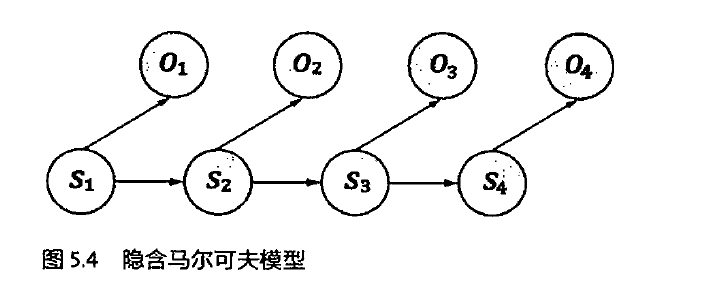
隐马模型
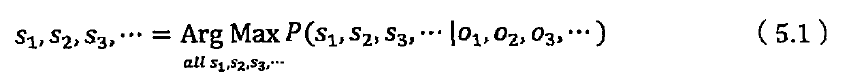
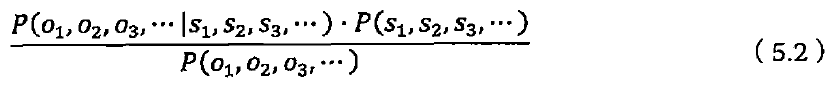
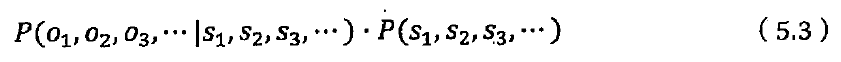
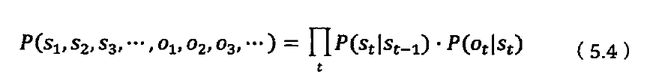
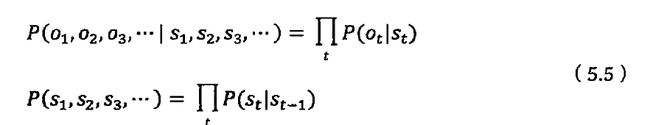
维特比算法
import codecs
import re
import numpy as np
stateNum = 4 #begin middle end single 四个状态
obsNum = 3717
def train():
A = np.zeros((stateNum, stateNum))
B = np.zeros((stateNum, obsNum))
E = np.mat(np.zeros((1, stateNum)))
tempB = np.zeros((obsNum, stateNum), dtype=int)
all_chars = []
train_corpus = "train_corpus"
# train_corpus = "train_corpus_small"
lines = codecs.open(train_corpus, encoding='utf-8').readlines()
head_b_num = head_s_num = 0 #统计先验概率或者初始概率的
bm = be = mm = me = eb = es = sb = ss = 0#处理转移概率的
cnt = 0
for line in lines:
cnt += 1
# print('sentence %d' % cnt)
state_seq = ''
line = line.strip()
words_list = re.split('[,:;"\'?!、,:;。“”‘’?!()()<>〈〉《》\[\]【】 ]+', line)
while '' in words_list:
words_list.remove('')
# print(line, words_list)
if len(words_list) > 0:
head = words_list[0]
if len(head) == 1: head_s_num += 1
else: head_b_num += 1
for word in words_list:
if len(word) == 1:
char = word
if char not in all_chars:
all_chars.append(char)
ind = all_chars.index(char)
tempB[ind][3] += 1
state_seq += 'S'
else:
beg_char = word[0]
state_seq += 'B'
if beg_char not in all_chars:
all_chars.append(beg_char)
ind = all_chars.index(beg_char)
tempB[ind][0] += 1
for i in range(1, len(word) - 1):
char = word[i]
if char not in all_chars:
all_chars.append(char)
ind = all_chars.index(char)
tempB[ind][1] += 1
state_seq += 'M'
end_char = word[-1]
state_seq += 'E'
if end_char not in all_chars:
all_chars.append(end_char)
ind = all_chars.index(end_char)
tempB[ind][2] += 1
bm, be, mm, me, eb, es, sb, ss = bm+state_seq.count('BM'),be+state_seq.count('BE'),mm+state_seq.count('MM'),me+state_seq.count('ME'),eb+state_seq.count('EB'),es+state_seq.count('ES'),sb+state_seq.count('SB'),ss+state_seq.count('SS'),
# print(state_seq, [bm, be, mm, me, eb, es, sb, ss])
print('共%d个字' % len(all_chars))
# print([bm, be, mm, me, eb, es, sb, ss])
E[0,0], E[0,3] = float(head_b_num)/(head_s_num+head_b_num), float(head_s_num)/(head_s_num+head_b_num)
A[0][1],A[0][2],A[1][1],A[1][2],A[2][0],A[2][3],A[3][0],A[3][3] = float(bm)/(bm+be), float(be)/(bm+be), float(mm)/(mm+me), float(me)/(mm+me), float(eb)/(eb+es), float(es)/(eb+es), float(sb)/(sb+ss), float(ss)/(sb+ss)
for i in range(stateNum):
