标节点邻居信息的聚合,其中 h n \mathbf{h}_n hn为邻居节点的隐层表示, Q Q Q是转换矩阵, q \mathbf{q} q是偏置。经过矩阵变换后的邻居节点表示再经过非线性激活函数ReLU,然后使用权重 α \alpha α进行加权的聚合或者池化操作 γ \gamma γ,得到节点 u u u的邻居节点聚合后的表示 n u \mathbf{n}_u nu。
line 2表示目标节点表示的更新,将目标节点 u u u当前的表示 z u \mathbf{z}_u zu和聚合后的邻居节点表示 n u \mathbf{n}_u nu拼接起来,使用参数矩阵 W \mathbf{W} W进行转换并加上偏置 w \mathbf{w} w,然后经过ReLU非线性激活函数,就得到更新后的目标节点 u u u的表示 z u n e w \mathbf{z}^{new}_u zunew。
line 3表示归一化,使得训练过程更加稳定。
这样得到的节点表示就包含节点自身的信息以及其一阶邻居的信息,上述操作就是进行了一层卷积,堆叠多层的话节点表示中就可以得到多跳邻居的信息。
(2)基于重要性的邻居
本文方法的一个重要的创新就在于如何定义节点的邻居 N ( u ) \mathcal{N}(u) N(u),也就是如何选择出算法1中卷积时使用的邻居集合。
以往的GCN方法通过直接堆叠多层,使用k-hop的邻居节点信息。本文的PinSage定义了基于重要性的邻居节点,节点 u u u的邻居定义为对其影响最大的节点集合。
具体来说,我们从节点 u u u出发进行随机游走,并通过随机游走计算对节点访问次数的 L 1 L_1 L1归一化值。按照访问次数从大到小排序, u u u的邻居就定义为前 T T T个节点。
在无限次模拟的极限下,归一化的计数值近似于给定节点u的Personalized PageRank得分。
使用基于重要性的邻居有以下两方面的优点:
1)选择固定数量的邻居节点,聚合其信息,可以控制训练时的内存占用量;
2)使得算法1在聚合邻居信息时,考虑到了邻居的重要性。特别地,算法1中的 γ \gamma γ指的是weighted-mean操作,这里的权重就是由 L 1 L_1 L1归一化的访问次数所定义的[5]。我们将这一方法称为重要性池化(importance pooling)。
(3)卷积层的堆叠
每次进行卷积操作时,都得到节点的新表示,我们可以通过堆叠 k k k层卷积(如堆叠了两层卷积的图1),从节点 u u u的多跳邻居中得到更多的信息。其中,第0层的输入为节点特征。
需要注意的是,算法1中的所有模型参数( Q , q , W , w \mathbf{Q}, \mathbf{q}, \mathbf{W}, \mathbf{w} Q,q,W,w)在不同节点间共享,但是每层卷积之间不共享。
算法2展示了堆叠多层卷积,为minibatch M \mathcal{M} M中的节点生成嵌入的详细过程:

首先计算出每个节点的邻居节点,然后使用 K K K层卷积迭代得到目标节点在第 K K K层的表示。将最后一层卷积输出的节点表示输入到全连接的神经网络中,生成最终的节点表示 z u , ∀ u ∈ M \mathbf{z}_u, \forall u\in \mathcal{M} zu,∀u∈M。
需要学习的模型参数为:1)每一层卷积的权重和偏置,即 Q ( k ) , q ( k ) , W ( k ) , w ( k ) , ∀ k ∈ { 1 , . . . , K } \mathbf{Q}^{(k)}, \mathbf{q}^{(k)}, \mathbf{W}^{(k)}, \mathbf{w}^{(k)}, \forall k\in {\{1,..., K}\} Q(k),q(k),W(k),w(k),∀k∈{1,...,K};2)最后一层神经网络的参数 G 1 , G 2 , g G_1, G_2, g G1,G2,g。
4.3 模型的训练
使用max-margin ranking loss对PinSage进行有监督的训练。给定有标签的items对组成的集合 L \mathcal{L} L,训练的目标是优化PinSage的参数,使得输出的节点对嵌入 ( q , i ) ∈ L (q, i)\in \mathcal{L} (q,i)∈L互相之间更加相近。
接下来首先对margin-based损失函数进行介绍,然后介绍使用到的与PinSage的计算效率和收敛速度相关的技术,最后介绍提高了推荐系统整体质量的curriculum-training模式。
