Oracle使用sqluldr2
分三部分:
1 . sqluldr2简介与使用
2 . sqlldr的使用,常见异常
3 . 测试使用
1 . sqluldr2简介与使用
sqluldr2是一款Oracle数据快速导出工具,包含32、64位程序,sqluldr2在大数据量导出方面速度超快,能导出亿级数据为excel文件,另外它的导入速度也是非常快速,功能是将数据以TXT/CSV等格式导出。
sqluldr2下载地址:http://www.pc6.com/softview/SoftView_516318.html
sqluldr2百度文库参考:https://wenku.baidu.com/view/ffd7e60400f69e3143323968011ca300a7c3f614
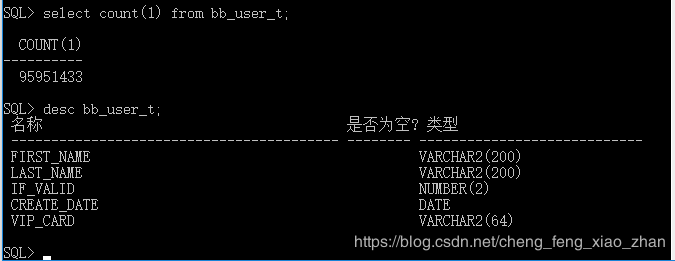
基本简介
下载完sqluldr解压后,文件夹内容如下:
sqluldr2.exe 用于32位windows平台;
sqluldr2_linux32_10204.bin 适用于linux32位操作系统;
sqluldr2_linux64_10204.bin 适用于linux64位操作系统;
sqluldr264.exe 用于64位windows平台。
使用方法
1、首先将sqluldr2.exe复制到执行目录下,即可开始使用
2、查看help 帮助

3、执行数据导出命令
3.1、常规导出
sqluldr2 hr/[email protected]:1521/XE query="select * from bb_user_t" head=yes file=D:\sqluldr2\File\tmp001.csv
说明:head=yes 表示输出表头

3.2、使用sql参数
sqluldr2 hr/[email protected]:1521/XE sql=query.sql head=yes file=D:\sqluldr2\File\tmp002.csv或
sqluldr2 hr/[email protected]:1521/XE sql=D:\sqluldr2\query.sql head=yes file=D:\sqluldr2\File\tmp002.csv
query.sql的内容为:
select * from bb_user_t
3.3、使用log参数
当集成sqluldr2在脚本中时,就希望屏蔽上不输出这些信息,但又希望这些信息能保留,这时可以用“LOG”选项来指定日志文件名。
sqluldr2 hr/[email protected]:1521/XE sql=D:\sqluldr2\query.sql head=yes file=D:\sqluldr2\File\tmp003.csv log=+D:\sqluldr2\File\tmp003.log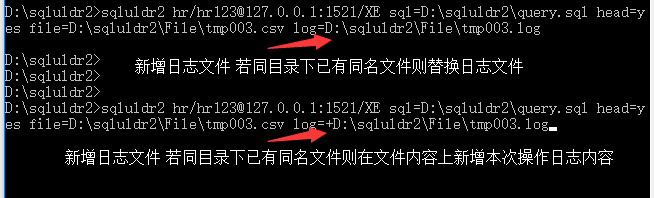
3.4、使用 table 参数
(“TABLE”选项用于指定将文件导入的目标表的名字,例如我们将EMP 表的数据导入到EMP_HIS 表中,假设这两个表的表结构一致,先用如下命令导出数据:
Sqluldr2 … query=”select * from emp” file=emp.txt table=emp_his ……)
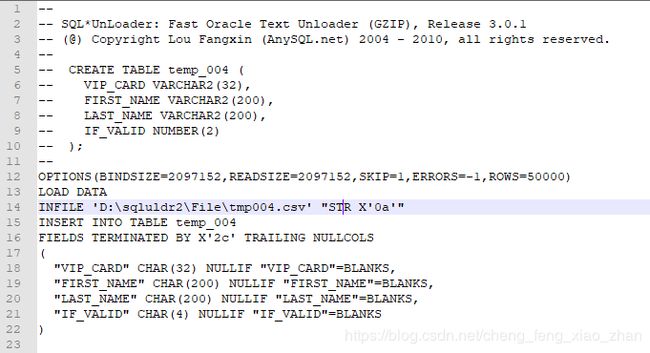
当使用 table 参数时,在目录下会生成对应的ctl控制文件,如下语句会生成temp_004_sqlldr.ctl文件。
sqluldr2 hr/[email protected]:1521/XE query="select * from bb_user_t" table=temp_004 head=yes file=D:\sqluldr2\File\tmp004.csv可以指定文件地址(不建议,指定文件地址情况重新导入数据库时需要手动修改生成的D:\sqluldr2\File\temp_004_sqlldr.ctl文件中“INTO TABLE D:\sqluldr2\File\temp_004”为表名“INTO TABLE temp_004”):