column_sum = tempB.sum(axis=0) # obsNum*stateNum矩阵列求和结果为1*stateNum
for j in range(obsNum):
B[i,j] = float(tempB[j,i])/column_sum[i]
# print(tempB, B)
f = open('HMM-model\chars', 'a+')
f.write('\n'.join(all_chars))
np.savetxt('HMM-model\prob_start', E)
np.savetxt('HMM-model\prob_trans', A)
np.savetxt('HMM-model\prob_emit', B)
np.savetxt('HMM-model\prob_B', tempB, fmt='%d')
# f = open('HMM-model\small\chars', 'a+')
# f.write('\n'.join(all_chars))
# np.savetxt('HMM-model\small\prob_start', E)
# np.savetxt('HMM-model\small\prob_trans', A)
# np.savetxt('HMM-model\small\prob_emit', B)
# np.savetxt('HMM-model\small\prob_B', tempB, fmt='%d')
print('done')
'''
delta矩阵记录概率
psi矩阵记录路径
A B 记录转移和和发射概率的矩阵
'''
def viterbi(obs_seq):
E = np.loadtxt('prob_start')
A = np.loadtxt('prob_trans')
B = np.loadtxt('prob_emit')
f = open('chars').read()
# E = np.loadtxt('HMM-model\small\prob_start')
# A = np.loadtxt('HMM-model\small\prob_trans')
# B = np.loadtxt('HMM-model\small\prob_emit')
# f = open('HMM-model\small\chars').read()
E = np.mat(E)
all_chars = f.split('\n')
while '' in all_chars:
all_chars.remove('')#加载字典
# print(len(all_chars))
# print(E.shape, A.shape, B.shape)
obs_seq = re.sub(' ', '', obs_seq)#观测到的值 待切分
L = len(obs_seq)
if L == 0: return
Delta = np.zeros((L, stateNum)) #10*4
l = [-1] * L * stateNum #10*4 长度的list
Psi = np.mat(l).reshape(L, stateNum) #10*4的matrix 都是-1 # np.matrix(Delta-1)也行
beg_char = obs_seq[0]
ind = all_chars.index(beg_char) # 通过字典索引第一个字
Delta[0,:] = np.multiply(E, B[:,ind].T)#先验概率乘发射概率
for t in range(1, L):
ind = all_chars.index(obs_seq[t])
for i in range(stateNum):
temp = np.multiply(Delta[t-1,:], A[:,i].T)#上一层最大概率乘以本层转移概率 (1,4)*(1,4)
Delta[t,i] = np.max(temp) * B[i, ind]#上一层最大概率乘以本层转移概率乘以本层发射概率 找极大值,更新至本层最大概率
if Delta[t,i] > 0:
Psi[t,i] = np.argmax(temp) #存储本层最优路径
print('temp: ', temp)
print(np.max(temp), B[i, ind], A[:, i].T)
print(np.argmax(temp), Delta[t,i])
print(Psi)
print(Delta)
print(Psi)
print('最优路径的概率为:', np.max(Delta[L-1, :]))
t = L-1
i = np.argmax(Delta[t, :])
state_seq = str(i)
i = Psi[t,i]
state_seq += str(i)
while(t > 1):
t -= 1
i = Psi[t,i]
state_seq += str(i)
state_seq = state_seq[::-1]
print('最优路径为:', state_seq)
seg_seq = ''
for i in range(L):
char = obs_seq[i]
if state_seq[i] == '0': seg_seq += ' ' + char
elif state_seq[i] == '2': seg_seq += char + ' '
elif state_seq[i] == '3': seg_seq += ' ' + char + ' '
else: seg_seq += char
return seg_seq
# train()
obs_seq = '新华社驻英国记者报道'
print('分词结果: ', viterbi(obs_seq))