(1)损失函数
使用max-margin-based损失函数,基本思想是最大化正样本(query item和对应的相关联的item)嵌入间的内积。
同时,我们需要保证负样本(query item和不相关的item)嵌入间的内积小于正样本嵌入间的内积,并且差值尽量大于某一阈值。
对于节点嵌入对 ( z q , z i ) : ( q , i ) ∈ L (z_q, z_i):(q, i)\in \mathcal{L} (zq,zi):(q,i)∈L,损失计算如下:
其中 P n ( q ) P_n(q) Pn(q)表示item q q q的负样本的分布, Δ \Delta Δ表示超参数margin,也就是上述提到的阈值。
(2)使用minibatches进行多GPU的训练
为了在训练时充分利用单机上的多个GPU资源,我们以multi-tower的形式进行了正向传播和反向传播。
给定多个GPU,我们首先将每个minibatch(如图1底部所示)分成相等大小的部分(portions)。每个GPU处理minibatch中的一部分(one portion),然后使用相同的参数进行计算。
进行反向传播后,将多个GPU中每个参数的梯度聚合到一起,然后进行一次同步的(synchronous)SGD。
由于训练集的数据非常多,是十亿级别的,所以作者使用大的batch sizes(512~4096)。为了在处理大的batch sizes时,保证收敛的速度并维持训练和泛化的准确率,作者使用了和Goyal等人[1]提出的类似的技术。根据线性缩放规则(linear scaling rule),在第一个epoch中,作者将学习率从一个小的值增加到一个峰值,之后学习率呈指数下降。
(3)Producer-consumer minibatch的构建
在训练过程中,邻接列表和节点的特征矩阵由于占用空间太大,存储在了CPU中。然而PinSage在进行卷积时,每个GPU需要得到节点的邻居信息和邻居的特征信息。从GPU访问CPU中的数据,效率不高。
为了解决这一问题,作者使用了重索引(re-indexing)技术生成一个子图 G ′ = ( V ′ , E ′ ) G^{'}=(V^{'}, E^{'}) G′=(V′,E′)。子图中包含当前minibatch计算需要的节点和它们的邻居。还抽取出了只包含和当前minibatch相关的节点特征的 较小的特征矩阵,顺序和节点在 G ′ G^{'} G′中的索引一致。在每个minibatch迭代的起始时,将子图 G ′ G^{'} G′的邻接列表和特征矩阵喂给GPUs,这样就避免了在进行卷积时GPU和CPU间的交互,极大地提升了GPU的利用率。
训练过程交替使用CPUs和GPUs,模型的计算在GPUs中进行,特征的抽取、重索引和负采样在CPUs中进行。
使用multi-tower训练在GPU上进行并行计算,使用OpenMP[2]再CPU上进行计算。除此之外,作者还涉及了producer-consumer模式在当前迭代中运行GPU的计算,并且在下一次迭代中并行运行CPU计算。这种方式几乎缩短了一般的训练时间。
(4)采样负样本
1)初步思想
损失函数中使用到了负采样技术。为了提升使用大的batch sizes进行训练的有效性,作者采样了500个负样本,并在每个minibatch中的所有样本间共享。
与为每个节点独立地进行负采样的方法相比,本文的方法就减少了在训练过程中需要计算的嵌入的数量。并且,作者并没有发现这两种采样模式会带来性能上的差异。
最简单的方式是,在items的集合上进行均匀采样。但是这样的话,使得正样本嵌入间的内积大于负样本嵌入间的内积,未免有些太容易实现了,不能为系统提供更有效的学习信息。
为什么这么说呢?我们的推荐系统算法应该具有从2 billion个item中找到和item q q q最相关的1000个items节点的能力。换句话说,我们的模型应该能从2 million个item中识别出1个item。随机采样500个负样本,模型的分辨率只有1/500。因此,在2 billion个items中随机采样500个负样本,正好采样到和目标item轻微相关的item,这种概率是非常小的。只有选取到质量高的负样本,即和目标样本轻度相关(不是完全无关,也不是很相关)的样本,才能让正样本嵌入间的内积和负样本嵌入间的内积之差,尽可能地接近margin Δ \Delta Δ,这样才有助于损失函数的优化。
2)如何选取高质量的负样本