sqluldr2 hr/[email protected]:1521/XE query="select * from bb_user_t" table=D:\sqluldr2\File\temp_004 head=yes file=D:\sqluldr2\File\tmp004.csv(不建议使用)

生成的控制文件temp_004_sqlldr.ctl的内容如下:
3.4、大数据量操作
对于大表可以输出到多个文件中,指定行数分割或者按照文件大小分割,例如:
sqluldr2 hr/[email protected]:1521/XE query="select * from bb_user_t" table=temp_001 mode=APPEND head=yes file=D:\sqluldr2\temp_001_%B.csv batch=yes rows=500000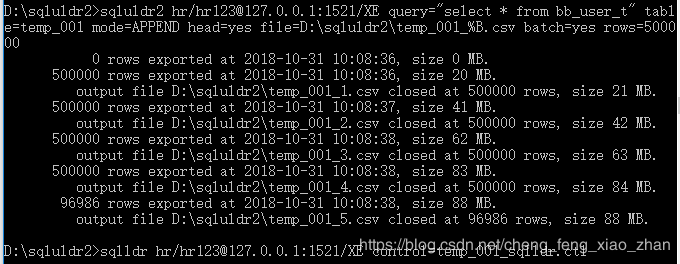

当文件名(“FILE”选项)的后缀以小写的“.gz”结尾时,会将记录直接写入到GZIP格式的压缩文件中,如果要归档大量数据,这个功能可以节约很多的存贮空间,降低运营成本。
sqluldr2 hr/[email protected]:1521/XE query="select * from bb_user_t" table=temp_001 mode=APPEND head=yes file=D:\sqluldr2\temp_001.txt.gz
1 兆大小的文件,以GZIP 压缩方式生成时,大小才90KB,如果用于归档历史数据,的确可以节约不少空间,GZIP 目前是性价比非常好的压缩方式之一。
参数说明:
user = username/password@tnsname
sql = SQL file name
query = select statement (选择语句;query参数如果整表导出,可以直接写表名,如果需要查询运算和where条件,query=“sql文本”,也可以把复杂sql写入到文本中由query调用)
field = separator string between fields (
设置导出文件里的分隔符;
默认是逗号分隔符,通过 field参数指定分隔符;
例如现在要改变默认的字段分隔符,用“#”来分隔记录,导出的命令如下所示:
sqluldr2 test/test sql=tmp.sql field=#
在指定分隔符时,可以用字符的ASCII代码(0xXX,大写的XX为16进制的ASCII码值)来指定一个字符,常用的字符的ASCII代码如下:
回车=0x0d,换行=0x0a,TAB键=0x09,|=0x7c,&=0x26,双引号=0x22,单引号=0x27
在选择分隔符时,一定不能选择会在字段值中出现的字符)
record = separator string between records (记录之间的分隔字符串;分隔符 指定记录分隔符,默认为回车换行,Windows下的换行)
rows = print progress for every given rows (default, 1000000)
file = output file name(default: uldrdata.txt) (输出文件名(默认:uldrdata.txt))
log = log file name, prefix with + to append mode (日志文件名,前缀加+模式)
fast = auto tuning the session level parameters(YES)
text = output type (MYSQL, CSV, MYSQLINS, ORACLEINS, FORM, SEARCH).