为了解决这一问题,对于训练样本中的每个正例 ( q , i ) (q, i) (q,i),作者为其添加“hard negative items”,也就是和query item q q q有某种关联,但关联没有和正样本 i i i那么强的样本。
这些样本是在给定query item q q q的条件下,根据它们的Personalized PageRank得分进行排序得到的。随机选择排在2000-5000的样本,作为hard negative items。

如图2所示,hard negative examples和随机采样的负样本相比,与query item更相似,这就有助于模型更好地学习,逼着模型学习到更细粒度的分辨知识。
(5)课程训练模式
在训练过程中使用hard negative items会加倍收敛所需的epoch数。为了有助于模型的收敛,作者提出和课程学习类似的训练模式(curriculum training scheme)[3]。在训练过程的第一个epoch中,不使用hard negative items,因此算法可以快速找到使得损失相对小的参数空间。在之后的epochs中添加hard negative items,使得模型聚焦于学习难以分别的样本。在第 n n n个epoch中,针对每个item,添加 n − 1 n-1 n−1个hard negative items。
4.4 Node Embeddings via MapReduce
训练好了模型之后,使用该模型为所有items(包括训练中未出现过的items,即inductive task)生成嵌入仍是一个挑战。
算法2中计算节点嵌入的方法,由于节点 K − h o p K-hop K−hop邻居间存在重叠现象,因此会导致重复的计算。如图1所示,在为不同的目标节点生成嵌入表示时,许多节点在多层中进行了重复的计算。
为了保证推断的有效性,作者使用MapReduce方法进行模型推断,避免了重复的计算。
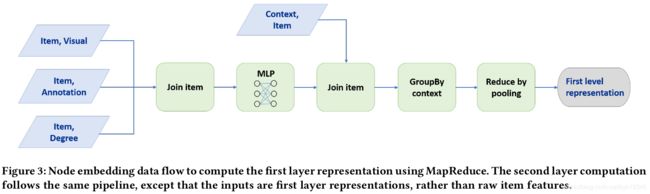
图3展示了在Pinterest pin-to-board的二部图上,数据流动的细节。其中,输入节点(layer-0)是pins/items,layer-1的节点是boards/contexts。MapReduce pipeline有两个关键组成部分:
1)MapReduce的job之一是将所有pins投影到低维的隐层空间,聚合操作将在此空间进行(算法1中的line 1)。
2)另一个MapReduce的job是联合pins的表示和它们出现在的boards的ids,对采样的邻居特征进行池化,以计算出board的嵌入表示。
值得注意的是,我们的方法避免了冗余计算,每个节点的隐层向量只计算1次。
在得到boards的嵌入之后,再使用2个MapReduce jobs来计算pins在第2层的嵌入表示,过程和上述类似。并且递归这一过程 K K K次, K K K表示卷积层数。
4.5 Effcient nearest-neighbor lookups
PinSage生成的嵌入可以广泛用于下游的推荐任务中。通过在学习得到的嵌入空间中进行nearest-neighbor lookups,我们可以直接使用这些嵌入来进行推荐。
也就是说,给定一个query item q q q,我们推荐的items,它们的嵌入是和query item的嵌入最相近的 K K K个邻居(K-nearest neighbors)。
通过局部敏感哈希可以有效地获得近似KNN。在计算哈希函数之后,使用基于Weak AND operator[4]的two-level检索过程,进行items的检索。给定的PinSage模型是离线训练的,所有的节点嵌入是通过MapReduce计算得到的,并存入了数据库中。有效的最近邻邻居lookup操作(nearest-neighbor
lookup operation)使得系统可以在线提供推荐服务。
5 实验
5.1 数据集
5.2 实验任务
在Pinterest图上进行了离线实验和A/B测试。
基于两个任务评估PinSage生成的嵌入表示的质量:
1)推荐相关的pins,选择和query pin在嵌入空间中距离最近的K个邻居;
2)在用户的home/news feed中推荐pins,为用户推荐和其近期已选择的pins最接近的pins。
5.3 使用的特征
Pinterest中的每个pin都和一个图片和一组文本信息(例如标题, 描述)相关。为了给每个pin q q q生成特征表示 x q x_q xq,作者将visual embeddings,textual annotation embeddings和节点度的对数拼接起来。