charset = character set name of the target database. (目标数据库的字符集名称;导出文件里有中文显示乱码,需要设置参数charset=UTF8)
ncharset= national character set name of the target database.
parfile = read command option from parameter file (从参数文件读取命令选项;可以把参数放到parfile文件里,这个参数对于复杂sql很有用)
read = set DB_FILE_MULTIBLOCK_READ_COUNT at session level
sort = set SORT_AREA_SIZE at session level (UNIT:MB)
hash = set HASH_AREA_SIZE at session level (UNIT:MB)
array = array fetch size
head = print row header(Yes|No)
batch = save to new file for every rows batch (Yes/No) (为每行批处理保存新文件)
size = maximum output file piece size (UNIB:MB)
serial = set _serial_direct_read to TRUE at session level
trace = set event 10046 to given level at session level
table = table name in the sqlldr control file (“TABLE”选项用于指定将文件导入的目标表的名字,例如我们将EMP 表的数据导入到EMP_HIS 表中,假设这两个表的表结构一致,先用如下命令导出数据:
Sqluldr2 … query=”select * from emp” file=emp.txt table=emp_his ……)
control = sqlldr control file and path.
mode = sqlldr option, INSERT or APPEND or REPLACE or TRUNCATE
buffer = sqlldr READSIZE and BINDSIZE, default 16 (MB)
long = maximum long field size
width = customized max column width (w1:w2:...)
quote = optional quote string (可选引用字符串;引号符 指定非数字字段前后的引号符)
data = disable real data unload (NO, OFF)
alter = alter session SQLs to be execute before unload
safe = use large buffer to avoid ORA-24345 error (Yes|No) (使用大缓冲器避免ORA-24345错误;ORA-24345: A Truncation or null fetch error occurred,设置参数safe=yes)
crypt = encrypted user information only (Yes|No)
sedf/t = enable character translation function
null = replace null with given value
escape = escape character for special characters
escf/t = escape from/to characters list
format = MYSQL: MySQL Insert SQLs, SQL: Insert SQLs.
exec = the command to execute the SQLs.
prehead = column name prefix for head line.
rowpre = row prefix string for each line.
rowsuf = row sufix string for each line.
colsep = separator string between column name and value.
presql = SQL or scripts to be executed before data unload.
postsql = SQL or scripts to be executed after data unload.
lob = extract lob values to single file (FILE).
lobdir = subdirectory count to store lob files .
split = table name for automatically parallelization.
degree = parallelize data copy degree (2-128).
for field and record, you can use '0x' to specify hex character code,
\r=0x0d \n=0x0a |=0x7c ,=0x2c, \t=0x09, :=0x3a, #=0x23, "=0x22 '=0x27
--附赠一个小例子:每个数值以#间隔,每行数据以0x0d0x0a间隔
sqluldr2 hr/[email protected]:1521/XE query="select vip_card from bb_user_t" table=temp_001 mode=APPEND record=0x0d0x0a field=# head=yes file=D:\sqluldr2\temp_001.txt2 . sqlldr的使用,常见异常
安装ORACLE客户端中有SQLLDR命令
我的sqlldr位置:C:\oraclexe\app\oracle\product\10.2.0\server\BIN\sqlldr.exe
注:导入数据字段,表中必须包含(>=)导入数据中字段;
导入数据时我遇到的问题:
异常1:SQL*Loader-522: 文件(temp_004_sqlldr.log)的lfiopn失败
异常2:SQL*Loader-350: 语法错误位于第 15 行。
异常3:SQL*Loader-601: 对于 INSERT 选项, 表必须为空。表 BB_USER_T 上出错
异常4:SQL*Loader-941: 在描述表 BB_USER_T_1 时出错
异常1:

SQL*Loader-522: 文件(temp_004_sqlldr.log)的lfiopn失败
原因可能两种
1.路径和文件名 不正确或不存在
2.权限不足
我是因为权限不足,
解决:将C:\oraclexe\app\oracle\product\10.2.0\server\BIN\sqlldr.exe的sqlldr.exe粘贴到temp_004_sqlldr.ctl文件的目录下,继续执行;
异常2:

SQL*Loader-350: 语法错误位于第 15 行。
预期值是 "(", 而实际值是 ":"。
INSERT INTO TABLE D:\sqluldr2\File\temp_004
原因:导出时的table参数的设置(table=D:\sqluldr2\File\temp_004)不正确,应设置为导入数据的表名
解决:重新导出table设为要导入数据的表名
异常3:
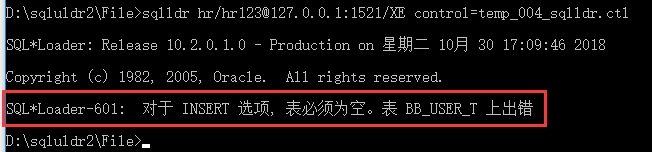
SQL*Loader-601: 对于 INSERT 选项, 表必须为空。表 BB_USER_T 上出错
原因:导出数据库数据时若不设定sqlldr 装载数据时的装载方式,则默认为INSERT
解决:若需要在其它表中新增数据用如下类似语句:
sqluldr2 hr/[email protected]:1521/XE query="select * from bb_user_t" table=BB_USER_T mode=APPEND head=yes file=D:\sqluldr2\temp_001.csv异常4:
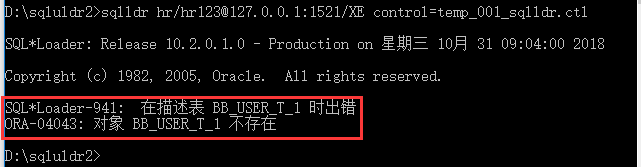
SQL*Loader-941: 在描述表 BB_USER_T_1 时出错
ORA-04043: 对象 BB_USER_T_1 不存在
原因:提示出错,因为数据库没有对应的表。
解决:修改“sqlldr hr/[email protected]:1521/XE control=temp_001_sqlldr.ctl”语句文件“temp_001_sqlldr.ctl”中BB_USER_T_1为正确表名
3 . 测试使用
测试操作:
操作一》导出数据
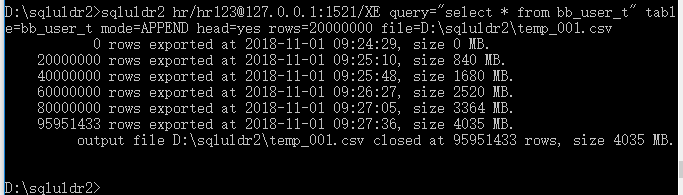
进行导出数据操作:95951433条数据导出时间不到4分钟
操作二》导入数据
sqlldr hr/[email protected]:1521/XE control=bb_user_t_sqlldr.ctl log=bb_user_t_sqlloader.logbb_user_t_sqlloader.log内容如下:
SQL*Loader: Release 10.2.0.1.0 - Production on 星期四 11月 1 10:07:29 2018
Copyright (c) 1982, 2005, Oracle. All rights reserved.