其中visual embeddings是使用VGG-16得到的,textual annotation embedding是使用基于Word2Vec的模型得到的。
5.4 对比方法
将PinSage和state-of-the-art的生成pins嵌入表示的基于内容的方法、基于图的方法和深度学习的baselines进行对比:
-
Visual embeddings:使用visual embeddings最接近的邻居作为推荐;
-
Annotation embeddings:推荐annotation embeddings最接近的邻居;
-
Combined embeddings:基于拼接后的visual和annotation embeddings做推荐,并使用2层感知机计算嵌入,以捕获到visual和annotation的特征;
-
Graph-based method:使用有偏的随机游走,以query pin q q q作为起始节点模拟随机游走,生成排序分数。分值在前 K K K的items作为推荐。
visual和annotation embeddings是目前应用于Pinterest以生成pins嵌入表示的state-of-the-art方法。由于可扩展性的问题,我们不和其他的深度学习baseline方法进行比较。
作者还考虑了一些PinSage的变形,以用于消融实验:
-
max-pooling:使用element-wise max作为聚合函数( γ = m a x \gamma = max γ=max),不使用hard negative samples;
-
mean-pooling:使用element-wise mean作为聚合函数, γ = m e a n \gamma=mean γ=mean;
-
mean-pooling -xent:和mean-pooling一样,但是使用交叉熵损失函数;
-
mean-pooling-hard:和mean-pooling一样,区别在于使用了hard negative examples;
-
PinSage:使用文章中提到的所有的最优方法,包括卷积步骤中的importance pooling。
5.5 Offline Evaluation
(1)hit-rate和MRR度量
为了评估和pin相关的推荐任务,作者定义了hit-rate。
对于测试集中的每个pins 对 ( q , i ) (q, i) (q,i),将 q q q作为query pin并从5 million个测试样本中计算top K个最相近的邻居节点 N N q NN_q NNq。定义hit-rate为 i i i在 N N q NN_q NNq所占的比例。
此外,还使用了Mean Reciprocal Rank(MRR)的可扩展版本作为度量,如下式所示。其中 R i , q R_{i,q} Ri,q表示对给定的query q q q进行推荐,items i i i在这些推荐里的排名; n n n是有标签的item对的总数。缩放数值100保证了排名数值较大时,也能有明显的差距。例如排名1000和2000,除以100后分母变成10和20,还是有较明显的差距的。但如果不除以100,则1000和2000都会导致分数接近于0,差别不明显。
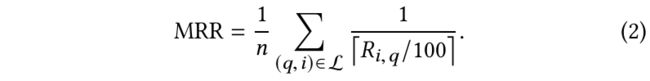
表1比较了不同方法使用hit-rate和MRR两种度量的结果。

(2)嵌入相似度分布
item对嵌入间距离的分布,也证明了模型学习到的嵌入有很好的表示能力。如果所有item嵌入的距离较为集中,也就是这些距离紧密地聚在一起,则说明嵌入空间没有足够的分辨率来分辨出有不同关联的items。
图4展示了使用不同的嵌入方法,items对间余弦相似度的分布。从图中可以看出PinSage模型的有效性,它对应的分布和其他方法相比是最均匀的。

这样的wide-spread的嵌入还有一个优点:减少了后续 LSH算法(敏感哈希)发生碰撞的概率,从而提高了推荐最相近邻居pins的效率。
5.6 User Studies
在用户实验中,给一个用户提供query pin的image和使用两个不同的推荐算法得到的2个pins。让用户从这两个候选的pins中选取和query pin更相关的pin。要求用户在视觉外观、对象类别和个人喜好等方面,找到推荐项和query项间的各种关联。
如果两个推荐项看起来是同等相关的,用户可以选择“equal”。如果2/3的用户对同一个问题的评价没有达成一致,则认为结果是不确定的。表2展示PinSage和其他4种baselines对比的实验结果:
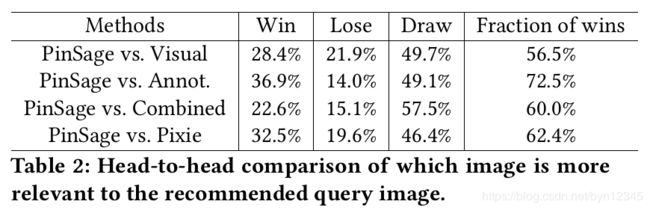
图5给出了一个推荐的例子,并展示了不同方法的优势和不足:

随机选取1000个items,使用PinSage计算它们的嵌入,并计算其二维的t-SNE坐标,结果如图6所示。可以看出item嵌入的距离和内容的相似度相对应,并且属于同一类别的items被嵌入到了空间中的相同部分。另外,在视觉上看起来不同但有着同一主题的items,在嵌入空间中距离也较近。

5.7 运行时间
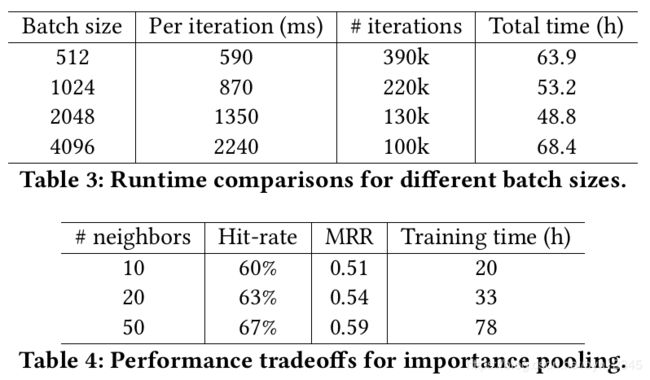
6 总结
传统的GCN方法在训练时需要整张图的信息,难以扩展到web-scale的数据集上,本文针对这一问题提出了PinSage模型。
本文在GraphSAGE的基础上提出基于随机游走的图卷积神经网络(GCN)PinSage,用于为web-scale(十亿级别)的图结构节点数据生成嵌入表示,以用于下游任务,并且成功应用到了Pinterest的推荐系统中。
PinSage的亮点在于引入局部卷积、重要性池化(importance pooling)和课程训练方法(curriculum training),极大地提高了嵌入表示的质量。
本文的工作证明了基于图卷积网络的方法可以在工业界的推荐系统中落地应用。
未来工作:将PinSage应用到更多的大规模的图表示相关的任务中,例如知识图谱推理、图聚类。
PinSage的创新点在于:局部卷积、重要性池化、负采样机制、课程训练。
(1)局部卷积
为了处理超大规模的数据,作者提出了局部卷积的方法。和之前的GCN方法相比,作者对邻居的定义有所不同。从中心节点出发进行随机游走,按照访问次数对访问到的节点排序,选取前 T T T个节点定义为中心节点的邻居。针对所有节点的邻居节点特征信息进行聚合,也就是进行了一层局部卷积。
(2)重要性池化
在聚合时还使用了importance pooling的方法,根据不同的邻居节点对中心节点的重要性,对其分配不同的权重。其中,权重是根据随机游走节点的访问次数计算的。
(3)负采样机制
为了选取到对模型学习有帮助的高质量的负样本,作者提出根据给定的query item,计算推荐项的Personalized PageRank得分,并按照得分对其排序,随机选择排在2000-5000的样本,作为hard negative items。
(4)课程训练模式
hard negative samples的引入,减缓了训练模型时收敛的速度。因此作者提出了课程训练(curriculum training)模式:在第一个epoch时不引入hard negative samples,在之后的epoch引入hard negative smaples,使得模型聚焦于难以训练的样本,从而加快模型的收敛速度。
本文的工作是开创性的,第一个将基于图卷积神经网络的模型成功应用于工业界。
参考文献
[1] P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He. 2017. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv preprint arXiv:1706.02677 (2017).
[2] OpenMP Architecture Review Board. 2015. OpenMP Application Program Interface Version 4.5. (2015).
[3] Y. Bengio, J. Louradour, R. Collobert, and J. Weston. 2009. Curriculum learning. In ICML.
[4] A. Z. Broder, D. Carmel, M. Herscovici, A. Soffer, and J. Zien. 2003. Effcient
query evaluation using a two-level retrieval process. In CIKM.
[5] C. Eksombatchai, P. Jindal, J. Z. Liu, Y. Liu, R. Sharma, C. Sugnet, M. Ulrich, and J. Leskovec. 2018. Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time. WWW (2018).