控制文件: bb_user_t_sqlldr.ctl
数据文件: D:\sqluldr2\temp_001.csv
文件处理选项字符串: "STR X'0a'"
错误文件: temp_001.bad
废弃文件: 未作指定
(可废弃所有记录)
要加载的数: ALL
要跳过的数: 1
允许的错误: ALL
绑定数组: 50000 行, 最大 2097152 字节
继续: 未作指定
所用路径: 常规
表 BB_USER_T,已加载从每个逻辑记录
插入选项对此表 APPEND 生效
TRAILING NULLCOLS 选项生效
列名 位置 长度 中止 包装数据类型
------------------------------ ---------- ----- ---- ---- ---------------------
"FIRST_NAME" FIRST 200 , CHARACTER
NULL if "FIRST_NAME" = BLANKS
"LAST_NAME" NEXT 200 , CHARACTER
NULL if "LAST_NAME" = BLANKS
"IF_VALID" NEXT 4 , CHARACTER
NULL if "IF_VALID" = BLANKS
"CREATE_DATE" NEXT * , DATE YYYY-MM-DD HH24:MI:SS
NULL if "CREATE_DATE" = BLANKS
"VIP_CARD" NEXT 64 , CHARACTER
NULL if "VIP_CARD" = BLANKS
ROWS 参数所用的值已从 50000 更改为 2857
表 BB_USER_T:
95951433 行 加载成功。
由于数据错误, 0 行 没有加载。
由于所有 WHEN 子句失败, 0 行 没有加载。
由于所有字段都为空的, 0 行 没有加载。
为绑定数组分配的空间: 2097038 字节 (2857 行)
读取 缓冲区字节数: 2097152
跳过的逻辑记录总数: 1
读取的逻辑记录总数: 95951433
拒绝的逻辑记录总数: 0
废弃的逻辑记录总数: 0
从 星期四 11月 01 10:07:29 2018 开始运行
在 星期四 11月 01 10:32:10 2018 处运行结束
经过时间为: 00: 24: 41.28
CPU 时间为: 00: 04: 16.48经过时间为: 00: 24: 41.28
操作三》优化导入数据
提高 SQL*Loader 的性能
1) 一个简单而容易忽略的问题是,没有对导入的表使用任何索引和/或约束(主键)。如果这样做,甚至在使用ROWS=参数时,会很明显降低数据库导入性能。
2) 可以添加 DIRECT=TRUE来提高导入数据的性能。当然,在很多情况下,不能使用此参数。 常规导入可以通过使用 INSERT语句来导入数据。Direct导入可以跳过数据库的相关逻辑(DIRECT=TRUE),而直接将数据导入到数据文件中,可以提高导入数据的 性能。当然,在很多情况下,不能使用此参数(如果主键重复的话会使索引的状态变成UNUSABLE!)。
3) 通过指定 UNRECOVERABLE选项,可以关闭数据库的日志。这个选项只能和 direct 一起使用。
4) 可以同时运行多个导入任务。
sqlldr userid=/ control=result1.ctl direct=true parallel=true
当加载大量数据时(大约超过10GB),最好抑制日志的产生:
SQL>ALTER TABLE bb_user_t nologging;
(SQL> ALTER TABLE bb_user_t logging;)
这样不产生REDO LOG,可以提高效率。然后在 CONTROL 文件中 load data 上面加一行:unrecoverable, 此选项必须要与DIRECT共同应用。
导入任务
在导入数据时,我的是简化版,一直报错误
ORA-12952: 请求超出了允许的最大数据库大小 4 GB
我重新导出了一次约90000000万条数据;
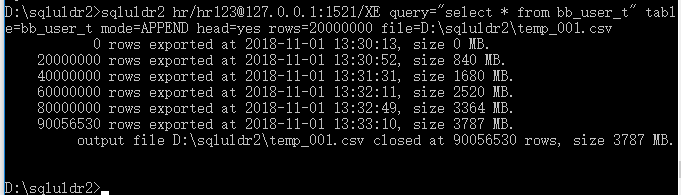
生成的bb_user_t_sqlldr.ctl文件
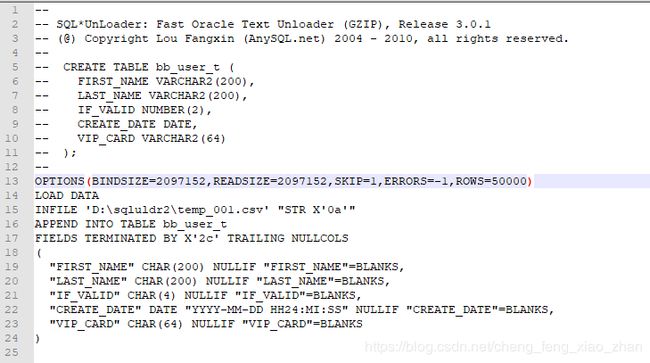
对bb_user_t_sqlldr.ctl文件修改
执行导入数据库
sqlldr hr/[email protected]:1521/XE control=bb_user_t_sqlldr.ctl log=bb_user_t_sqlloader.log DIRECT=TRUE parallel=true

bb_user_t_sqlloader.log内容:
SQL*Loader: Release 10.2.0.1.0 - Production on 星期四 11月 1 13:58:49 2018
Copyright (c) 1982, 2005, Oracle. All rights reserved.
控制文件: bb_user_t_sqlldr.ctl
数据文件: D:\sqluldr2\temp_001.csv
文件处理选项字符串: "STR X'0a'"
错误文件: temp_001.bad
废弃文件: 未作指定
(可废弃所有记录)
要加载的数: ALL
要跳过的数: 1
允许的错误: ALL
继续: 未作指定
所用路径: 直接- 具有并行选项。
加载是 UNRECOVERABLE;产生无效的恢复操作。
表 BB_USER_T,已加载从每个逻辑记录
插入选项对此表 APPEND 生效
TRAILING NULLCOLS 选项生效
列名 位置 长度 中止 包装数据类型
------------------------------ ---------- ----- ---- ---- ---------------------
"FIRST_NAME" FIRST 200 , CHARACTER
NULL if "FIRST_NAME" = BLANKS
"LAST_NAME" NEXT 200 , CHARACTER
NULL if "LAST_NAME" = BLANKS
"IF_VALID" NEXT 4 , CHARACTER
NULL if "IF_VALID" = BLANKS
"CREATE_DATE" NEXT * , DATE YYYY-MM-DD HH24:MI:SS
NULL if "CREATE_DATE" = BLANKS
"VIP_CARD" NEXT 64 , CHARACTER
NULL if "VIP_CARD" = BLANKS
表 BB_USER_T:
90056530 行 加载成功。
由于数据错误, 0 行 没有加载。
由于所有 WHEN 子句失败, 0 行 没有加载。
由于所有字段都为空的, 0 行 没有加载。
日期高速缓存:
最大大小: 1000
条目数: 2
命中数 : 90056528
未命中数 : 0
在直接路径中没有使用绑定数组大小。
列数组 行数: 5000
流缓冲区字节数: 256000
读取 缓冲区字节数: 2097152
跳过的逻辑记录总数: 1
读取的逻辑记录总数: 90056530
拒绝的逻辑记录总数: 0
废弃的逻辑记录总数: 0
由 SQL*Loader 主线程加载的流缓冲区总数: 18936
由 SQL*Loader 加载线程加载的流缓冲区总数: 0
从 星期四 11月 01 13:58:49 2018 开始运行
在 星期四 11月 01 14:01:49 2018 处运行结束
经过时间为: 00: 02: 59.57
CPU 时间为: 00: 02: 14.21导入时间不到3分钟。
导入数据时的其它问题:
发现无法导入数据,从查询日志如下:
记录 1: 被拒绝 - 表 BB_USER_T 出现错误。
ORA-12952: 请求超出了允许的最大数据库大小 4 GB
解决方法:因为ORACLE 10g Express是简化版,它具有一定的局限性,它的所有数据文件大小不能超过4G,内存使用不能超过1G,CPU只能使用1个。所以应该把它卸了,重新安装完整版的oracle软件。
希望对你有帮助,祝你有一个好心情,加油!
若有错误、不全、可优化的点,欢迎纠正与补充;转载请注明出处!